Hydra: Virtualized Multi-Language Runtime for High-Density Serverless Platforms

0
✅
Sign in to get full access
Overview
- Serverless computing offers benefits like seamless scalability and pay-as-you-use billing, but existing platforms suffer from high memory and latency overheads due to bloated virtualization stacks.
- The paper proposes a virtualized multi-language serverless runtime called Hydra to reduce the virtualization stack bloat.
- The authors also build a serverless platform that optimizes scheduling decisions to take advantage of Hydra, further improving efficiency.
Plain English Explanation
Serverless computing is an attractive model that takes the burden of managing infrastructure away from users. It allows applications to automatically scale up or down as needed, and users only pay for the resources they use. This makes it well-suited for workloads that have unpredictable or "bursty" usage patterns.
However, the current serverless platforms are built on top of heavyweight virtualization systems, which can lead to high memory usage and slower response times, especially for the type of bursty workloads that serverless is designed for.
To address this, the researchers developed a new serverless runtime called Hydra. Hydra is designed to be more efficient by using a lighter-weight virtualization approach. It can also run functions written in multiple programming languages on the same platform, unlike existing runtimes which are typically limited to a single language.
In addition, the researchers built a serverless platform that works alongside Hydra to optimize scheduling decisions. This further improves efficiency by consolidating multiple function invocations onto the same server instance, reducing the overall overhead.
The end result is a serverless system that can run functions more densely (i.e., more operations per unit of memory) compared to existing platforms, while also reducing the number of "cold starts" (where a new server instance has to be created to handle a function invocation). This makes the serverless experience faster and more cost-effective for users.
Technical Explanation
The core of the researchers' work is the Hydra serverless runtime, which uses a virtualized multi-language approach to reduce the overhead of the underlying virtualization stack. Hydra can run functions written in different programming languages (e.g., Node.js, Java, Python) on the same platform, unlike existing runtimes which are typically limited to a single language.
To further optimize performance, the researchers also developed a serverless platform that works in conjunction with Hydra. This platform makes intelligent scheduling decisions to consolidate multiple function invocations onto the same server instance, reducing the overall infrastructure overhead.
In their experiments, the researchers found that Hydra improves the overall "function density" (operations per GB-second) by 4.47x on average compared to using the individual language runtimes (Node.js, Java, Python) in isolation. When reproducing a trace of real-world function invocations from the Azure Functions platform, Hydra reduced the overall memory footprint by 2.1x and reduced the number of "cold starts" (where a new server instance has to be created) by 4 to 48 times.
Critical Analysis
The research presented in this paper offers a promising approach to improving the efficiency of serverless computing platforms. By reducing the virtualization overhead and enabling multi-language support, Hydra addresses key limitations of existing serverless runtimes.
However, the paper does not explore some potential caveats and limitations of the Hydra approach. For example, it's not clear how well Hydra would scale to handle extremely large or complex function workloads, or how it would perform in scenarios with very high concurrency demands.
Additionally, the paper focuses mainly on the technical aspects of Hydra's architecture and performance, but does not delve into potential security or reliability implications of the multi-language runtime. These are important considerations for serverless platforms, which are often used to run mission-critical applications.
Overall, the research presented in this paper is a valuable contribution to the field of serverless computing. By tackling the inefficiencies of the virtualization stack, the Hydra runtime and the accompanying scheduling optimizations represent an important step forward. However, further research is needed to fully understand the real-world implications and potential limitations of this approach.
Conclusion
The paper proposes a novel serverless runtime called Hydra that addresses the high memory and latency overheads of existing serverless platforms. By using a lightweight virtualization approach and supporting multiple programming languages, Hydra can run functions more efficiently and with fewer "cold starts."
The researchers also developed a complementary serverless platform that optimizes scheduling decisions to further improve the benefits of Hydra. Their experiments show significant improvements in function density and reductions in memory usage and cold starts compared to current serverless runtimes.
This work represents an important advancement in the field of serverless computing, making the technology more viable for a wider range of workloads and use cases. As serverless platforms continue to evolve and legacy systems adopt serverless, innovations like Hydra will play a crucial role in improving the scalability, cost-effectiveness, and overall user experience of serverless computing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
0
Hydra: Virtualized Multi-Language Runtime for High-Density Serverless Platforms
Serhii Ivanenko, Jovan Stevanovic, Vojin Jovanovic, Rodrigo Bruno
Serverless is an attractive computing model that offers seamless scalability and elasticity; it takes the infrastructure management burden away from users and enables a pay-as-you-use billing model. As a result, serverless is becoming increasingly popular to support highly elastic and bursty workloads. However, existing platforms are supported by bloated virtualization stacks which, combined with bursty and irregular invocations, leads to high memory and latency overheads. To reduce the virtualization stack bloat, we propose Hydra, a virtualized multi-language serverless runtime capable of handling multiple invocations of functions written in different languages. To measure its impact in large platforms, we build a serverless platform that optimizes scheduling decisions to take advantage of Hydra by consolidating function invocations on a single instance, reducing the total infrastructure tax. Hydra improves the overall function density (ops/GB-sec) by 4.47$times$ on average compared NodeJS, JVM, and CPython, the state-of-art single-language runtimes used in most serverless platforms. When reproducing the Azure Functions trace, Hydra reduces the overall memory footprint by 2.1 $times$ and reduces the number of cold starts between 4 and 48 $times$.
Read more6/21/2024
0
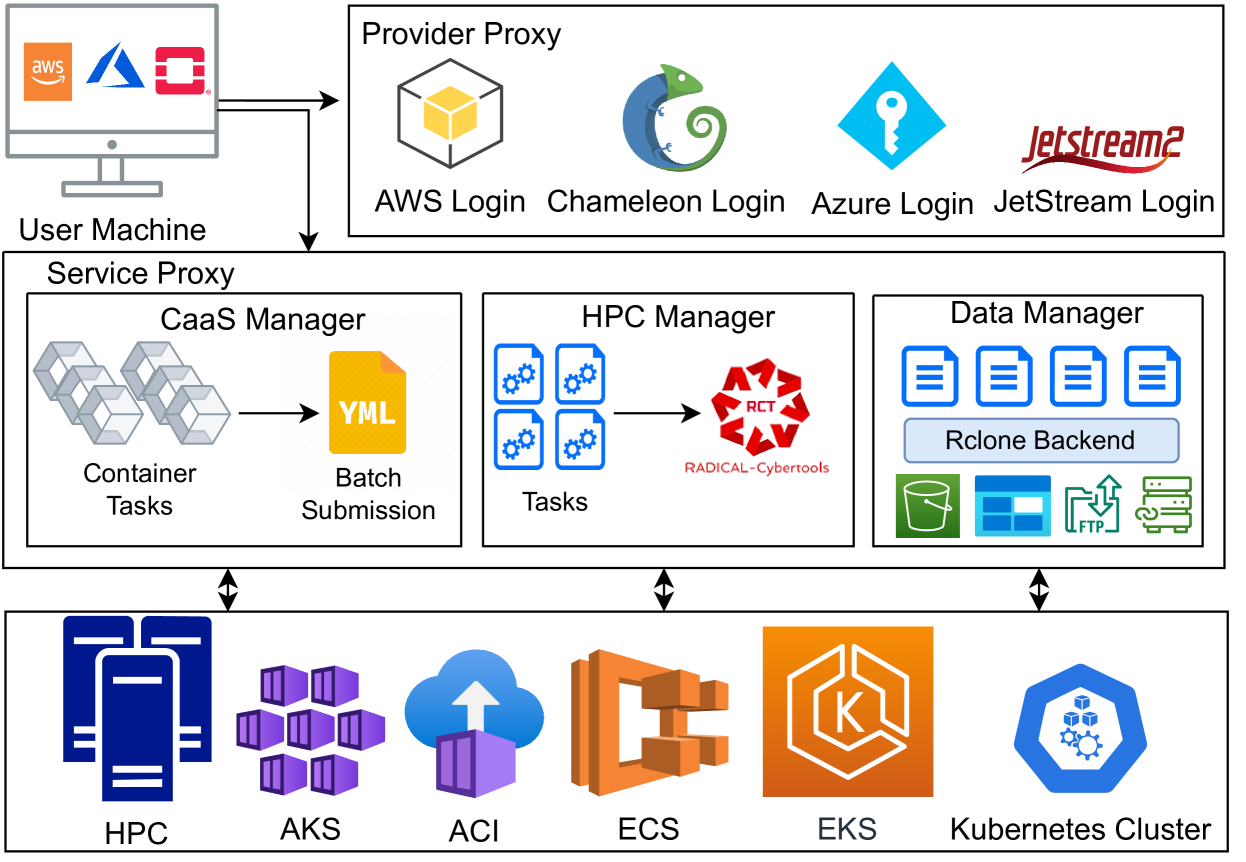
Hydra: Brokering Cloud and HPC Resources to Support the Execution of Heterogeneous Workloads at Scale
Aymen Alsaadi, Shantenu Jha, Matteo Turilli
Scientific discovery increasingly depends on middleware that enables the execution of heterogeneous workflows on heterogeneous platforms One of the main challenges is to design software components that integrate within the existing ecosystem to enable scale and performance across cloud and high-performance computing HPC platforms Researchers are met with a varied computing landscape which includes services available on commercial cloud platforms data and network capabilities specifically designed for scientific discovery on government-sponsored cloud platforms and scale and performance on HPC platforms We present Hydra an intra cross-cloud HPC brokering system capable of concurrently acquiring resources from commercial private cloud and HPC platforms and managing the execution of heterogeneous workflow applications on those resources This paper offers four main contributions (1) the design of brokering capabilities in the presence of task platform resource and middleware heterogeneity; (2) a reference implementation of that design with Hydra; (3) an experimental characterization of Hydra s overheads and strong weak scaling with heterogeneous workloads and platforms and, (4) the implementation of a workflow that models sea rise with Hydra and its scaling on cloud and HPC platforms
Read more7/17/2024
👨🏫
0
Zenix: Efficient Execution of Bulky Serverless Applications
Zhiyuan Guo, Zachary Blanco, Junda Chen, Jinmou Li, Zerui Wei, Bili Dong, Ishaan Pota, Mohammad Shahrad, Harry Xu, Yiying Zhang
Serverless computing, commonly offered as Function-as-a-Service, was initially designed for small, lean applications. However, there has been an increasing desire to run larger, more complex applications (what we call bulky applications) in a serverless manner. Existing strategies for enabling such applications are to either increase function sizes or to rewrite applications as DAGs of functions. These approaches cause significant resource wastage, manual efforts, and/or performance overhead. We argue that the root cause of these issues is today's function-centric serverless model, where a function is the resource allocation and scaling unit. We propose a new, resource-centric serverless-computing model for executing bulky applications in a resource- and performance-efficient way, and we build the Zenix serverless platform following this model. Our results show that Zenix reduces resource consumption by up to 90% compared to today's function-centric serverless systems, while improving performance by up to 64%.
Read more5/14/2024
📈
0
Imaginary Machines: A Serverless Model for Cloud Applications
Michael Wawrzoniak, Rodrigo Bruno, Ana Klimovic, Gustavo Alonso
Serverless Function-as-a-Service (FaaS) platforms provide applications with resources that are highly elastic, quick to instantiate, accounted at fine granularity, and without the need for explicit runtime resource orchestration. This combination of the core properties underpins the success and popularity of the serverless FaaS paradigm. However, these benefits are not available to most cloud applications because they are designed for networked virtual machines/containers environments. Since such cloud applications cannot take advantage of the highly elastic resources of serverless and require run-time orchestration systems to operate, they suffer from lower resource utilization, additional management complexity, and costs relative to their FaaS serverless counterparts. We propose Imaginary Machines, a new serverless model for cloud applications. This model (1.) exposes the highly elastic resources of serverless platforms as the traditional network-of-hosts model that cloud applications expect, and (2.) it eliminates the need for explicit run-time orchestration by transparently managing application resources based on signals generated during cloud application executions. With the Imaginary Machines model, unmodified cloud applications become serverless applications. While still based on the network-of-host model, they benefit from the highly elastic resources and do not require runtime orchestration, just like their specialized serverless FaaS counterparts, promising increased resource utilization while reducing management costs.
Read more7/2/2024