Hydra: Brokering Cloud and HPC Resources to Support the Execution of Heterogeneous Workloads at Scale

0
Sign in to get full access
Overview
- Hydra is a system that brokers cloud and high-performance computing (HPC) resources to support the execution of diverse workloads at scale.
- It provides a unified interface for users to access heterogeneous computing resources, allowing them to run a wide range of applications on the most suitable platforms.
- Hydra optimizes resource allocation and utilization, ensuring efficient and cost-effective use of cloud and HPC infrastructure.
Plain English Explanation
Hydra is a system that helps manage and utilize different types of computing resources, such as cloud services and high-performance computers, to run a variety of software applications. It acts as a middleman, or broker, between the users and the available computing resources, making it easier for users to access and use the resources they need.
The key idea behind Hydra is to provide a single, unified interface for users to access and use these diverse computing resources. Instead of having to learn how to use each cloud service or HPC system separately, users can simply submit their tasks to Hydra, and it will handle the details of where and how to run them, ensuring that the tasks are executed efficiently and cost-effectively.
Hydra also optimizes the way these computing resources are used, making sure they are not being wasted or used inefficiently. This helps organizations and researchers save money and get more work done with the resources they have available.
Technical Explanation
Hydra is designed to broker cloud and HPC resources to support the execution of heterogeneous workloads at scale. It provides a unified interface for users to access and utilize these diverse computing resources, allowing them to run a wide range of applications on the most suitable platforms.
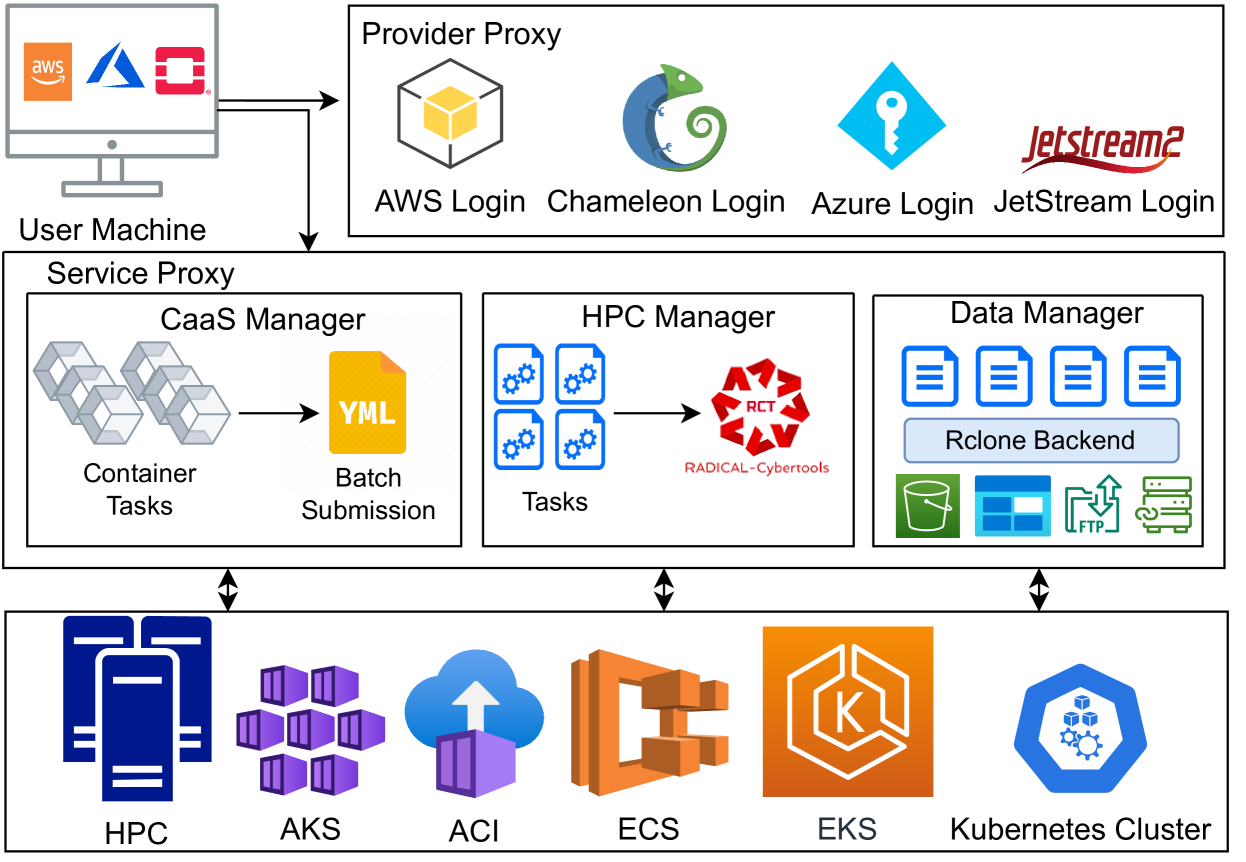
The key components of Hydra's architecture include:
- Resource Manager: Responsible for discovering, monitoring, and allocating computing resources from cloud and HPC providers.
- Workload Scheduler: Matches user workloads to the most appropriate computing resources based on a variety of factors, such as cost, performance, and resource availability.
- Execution Engine: Handles the actual execution of user tasks on the provisioned computing resources, providing monitoring and fault-tolerance capabilities.
Hydra employs various optimization techniques to ensure efficient and cost-effective use of the underlying infrastructure. This includes dynamic resource scaling, intelligent workload placement, and adaptive scheduling algorithms that take into account factors like workload characteristics, resource utilization, and pricing models.
Critical Analysis
The Hydra system addresses an important challenge in modern computing environments, where users need to access and utilize a diverse range of computing resources, including cloud services and HPC systems. By providing a unified interface and optimization mechanisms, Hydra can help organizations and researchers run their applications more efficiently and cost-effectively.
However, the paper does not discuss the potential challenges and limitations of Hydra. For example, it does not address issues related to data security and privacy when using public cloud resources, or the potential vendor lock-in that could arise from relying on a specific set of cloud and HPC providers.
Additionally, the paper lacks a comprehensive evaluation of Hydra's performance and scalability, especially when dealing with large-scale, complex workloads. Further research and experimentation would be needed to assess the system's effectiveness in real-world scenarios and its ability to adapt to changing resource availability and user demands.
Conclusion
Hydra is a promising system that aims to simplify the management and utilization of diverse computing resources, including cloud services and HPC systems. By providing a unified interface and optimizing resource allocation, Hydra can help organizations and researchers run their applications more efficiently and cost-effectively.
While the research presented in the paper is a step in the right direction, further investigation is needed to address potential limitations and challenges, as well as to thoroughly evaluate the system's performance and scalability in real-world scenarios. As computing environments continue to evolve and become more complex, systems like Hydra will likely play an increasingly important role in enabling efficient and effective use of available resources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hydra: Brokering Cloud and HPC Resources to Support the Execution of Heterogeneous Workloads at Scale
Aymen Alsaadi, Shantenu Jha, Matteo Turilli
Scientific discovery increasingly depends on middleware that enables the execution of heterogeneous workflows on heterogeneous platforms One of the main challenges is to design software components that integrate within the existing ecosystem to enable scale and performance across cloud and high-performance computing HPC platforms Researchers are met with a varied computing landscape which includes services available on commercial cloud platforms data and network capabilities specifically designed for scientific discovery on government-sponsored cloud platforms and scale and performance on HPC platforms We present Hydra an intra cross-cloud HPC brokering system capable of concurrently acquiring resources from commercial private cloud and HPC platforms and managing the execution of heterogeneous workflow applications on those resources This paper offers four main contributions (1) the design of brokering capabilities in the presence of task platform resource and middleware heterogeneity; (2) a reference implementation of that design with Hydra; (3) an experimental characterization of Hydra s overheads and strong weak scaling with heterogeneous workloads and platforms and, (4) the implementation of a workflow that models sea rise with Hydra and its scaling on cloud and HPC platforms
Read more7/17/2024

0
Running Cloud-native Workloads on HPC with High-Performance Kubernetes
Antony Chazapis, Evangelos Maliaroudakis, Fotis Nikolaidis, Manolis Marazakis, Angelos Bilas
The escalating complexity of applications and services encourages a shift towards higher-level data processing pipelines that integrate both Cloud-native and HPC steps into the same workflow. Cloud providers and HPC centers typically provide both execution platforms on separate resources. In this paper we explore a more practical design that enables running unmodified Cloud-native workloads directly on the main HPC cluster, avoiding resource partitioning and retaining the HPC center's existing job management and accounting policies.
Read more9/26/2024

0
HPC Alongside User-space Kubernetes
Vanessa Sochat, David Fox, Daniel Milroy
High performance computing (HPC) and cloud have traditionally been separate, and presented in an adversarial light. The conflict arises from disparate beginnings that led to two drastically different cultures, incentive structures, and communities that are now in direct competition with one another for resources, talent, and speed of innovation. With the emergence of converged computing, a new paradigm of computing has entered the space that advocates for bringing together the best of both worlds from a technological and cultural standpoint. This movement has emerged due to economic and practical needs. Emerging heterogeneous, complex scientific workloads that require an orchestration of services, simulation, and reaction to state can no longer be served by traditional HPC paradigms. However, while cloud offers automation, portability, and orchestration, as it stands now it cannot deliver the network performance, fine-grained resource mapping, or scalability that these same simulations require. These novel requirements call for change not just in workflow software or design, but also in the underlying infrastructure to support them. This is one of the goals of converged computing. While the future of traditional HPC and commercial cloud cannot be entirely known, a reasonable approach to take is one that focuses on new models of convergence, and a collaborative mindset. In this paper, we introduce a new paradigm for compute -- a traditional HPC workload manager, Flux Framework, running seamlessly with a user-space Kubernetes Usernetes to bring a service-oriented, modular, and portable architecture directly to on-premises HPC clusters. We present experiments that assess HPC application performance and networking between the environments, and provide a reproducible setup for the larger community to do exactly that.
Read more6/12/2024
✅
0
Hydra: Virtualized Multi-Language Runtime for High-Density Serverless Platforms
Serhii Ivanenko, Jovan Stevanovic, Vojin Jovanovic, Rodrigo Bruno
Serverless is an attractive computing model that offers seamless scalability and elasticity; it takes the infrastructure management burden away from users and enables a pay-as-you-use billing model. As a result, serverless is becoming increasingly popular to support highly elastic and bursty workloads. However, existing platforms are supported by bloated virtualization stacks which, combined with bursty and irregular invocations, leads to high memory and latency overheads. To reduce the virtualization stack bloat, we propose Hydra, a virtualized multi-language serverless runtime capable of handling multiple invocations of functions written in different languages. To measure its impact in large platforms, we build a serverless platform that optimizes scheduling decisions to take advantage of Hydra by consolidating function invocations on a single instance, reducing the total infrastructure tax. Hydra improves the overall function density (ops/GB-sec) by 4.47$times$ on average compared NodeJS, JVM, and CPython, the state-of-art single-language runtimes used in most serverless platforms. When reproducing the Azure Functions trace, Hydra reduces the overall memory footprint by 2.1 $times$ and reduces the number of cold starts between 4 and 48 $times$.
Read more6/21/2024