Hyper-parameter Tuning for Adversarially Robust Models

0
📈
Sign in to get full access
Overview
- This paper explores the challenges and opportunities in hyperparameter tuning (HPT) for robust, adversarially trained machine learning models.
- The researchers conducted an extensive experimental study on 3 popular deep learning models, exploring 9 hyperparameters, 2 fidelity dimensions, and 2 attack bounds, resulting in 19,208 configurations.
- The study reveals that the HPT process is more complex for robust models, as different hyperparameters need to be tuned for standard and adversarial training.
- However, the researchers also identify opportunities to reduce the cost of HPT for robust models by leveraging cheap adversarial training methods to estimate the performance of state-of-the-art approaches.
Plain English Explanation
Hyperparameter tuning is the process of optimizing the settings of a machine learning model to improve its performance. When a model is trained to be robust against adversarial attacks (where small, imperceptible changes to the input can cause the model to make incorrect predictions), this tuning process becomes more complex.
The researchers in this paper wanted to understand the new challenges and opportunities that arise when tuning hyperparameters for robust models. They conducted a very extensive set of experiments, trying out different hyperparameter settings, attack strengths, and training approaches on 3 popular deep learning models.
The key finding is that for robust models, the hyperparameters used during standard training and adversarial training need to be tuned separately. This can lead to significant improvements in the model's performance on both clean and adversarial inputs. However, this also makes the tuning process more complicated and time-consuming.
On the other hand, the researchers also discovered a way to speed up the tuning process. They found that by using cheaper, but still effective, methods to estimate the model's performance under adversarial attacks, they could get a good idea of the model's quality without having to run the full, expensive adversarial training. This insight, combined with a recent optimization technique, allowed them to reduce the overall cost of tuning hyperparameters for robust models by up to 2.1 times.
Technical Explanation
The paper conducts an extensive experimental study to understand the challenges and opportunities in hyperparameter tuning (HPT) for robust, adversarially trained models. The researchers explore 9 discretized hyperparameters, 2 fidelity dimensions, and 2 attack bounds, resulting in a total of 19,208 configurations (corresponding to 50,000 GPU hours).
The key findings are:
- The complexity of the HPT problem is further exacerbated in adversarial settings, as the hyperparameters used during standard and adversarial training need to be tuned independently. Succeeding in doing so can lead to a reduction of up to 80% and 43% of the error for clean and adversarial inputs, respectively.
- There are new opportunities to reduce the cost of HPT for robust models. The researchers propose to leverage cheap adversarial training methods to obtain inexpensive, yet highly correlated, estimations of the quality achievable using state-of-the-art methods. By exploiting this idea in conjunction with a recent multi-fidelity optimizer (taKG), the efficiency of the HPT process can be enhanced by up to 2.1x.
Critical Analysis
The paper provides a comprehensive and rigorous exploration of the HPT problem for robust, adversarially trained models. The extensive experimental study, covering a wide range of hyperparameters, fidelity dimensions, and attack bounds, offers valuable insights into the challenges and opportunities in this domain.
One potential limitation is the use of discretized hyperparameters, which may miss some of the nuances of the HPT problem. It would be interesting to see the impact of using continuous hyperparameters, as discussed in related work such as Parameter-Efficient Fine-Tuning of Large Models for Comprehensive.
Additionally, the paper does not delve into the potential impact of different model architectures or dataset characteristics on the HPT process for robust models. Further research in this direction could provide a more comprehensive understanding of the problem.
The proposed approach of leveraging cheap adversarial training methods to estimate the performance of state-of-the-art methods is a promising direction, but its effectiveness may depend on the specific models and tasks. It would be valuable to explore the generalizability of this technique across a broader range of scenarios.
Conclusion
This paper makes significant contributions to our understanding of the hyperparameter tuning problem for robust, adversarially trained models. The key insights are:
- The HPT process for robust models is more complex, as the hyperparameters used during standard and adversarial training need to be tuned independently.
- Successful tuning of these separate hyperparameters can lead to substantial improvements in model performance on both clean and adversarial inputs.
- There are opportunities to reduce the cost of HPT for robust models by leveraging cheap adversarial training methods to estimate the performance of state-of-the-art approaches, coupled with efficient optimization techniques.
These findings have important implications for the development of more robust and reliable machine learning systems, which are essential for many real-world applications. The insights and techniques presented in this paper can help researchers and practitioners navigate the challenges and opportunities in this critical area of machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
Hyper-parameter Tuning for Adversarially Robust Models
Pedro Mendes, Paolo Romano, David Garlan
This work focuses on the problem of hyper-parameter tuning (HPT) for robust (i.e., adversarially trained) models, shedding light on the new challenges and opportunities arising during the HPT process for robust models. To this end, we conduct an extensive experimental study based on 3 popular deep models, in which we explore exhaustively 9 (discretized) HPs, 2 fidelity dimensions, and 2 attack bounds, for a total of 19208 configurations (corresponding to 50 thousand GPU hours). Through this study, we show that the complexity of the HPT problem is further exacerbated in adversarial settings due to the need to independently tune the HPs used during standard and adversarial training: succeeding in doing so (i.e., adopting different HP settings in both phases) can lead to a reduction of up to 80% and 43% of the error for clean and adversarial inputs, respectively. On the other hand, we also identify new opportunities to reduce the cost of HPT for robust models. Specifically, we propose to leverage cheap adversarial training methods to obtain inexpensive, yet highly correlated, estimations of the quality achievable using state-of-the-art methods. We show that, by exploiting this novel idea in conjunction with a recent multi-fidelity optimizer (taKG), the efficiency of the HPT process can be enhanced by up to 2.1x.
Read more6/14/2024
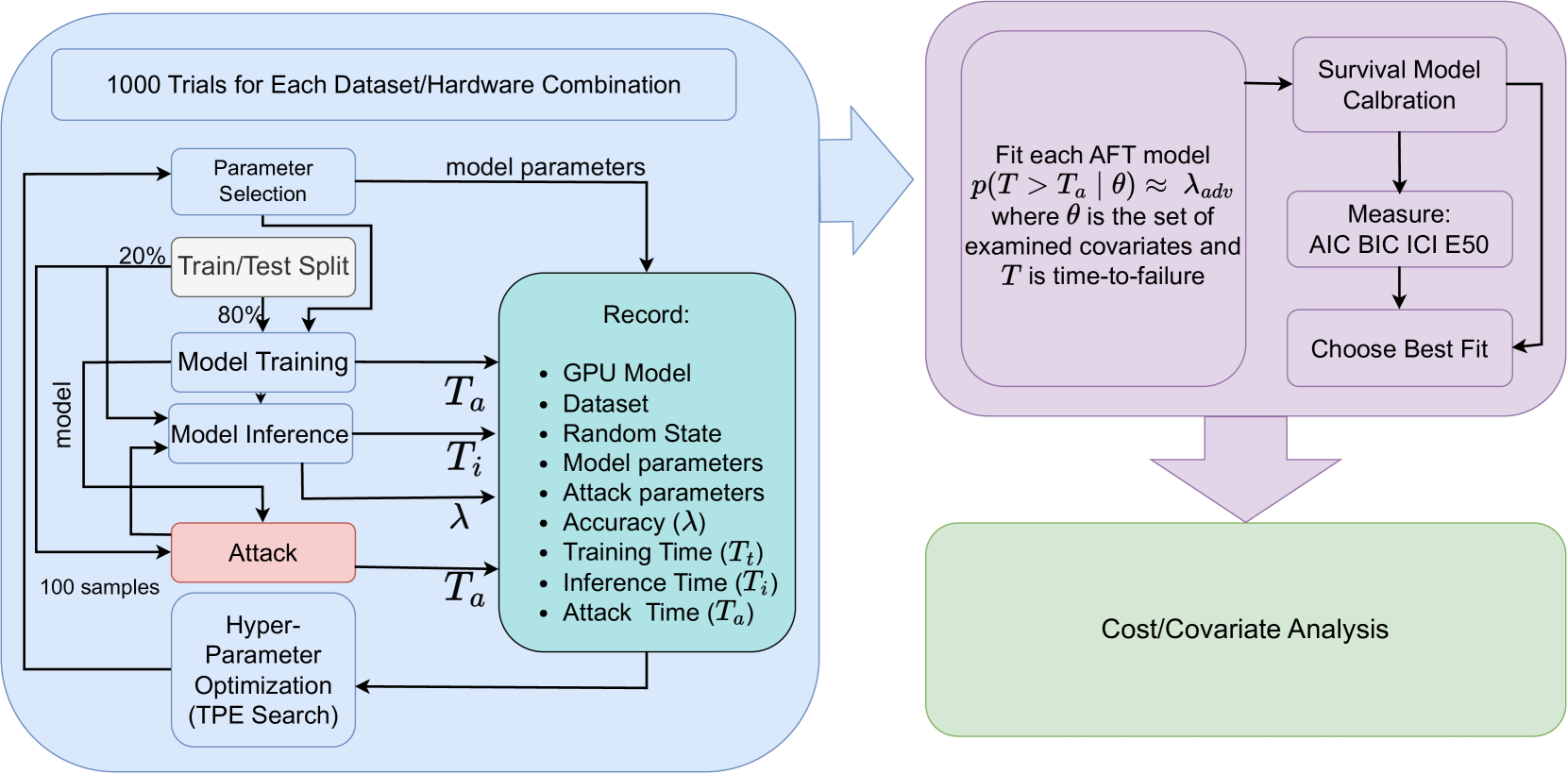
0
A Cost-Aware Approach to Adversarial Robustness in Neural Networks
Charles Meyers, Mohammad Reza Saleh Sedghpour, Tommy Lofstedt, Erik Elmroth
Considering the growing prominence of production-level AI and the threat of adversarial attacks that can evade a model at run-time, evaluating the robustness of models to these evasion attacks is of critical importance. Additionally, testing model changes likely means deploying the models to (e.g. a car or a medical imaging device), or a drone to see how it affects performance, making un-tested changes a public problem that reduces development speed, increases cost of development, and makes it difficult (if not impossible) to parse cause from effect. In this work, we used survival analysis as a cloud-native, time-efficient and precise method for predicting model performance in the presence of adversarial noise. For neural networks in particular, the relationships between the learning rate, batch size, training time, convergence time, and deployment cost are highly complex, so researchers generally rely on benchmark datasets to assess the ability of a model to generalize beyond the training data. To address this, we propose using accelerated failure time models to measure the effect of hardware choice, batch size, number of epochs, and test-set accuracy by using adversarial attacks to induce failures on a reference model architecture before deploying the model to the real world. We evaluate several GPU types and use the Tree Parzen Estimator to maximize model robustness and minimize model run-time simultaneously. This provides a way to evaluate the model and optimise it in a single step, while simultaneously allowing us to model the effect of model parameters on training time, prediction time, and accuracy. Using this technique, we demonstrate that newer, more-powerful hardware does decrease the training time, but with a monetary and power cost that far outpaces the marginal gains in accuracy.
Read more9/14/2024

0
Enhancing Adversarial Attacks via Parameter Adaptive Adversarial Attack
Zhibo Jin, Jiayu Zhang, Zhiyu Zhu, Chenyu Zhang, Jiahao Huang, Jianlong Zhou, Fang Chen
In recent times, the swift evolution of adversarial attacks has captured widespread attention, particularly concerning their transferability and other performance attributes. These techniques are primarily executed at the sample level, frequently overlooking the intrinsic parameters of models. Such neglect suggests that the perturbations introduced in adversarial samples might have the potential for further reduction. Given the essence of adversarial attacks is to impair model integrity with minimal noise on original samples, exploring avenues to maximize the utility of such perturbations is imperative. Against this backdrop, we have delved into the complexities of adversarial attack algorithms, dissecting the adversarial process into two critical phases: the Directional Supervision Process (DSP) and the Directional Optimization Process (DOP). While DSP determines the direction of updates based on the current samples and model parameters, it has been observed that existing model parameters may not always be conducive to adversarial attacks. The impact of models on adversarial efficacy is often overlooked in current research, leading to the neglect of DSP. We propose that under certain conditions, fine-tuning model parameters can significantly enhance the quality of DSP. For the first time, we propose that under certain conditions, fine-tuning model parameters can significantly improve the quality of the DSP. We provide, for the first time, rigorous mathematical definitions and proofs for these conditions, and introduce multiple methods for fine-tuning model parameters within DSP. Our extensive experiments substantiate the effectiveness of the proposed P3A method. Our code is accessible at: https://anonymous.4open.science/r/P3A-A12C/
Read more8/16/2024
🛠️
0
A New Linear Scaling Rule for Private Adaptive Hyperparameter Optimization
Ashwinee Panda, Xinyu Tang, Saeed Mahloujifar, Vikash Sehwag, Prateek Mittal
An open problem in differentially private deep learning is hyperparameter optimization (HPO). DP-SGD introduces new hyperparameters and complicates existing ones, forcing researchers to painstakingly tune hyperparameters with hundreds of trials, which in turn makes it impossible to account for the privacy cost of HPO without destroying the utility. We propose an adaptive HPO method that uses cheap trials (in terms of privacy cost and runtime) to estimate optimal hyperparameters and scales them up. We obtain state-of-the-art performance on 22 benchmark tasks, across computer vision and natural language processing, across pretraining and finetuning, across architectures and a wide range of $varepsilon in [0.01,8.0]$, all while accounting for the privacy cost of HPO.
Read more5/7/2024