Hyper Recurrent Neural Network: Condition Mechanisms for Black-box Audio Effect Modeling

0

Sign in to get full access
Overview
- The paper proposes a novel neural network architecture called Hyper Recurrent Neural Network (HRNN) for modeling black-box audio effects.
- HRNN introduces condition mechanisms to handle the variable nature of audio signals and provide better control over the model's behavior.
- The architecture is evaluated on a range of audio effect modeling tasks, demonstrating its effectiveness in capturing complex audio dynamics.
Plain English Explanation
The paper describes a new type of neural network called Hyper Recurrent Neural Network (HRNN) that is designed to model the behavior of audio effects. Audio effects are tools that can modify the sound of a musical instrument or recording, like adding reverb or distortion.
Modeling these audio effects using machine learning can be challenging because the input audio signals can vary a lot in terms of their characteristics. The HRNN architecture addresses this by incorporating "condition mechanisms" that allow the model to adapt its behavior based on the specific properties of the input audio.
For example, the model might need to respond differently to a loud, distorted guitar riff versus a soft, clean piano melody. The condition mechanisms give the HRNN more control and flexibility to handle this variability in the input data.
The researchers evaluated the HRNN on several different audio effect modeling tasks, and found that it outperformed other neural network approaches. This suggests the HRNN could be a powerful tool for building intelligent audio processing systems that can mimic the behavior of complex, black-box audio effects.
Technical Explanation
The paper introduces a novel neural network architecture called the Hyper Recurrent Neural Network (HRNN) for modeling black-box audio effects. The key innovation of the HRNN is the inclusion of "condition mechanisms" that allow the model to adapt its behavior based on the characteristics of the input audio signal.
Traditional recurrent neural networks (RNNs) used for audio effect modeling have difficulty capturing the complex, nonlinear dynamics of real-world audio effects. The HRNN addresses this by incorporating additional condition-aware modules that modulate the RNN's internal state and output. These condition mechanisms enable the model to better handle the variability in audio signals, leading to improved performance on a range of audio effect modeling tasks.
The paper evaluates the HRNN architecture on several benchmark datasets for audio effect modeling, including distortion, reverb, and equalization effects. The results demonstrate that the HRNN outperforms other state-of-the-art neural network models, highlighting the effectiveness of the condition mechanisms in capturing the nuanced behaviors of black-box audio processing systems.
Critical Analysis
The paper provides a thorough evaluation of the HRNN's performance on various audio effect modeling tasks, but it would be valuable to see how the model handles more complex and realistic audio processing scenarios. The experiments in the paper focus on relatively simple, isolated audio effects, but real-world audio production often involves the combined use of multiple, interconnected effects.
Additionally, the paper could have explored the interpretability and explainability of the HRNN's condition mechanisms. Understanding how the model's internal representations and decision-making processes relate to the characteristics of the input audio could lead to further insights and improvements in audio effect modeling.
Another potential area for further research would be the integration of the HRNN with other neural network architectures, such as generative models, to enable more versatile and expressive audio processing capabilities. Combining the HRNN's condition-aware modeling with generative techniques could unlock new possibilities for intelligent audio synthesis and manipulation.
Conclusion
The Hyper Recurrent Neural Network (HRNN) proposed in this paper represents a promising approach to modeling the complex, nonlinear behaviors of black-box audio effects. By incorporating condition mechanisms, the HRNN demonstrates improved performance on a range of audio effect modeling tasks compared to traditional RNN models.
The findings of this research suggest that the HRNN could be a valuable tool for building advanced audio processing systems, with potential applications in areas like music production, sound design, and creative audio engineering. As the field of machine learning for audio continues to evolve, the insights and techniques presented in this paper could help drive further advancements in the modeling and manipulation of complex audio phenomena.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hyper Recurrent Neural Network: Condition Mechanisms for Black-box Audio Effect Modeling
Yen-Tung Yeh, Wen-Yi Hsiao, Yi-Hsuan Yang
Recurrent neural networks (RNNs) have demonstrated impressive results for virtual analog modeling of audio effects. These networks process time-domain audio signals using a series of matrix multiplication and nonlinear activation functions to emulate the behavior of the target device accurately. To additionally model the effect of the knobs for an RNN-based model, existing approaches integrate control parameters by concatenating them channel-wisely with some intermediate representation of the input signal. While this method is parameter-efficient, there is room to further improve the quality of generated audio because the concatenation-based conditioning method has limited capacity in modulating signals. In this paper, we propose three novel conditioning mechanisms for RNNs, tailored for black-box virtual analog modeling. These advanced conditioning mechanisms modulate the model based on control parameters, yielding superior results to existing RNN- and CNN-based architectures across various evaluation metrics.
Read more8/12/2024

0
Comparative Study of Recurrent Neural Networks for Virtual Analog Audio Effects Modeling
Riccardo Simionato, Stefano Fasciani
Analog electronic circuits are at the core of an important category of musical devices, which includes a broad range of sound synthesizers and audio effects. The development of software that simulates analog musical devices, known as virtual analog modeling, is a significant sub-field in audio signal processing. Artificial neural networks are a promising technique for virtual analog modeling. While neural approaches have successfully accurately modeled distortion circuits, they require architectural improvements that account for parameter conditioning and low-latency response. This article explores the application of recent machine learning advancements for virtual analog modeling. In particular, we compare State-Space models and Linear Recurrent Units against the more common Long Short-Term Memory networks. Our comparative study uses these black-box neural modeling techniques with various audio effects. We evaluate the performance and limitations of these models using multiple metrics, providing insights for future research and development. Our metrics aim to assess the models' ability to accurately replicate energy envelopes and frequency contents, with a particular focus on transients in the audio signal. To incorporate control parameters into the models, we employ the Feature-wise Linear Modulation method. Long Short-Term Memory networks exhibit better accuracy in emulating distortions and equalizers, while the State-Space model, followed by Long Short-Term Memory networks when integrated in an encoder-decoder structure, and Linear Recurrent Unit outperforms others in emulating saturation and compression. When considering long time-variant characteristics, the State-Space model demonstrates the greatest capability to track history. Long Short-Term Memory networks tend to introduce audio artifacts.
Read more8/30/2024

0
Sample Rate Independent Recurrent Neural Networks for Audio Effects Processing
Alistair Carson, Alec Wright, Jatin Chowdhury, Vesa Valimaki, Stefan Bilbao
In recent years, machine learning approaches to modelling guitar amplifiers and effects pedals have been widely investigated and have become standard practice in some consumer products. In particular, recurrent neural networks (RNNs) are a popular choice for modelling non-linear devices such as vacuum tube amplifiers and distortion circuitry. One limitation of such models is that they are trained on audio at a specific sample rate and therefore give unreliable results when operating at another rate. Here, we investigate several methods of modifying RNN structures to make them approximately sample rate independent, with a focus on oversampling. In the case of integer oversampling, we demonstrate that a previously proposed delay-based approach provides high fidelity sample rate conversion whilst additionally reducing aliasing. For non-integer sample rate adjustment, we propose two novel methods and show that one of these, based on cubic Lagrange interpolation of a delay-line, provides a significant improvement over existing methods. To our knowledge, this work provides the first in-depth study into this problem.
Read more6/11/2024
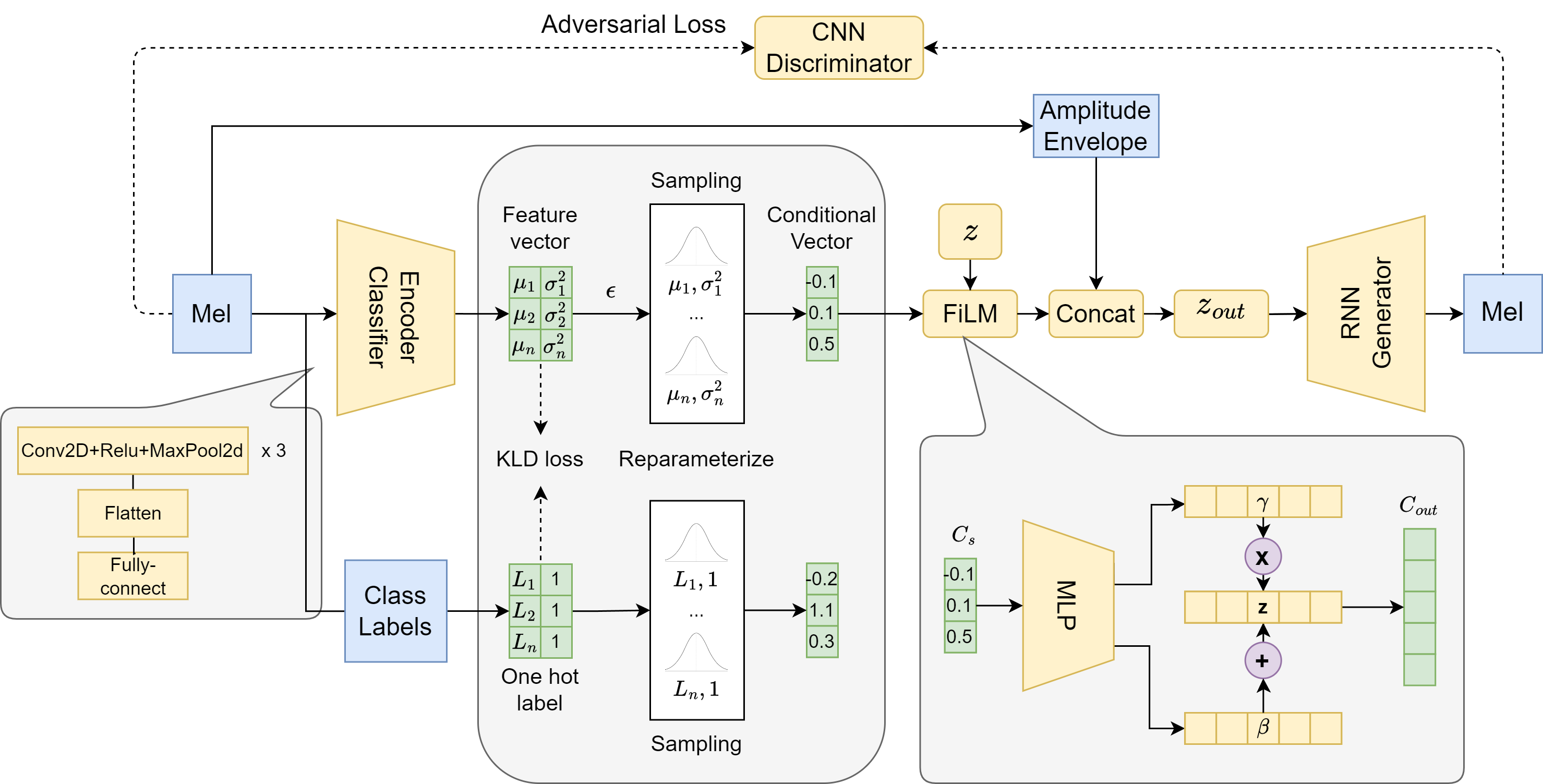
0
ICGAN: An implicit conditioning method for interpretable feature control of neural audio synthesis
Yunyi Liu, Craig Jin
Neural audio synthesis methods can achieve high-fidelity and realistic sound generation by utilizing deep generative models. Such models typically rely on external labels which are often discrete as conditioning information to achieve guided sound generation. However, it remains difficult to control the subtle changes in sounds without appropriate and descriptive labels, especially given a limited dataset. This paper proposes an implicit conditioning method for neural audio synthesis using generative adversarial networks that allows for interpretable control of the acoustic features of synthesized sounds. Our technique creates a continuous conditioning space that enables timbre manipulation without relying on explicit labels. We further introduce an evaluation metric to explore controllability and demonstrate that our approach is effective in enabling a degree of controlled variation of different synthesized sound effects for in-domain and cross-domain sounds.
Read more6/12/2024