ICGAN: An implicit conditioning method for interpretable feature control of neural audio synthesis
2406.07131
0
0
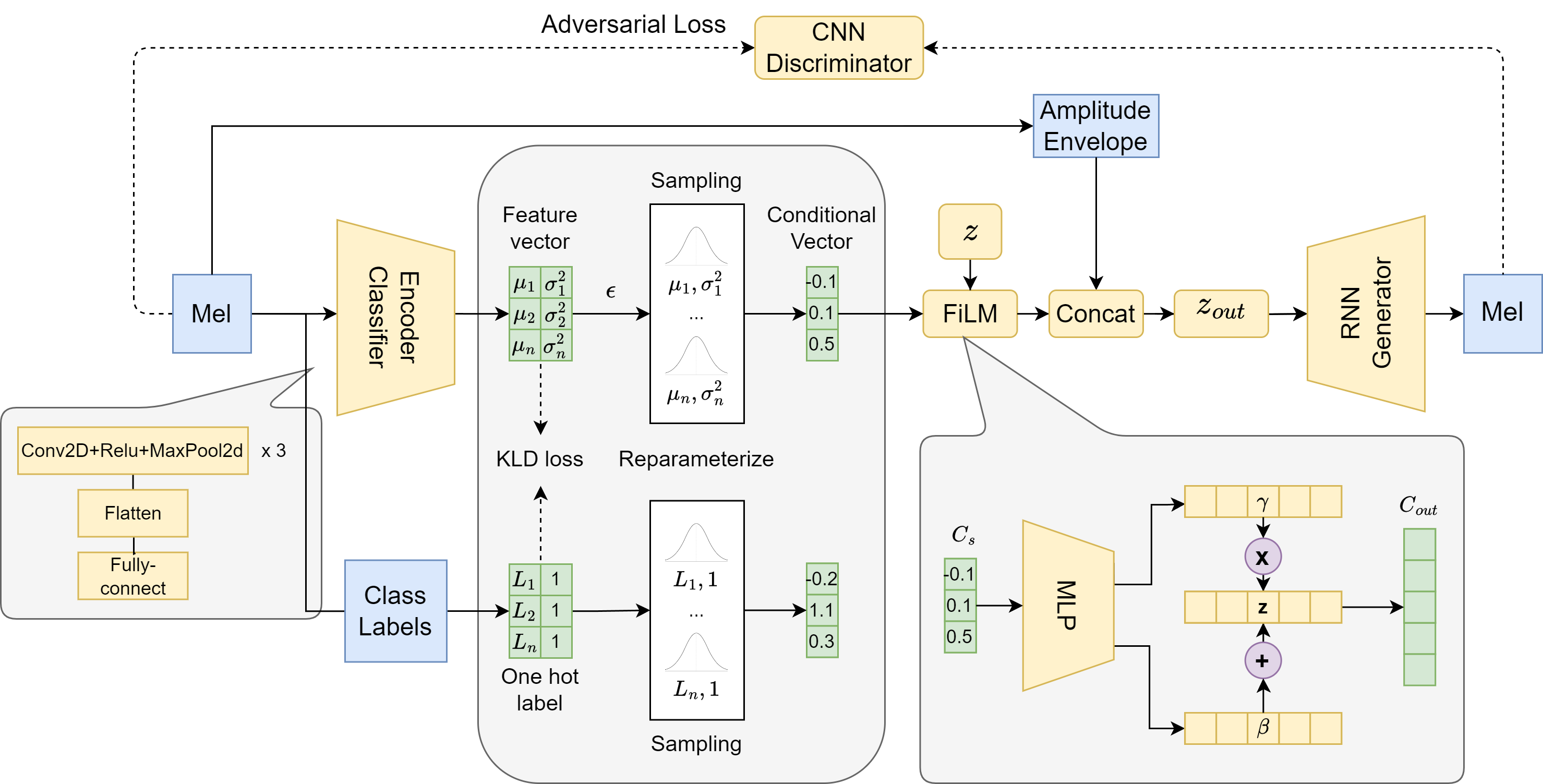
Abstract
Neural audio synthesis methods can achieve high-fidelity and realistic sound generation by utilizing deep generative models. Such models typically rely on external labels which are often discrete as conditioning information to achieve guided sound generation. However, it remains difficult to control the subtle changes in sounds without appropriate and descriptive labels, especially given a limited dataset. This paper proposes an implicit conditioning method for neural audio synthesis using generative adversarial networks that allows for interpretable control of the acoustic features of synthesized sounds. Our technique creates a continuous conditioning space that enables timbre manipulation without relying on explicit labels. We further introduce an evaluation metric to explore controllability and demonstrate that our approach is effective in enabling a degree of controlled variation of different synthesized sound effects for in-domain and cross-domain sounds.
Create account to get full access
Overview
- This paper presents a novel method called "ICGAN" (Implicit Conditioning Generative Adversarial Network) for controlling the features of audio synthesis models in an interpretable way.
- ICGAN allows users to manipulate high-level attributes of the generated audio, such as pitch, timbre, and loudness, without requiring them to understand the underlying network architecture or low-level parameters.
- The approach leverages an implicit conditioning mechanism that maps user-specified target attributes to the latent space of a pretrained audio synthesis model, enabling intuitive control over the output.
Plain English Explanation
The ICGAN method aims to make it easier for users to control the properties of synthesized audio. Typically, audio synthesis models are complex, and adjusting the sound requires fiddling with many technical parameters that are difficult for non-experts to understand.
ICGAN provides a more intuitive way to shape the audio output. Instead of tweaking low-level knobs, users can specify high-level attributes like the pitch, timbre (tone quality), and volume they want. The model then automatically adjusts the internal workings to generate audio matching those target attributes.
This implicit conditioning approach maps the user's desired characteristics to the "latent space" - the abstract mathematical representation the model uses to produce audio. By connecting the user-friendly controls to this latent space, ICGAN allows for interpretable feature control without requiring users to have deep technical knowledge of how the synthesis model works under the hood.
Technical Explanation
The ICGAN framework consists of a pretrained audio synthesis model, such as a generative adversarial network (GAN) or diffusion model, combined with an additional mapping network.
The mapping network takes user-specified target attributes as input and outputs a corresponding point in the synthesis model's latent space. By feeding this latent code into the pretrained synthesis model, ICGAN can generate audio with the desired characteristics, such as a specific pitch, timbre, or loudness.
The authors train this mapping network using a combination of supervised and adversarial objectives. The supervised component ensures the mapping accurately translates the target attributes into the correct latent codes. The adversarial objective, inspired by GANs, encourages the mapping to produce latent codes that the synthesis model can use to generate plausible, high-quality audio.
Experiments demonstrate that ICGAN enables users to control various perceptual audio features in an intuitive way, without sacrificing the fidelity of the generated output compared to the original synthesis model.
Critical Analysis
The ICGAN approach provides a promising solution for improving the interpretability and usability of neural audio synthesis models. By decoupling the high-level control from the low-level synthesis process, it offers a more accessible interface for non-expert users to shape the audio output.
However, the paper acknowledges that ICGAN is limited to manipulating a predefined set of audio attributes. Expanding the range of controllable features or allowing users to define custom attributes could further enhance the flexibility and usefulness of the method.
Additionally, the paper does not address potential issues around the stability and robustness of the implicit conditioning mechanism. It would be valuable to explore how ICGAN behaves when users provide unusual or conflicting target attribute combinations, and whether the model can maintain consistent and coherent audio generation in such cases.
Lastly, while the experiments demonstrate the effectiveness of ICGAN on various synthesis models, the paper does not extensively compare it to alternative techniques for interpretable audio control, such as Arrange, Inpaint, Refine or Controllable Prosody Generation. Further benchmarking against these related methods could help situate the ICGAN approach within the broader field of audio synthesis control.
Conclusion
The ICGAN method presented in this paper offers a promising approach for making neural audio synthesis more accessible and intuitive for users. By providing an implicit conditioning mechanism that maps high-level audio attributes to the latent space of a pretrained synthesis model, ICGAN enables interpretable feature control without requiring deep technical knowledge.
This innovation has the potential to unlock new applications and use cases for neural audio synthesis, making it more feasible for non-expert users to harness the power of these advanced generative models. As the field continues to evolve, further research on expanding the range of controllable features and ensuring the robustness of implicit conditioning techniques will be valuable in realizing the full potential of ICGAN and similar methods.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Example-Based Framework for Perceptually Guided Audio Texture Generation
Purnima Kamath, Chitralekha Gupta, Lonce Wyse, Suranga Nanayakkara
0
0
Controllable generation using StyleGANs is usually achieved by training the model using labeled data. For audio textures, however, there is currently a lack of large semantically labeled datasets. Therefore, to control generation, we develop a method for semantic control over an unconditionally trained StyleGAN in the absence of such labeled datasets. In this paper, we propose an example-based framework to determine guidance vectors for audio texture generation based on user-defined semantic attributes. Our approach leverages the semantically disentangled latent space of an unconditionally trained StyleGAN. By using a few synthetic examples to indicate the presence or absence of a semantic attribute, we infer the guidance vectors in the latent space of the StyleGAN to control that attribute during generation. Our results show that our framework can find user-defined and perceptually relevant guidance vectors for controllable generation for audio textures. Furthermore, we demonstrate an application of our framework to other tasks, such as selective semantic attribute transfer.
4/16/2024
Arrange, Inpaint, and Refine: Steerable Long-term Music Audio Generation and Editing via Content-based Controls
Liwei Lin, Gus Xia, Yixiao Zhang, Junyan Jiang
0
0
Controllable music generation plays a vital role in human-AI music co-creation. While Large Language Models (LLMs) have shown promise in generating high-quality music, their focus on autoregressive generation limits their utility in music editing tasks. To address this gap, we propose a novel approach leveraging a parameter-efficient heterogeneous adapter combined with a masking training scheme. This approach enables autoregressive language models to seamlessly address music inpainting tasks. Additionally, our method integrates frame-level content-based controls, facilitating track-conditioned music refinement and score-conditioned music arrangement. We apply this method to fine-tune MusicGen, a leading autoregressive music generation model. Our experiments demonstrate promising results across multiple music editing tasks, offering more flexible controls for future AI-driven music editing tools. The source codes and a demo page showcasing our work are available at https://kikyo-16.github.io/AIR.
6/11/2024

Listen and Move: Improving GANs Coherency in Agnostic Sound-to-Video Generation
Rafael Redondo
0
0
Deep generative models have demonstrated the ability to create realistic audiovisual content, sometimes driven by domains of different nature. However, smooth temporal dynamics in video generation is a challenging problem. This work focuses on generic sound-to-video generation and proposes three main features to enhance both image quality and temporal coherency in generative adversarial models: a triple sound routing scheme, a multi-scale residual and dilated recurrent network for extended sound analysis, and a novel recurrent and directional convolutional layer for video prediction. Each of the proposed features improves, in both quality and coherency, the baseline neural architecture typically used in the SoTA, with the video prediction layer providing an extra temporal refinement.
6/26/2024
Contrastive Learning from Synthetic Audio Doppelgangers
Manuel Cherep, Nikhil Singh
0
0
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
6/11/2024