HyperFields: Towards Zero-Shot Generation of NeRFs from Text
2310.17075
2
0
🛸
Abstract
We introduce HyperFields, a method for generating text-conditioned Neural Radiance Fields (NeRFs) with a single forward pass and (optionally) some fine-tuning. Key to our approach are: (i) a dynamic hypernetwork, which learns a smooth mapping from text token embeddings to the space of NeRFs; (ii) NeRF distillation training, which distills scenes encoded in individual NeRFs into one dynamic hypernetwork. These techniques enable a single network to fit over a hundred unique scenes. We further demonstrate that HyperFields learns a more general map between text and NeRFs, and consequently is capable of predicting novel in-distribution and out-of-distribution scenes -- either zero-shot or with a few finetuning steps. Finetuning HyperFields benefits from accelerated convergence thanks to the learned general map, and is capable of synthesizing novel scenes 5 to 10 times faster than existing neural optimization-based methods. Our ablation experiments show that both the dynamic architecture and NeRF distillation are critical to the expressivity of HyperFields.
Create account to get full access
Overview
- HyperFields is a method for generating text-conditioned Neural Radiance Fields (NeRFs) with a single forward pass and optional fine-tuning.
- Key aspects are a dynamic hypernetwork that learns a smooth mapping from text token embeddings to the space of NeRFs, and NeRF distillation training to distill scenes encoded in individual NeRFs into one dynamic hypernetwork.
- This allows a single network to fit over a hundred unique scenes, and learn a more general map between text and NeRFs, enabling prediction of novel in-distribution and out-of-distribution scenes.
- Finetuning HyperFields benefits from accelerated convergence and can synthesize novel scenes 5-10 times faster than existing neural optimization-based methods.
Plain English Explanation
HyperFields is a new approach for generating 3D scenes from text descriptions. Neural Radiance Fields (NeRFs) are a powerful technique for representing 3D scenes, but typically require a lot of computational resources to generate a single scene.
HyperFields solves this by using a dynamic hypernetwork - a neural network that can rapidly generate unique NeRFs from text inputs. The hypernetwork learns a smooth mapping between text descriptions and the parameters of NeRFs, allowing it to efficiently produce a wide variety of 3D scenes with a single forward pass.
Additionally, HyperFields uses a technique called NeRF distillation to condense the knowledge of many individual NeRFs into the hypernetwork. This means the hypernetwork can capture the details of over a hundred unique scenes, rather than just a single one.
The result is a system that can generate novel 3D scenes from text descriptions, either completely from scratch or by fine-tuning on a few examples. This fine-tuning process is much faster than training NeRFs from scratch, allowing HyperFields to synthesize new scenes 5-10 times quicker than previous methods.
Technical Explanation
The core of HyperFields is a dynamic hypernetwork that learns a smooth mapping from text token embeddings to the space of NeRFs. This allows the system to efficiently generate unique NeRFs for diverse text inputs with a single forward pass, rather than having to optimize each NeRF individually.
To train the hypernetwork, the authors use a NeRF distillation technique. They first train individual NeRFs for a large number of scenes, then distill the knowledge from these NeRFs into the parameters of the hypernetwork. This enables the hypernetwork to capture the details of over a hundred unique scenes, rather than just a single one.
The authors demonstrate that HyperFields learns a more general map between text and NeRFs, allowing it to predict novel in-distribution and out-of-distribution scenes either zero-shot or with a few finetuning steps. This finetuning process benefits from accelerated convergence compared to training NeRFs from scratch, enabling HyperFields to synthesize new scenes 5-10 times faster than existing neural optimization-based methods.
Ablation experiments show that both the dynamic architecture and NeRF distillation are critical to the expressivity of HyperFields, highlighting the importance of these key components.
Critical Analysis
The HyperFields paper presents a novel and promising approach for text-conditional 3D scene generation. The authors demonstrate impressive results in terms of the diversity of scenes that can be generated and the efficiency of the finetuning process.
However, the paper does not address some potential limitations or areas for further research. For example, the quality of the generated scenes is not comprehensively evaluated, and it's unclear how HyperFields compares to other text-to-3D methods in terms of visual fidelity and realism.
Additionally, the paper does not explore the robustness of HyperFields to out-of-distribution text inputs or its ability to handle more complex scene descriptions. Connecting NeRFs: Images & Text and Depth-Aware Text-Based Editing of NeRFs are related works that could provide useful context and comparisons.
Further research could also investigate the interpretability of the hypernetwork's internal representations and explore ways to leverage the learned text-to-NeRF mapping for other applications, such as neural radiance field-based holography or sparse input radiance field regularization.
Conclusion
HyperFields represents a significant advancement in the field of text-conditional 3D scene generation. By leveraging a dynamic hypernetwork and NeRF distillation, the authors have developed a system that can efficiently produce a wide variety of 3D scenes from text descriptions, with the ability to fine-tune on new examples quickly.
This work has the potential to enable more natural and accessible 3D content creation, as well as to contribute to other areas of 3D scene understanding and manipulation. While the paper highlights several notable strengths of the HyperFields approach, further research will be needed to fully explore its capabilities and limitations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DATENeRF: Depth-Aware Text-based Editing of NeRFs
Sara Rojas, Julien Philip, Kai Zhang, Sai Bi, Fujun Luan, Bernard Ghanem, Kalyan Sunkavall
0
0
Recent advancements in diffusion models have shown remarkable proficiency in editing 2D images based on text prompts. However, extending these techniques to edit scenes in Neural Radiance Fields (NeRF) is complex, as editing individual 2D frames can result in inconsistencies across multiple views. Our crucial insight is that a NeRF scene's geometry can serve as a bridge to integrate these 2D edits. Utilizing this geometry, we employ a depth-conditioned ControlNet to enhance the coherence of each 2D image modification. Moreover, we introduce an inpainting approach that leverages the depth information of NeRF scenes to distribute 2D edits across different images, ensuring robustness against errors and resampling challenges. Our results reveal that this methodology achieves more consistent, lifelike, and detailed edits than existing leading methods for text-driven NeRF scene editing.
4/9/2024
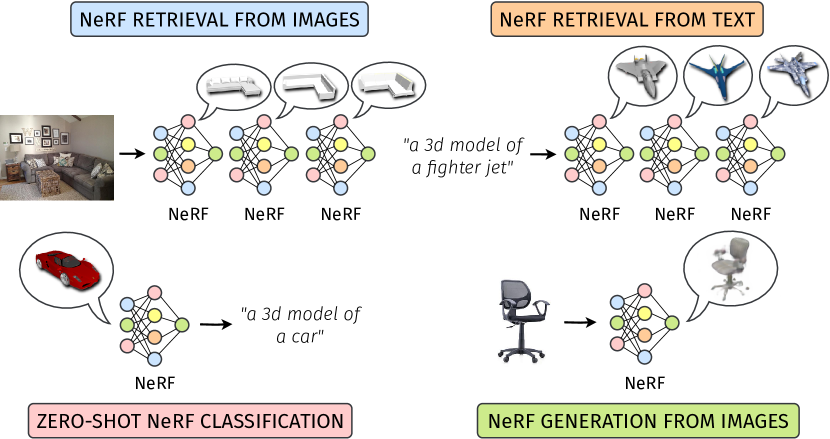
Connecting NeRFs, Images, and Text
Francesco Ballerini, Pierluigi Zama Ramirez, Roberto Mirabella, Samuele Salti, Luigi Di Stefano
0
0
Neural Radiance Fields (NeRFs) have emerged as a standard framework for representing 3D scenes and objects, introducing a novel data type for information exchange and storage. Concurrently, significant progress has been made in multimodal representation learning for text and image data. This paper explores a novel research direction that aims to connect the NeRF modality with other modalities, similar to established methodologies for images and text. To this end, we propose a simple framework that exploits pre-trained models for NeRF representations alongside multimodal models for text and image processing. Our framework learns a bidirectional mapping between NeRF embeddings and those obtained from corresponding images and text. This mapping unlocks several novel and useful applications, including NeRF zero-shot classification and NeRF retrieval from images or text.
4/12/2024
![Neural radiance fields-based holography [Invited]](https://arxiv.org/html/2403.01137v1/extracted/5444105/fig_outline.jpg)
Neural radiance fields-based holography [Invited]
Minsung Kang, Fan Wang, Kai Kumano, Tomoyoshi Ito, Tomoyoshi Shimobaba
0
0
This study presents a novel approach for generating holograms based on the neural radiance fields (NeRF) technique. Generating three-dimensional (3D) data is difficult in hologram computation. NeRF is a state-of-the-art technique for 3D light-field reconstruction from 2D images based on volume rendering. The NeRF can rapidly predict new-view images that do not include a training dataset. In this study, we constructed a rendering pipeline directly from a 3D light field generated from 2D images by NeRF for hologram generation using deep neural networks within a reasonable time. The pipeline comprises three main components: the NeRF, a depth predictor, and a hologram generator, all constructed using deep neural networks. The pipeline does not include any physical calculations. The predicted holograms of a 3D scene viewed from any direction were computed using the proposed pipeline. The simulation and experimental results are presented.
5/13/2024
👁️
Simple-RF: Regularizing Sparse Input Radiance Fields with Simpler Solutions
Nagabhushan Somraj, Sai Harsha Mupparaju, Adithyan Karanayil, Rajiv Soundararajan
0
0
Neural Radiance Fields (NeRF) show impressive performance in photo-realistic free-view rendering of scenes. Recent improvements on the NeRF such as TensoRF and ZipNeRF employ explicit models for faster optimization and rendering, as compared to the NeRF that employs an implicit representation. However, both implicit and explicit radiance fields require dense sampling of images in the given scene. Their performance degrades significantly when only a sparse set of views is available. Researchers find that supervising the depth estimated by a radiance field helps train it effectively with fewer views. The depth supervision is obtained either using classical approaches or neural networks pre-trained on a large dataset. While the former may provide only sparse supervision, the latter may suffer from generalization issues. As opposed to the earlier approaches, we seek to learn the depth supervision by designing augmented models and training them along with the main radiance field. Further, we aim to design a framework of regularizations that can work across different implicit and explicit radiance fields. We observe that certain features of these radiance field models overfit to the observed images in the sparse-input scenario. Our key finding is that reducing the capability of the radiance fields with respect to positional encoding, the number of decomposed tensor components or the size of the hash table, constrains the model to learn simpler solutions, which estimate better depth in certain regions. By designing augmented models based on such reduced capabilities, we obtain better depth supervision for the main radiance field. We achieve state-of-the-art view-synthesis performance with sparse input views on popular datasets containing forward-facing and 360$^circ$ scenes by employing the above regularizations.
5/28/2024