Identifying and Mitigating Privacy Risks Stemming from Language Models: A Survey
2310.01424
0
0
💬
Abstract
Large Language Models (LLMs) have shown greatly enhanced performance in recent years, attributed to increased size and extensive training data. This advancement has led to widespread interest and adoption across industries and the public. However, training data memorization in Machine Learning models scales with model size, particularly concerning for LLMs. Memorized text sequences have the potential to be directly leaked from LLMs, posing a serious threat to data privacy. Various techniques have been developed to attack LLMs and extract their training data. As these models continue to grow, this issue becomes increasingly critical. To help researchers and policymakers understand the state of knowledge around privacy attacks and mitigations, including where more work is needed, we present the first SoK on data privacy for LLMs. We (i) identify a taxonomy of salient dimensions where attacks differ on LLMs, (ii) systematize existing attacks, using our taxonomy of dimensions to highlight key trends, (iii) survey existing mitigation strategies, highlighting their strengths and limitations, and (iv) identify key gaps, demonstrating open problems and areas for concern.
Create account to get full access
Overview
- Examines the privacy risks posed by large language models (LLMs) and strategies to mitigate these risks
- Covers recent research on protecting individual privacy when using LLMs, such as Beyond Memorization: Violating Privacy via Inference Attacks on Language Models, Large Language Models: A New Approach to Privacy Policy, and Understanding the Privacy Risks of Learning Contextual Embeddings Induced by Large Language Models
- Discusses challenges in balancing the benefits of LLMs with their potential to compromise individual privacy
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. While LLMs have many beneficial applications, they also pose risks to individual privacy. This paper provides an overview of the latest research on identifying and mitigating these privacy risks.
One key issue is that LLMs can potentially "memorize" and reproduce sensitive personal information from their training data, even if that data was intended to be private. Researchers have found ways to exploit this vulnerability and extract private information by carefully crafting prompts for the LLM.
The paper also examines how the language models themselves can inadvertently reveal private details about individuals through the contextual embeddings they generate. These embeddings, which capture the meaning and relationships between words, can unintentionally encode sensitive information about the people and entities mentioned in the training data.
To address these concerns, the paper discusses new approaches to privacy-preserving language modeling, such as techniques for sanitizing training data, modifying model architectures, and developing privacy-aware policies. The goal is to unlock the benefits of LLMs while minimizing the risks to individual privacy.
Overall, this paper highlights the importance of carefully considering the privacy implications as LLMs become more prevalent in our lives. Striking the right balance between innovation and individual rights is a critical challenge for the AI research community.
Technical Explanation
The paper provides a comprehensive survey of the privacy risks associated with large language models (LLMs) and the latest research on mitigating these risks. LLMs, which are trained on vast amounts of text data, have demonstrated impressive capabilities in generating human-like language. However, this power comes with potential privacy concerns.
One key issue is the risk of LLMs "memorizing" and reproducing sensitive personal information from their training data. Researchers have developed inference attack techniques that can exploit this vulnerability and extract private details from LLMs, even when the training data was intended to be private.
The paper also examines how the language models themselves can inadvertently reveal private information through the contextual embeddings they generate. These embeddings, which capture the meaning and relationships between words, can unintentionally encode sensitive details about the people and entities mentioned in the training data.
To address these privacy concerns, the paper discusses new approaches to privacy-preserving language modeling, such as techniques for sanitizing training data, modifying model architectures, and developing privacy-aware policies. The goal is to unlock the benefits of LLMs while minimizing the risks to individual privacy.
Critical Analysis
The paper provides a comprehensive and well-researched overview of the privacy risks associated with large language models (LLMs). The authors thoroughly explore the various ways in which LLMs can compromise individual privacy, from the risk of memorizing and reproducing sensitive personal information to the unintended disclosure of private details through contextual embeddings.
One potential limitation of the paper is that it primarily focuses on the technical aspects of the privacy risks and mitigation strategies, without delving deeply into the broader societal and ethical implications. While the paper does mention the importance of balancing innovation and individual rights, it could have further explored the philosophical and policy challenges in this domain.
Additionally, the paper does not provide a detailed comparative analysis of the different privacy-preserving techniques discussed, which could have helped readers better understand the relative strengths and weaknesses of each approach. A more in-depth critique of the various methods and their potential limitations would have been valuable.
Nevertheless, the paper is a valuable resource for researchers and practitioners working in the field of large language models. By highlighting the critical privacy concerns and the latest advancements in mitigation strategies, the paper serves as an important starting point for further research and development in this rapidly evolving area of AI.
Conclusion
This comprehensive survey paper examines the privacy risks posed by large language models (LLMs) and the latest research on strategies to mitigate these risks. The authors explore how LLMs can potentially compromise individual privacy through the memorization and reproduction of sensitive personal information, as well as the unintentional disclosure of private details through the language models' own contextual embeddings.
To address these concerns, the paper discusses various privacy-preserving techniques, such as data sanitization, model architecture modifications, and the development of privacy-aware policies. These approaches aim to unlock the benefits of LLMs while minimizing the risks to individual privacy.
As LLMs continue to advance and become more pervasive in our lives, the need to prioritize individual privacy becomes increasingly crucial. This paper serves as an important contribution to the ongoing effort to balance the powerful capabilities of LLMs with the fundamental right to privacy. It provides a solid foundation for further research and development in this critical area of AI ethics and policy.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Privacy Issues in Large Language Models: A Survey
Seth Neel, Peter Chang
0
0
This is the first survey of the active area of AI research that focuses on privacy issues in Large Language Models (LLMs). Specifically, we focus on work that red-teams models to highlight privacy risks, attempts to build privacy into the training or inference process, enables efficient data deletion from trained models to comply with existing privacy regulations, and tries to mitigate copyright issues. Our focus is on summarizing technical research that develops algorithms, proves theorems, and runs empirical evaluations. While there is an extensive body of legal and policy work addressing these challenges from a different angle, that is not the focus of our survey. Nevertheless, these works, along with recent legal developments do inform how these technical problems are formalized, and so we discuss them briefly in Section 1. While we have made our best effort to include all the relevant work, due to the fast moving nature of this research we may have missed some recent work. If we have missed some of your work please contact us, as we will attempt to keep this survey relatively up to date. We are maintaining a repository with the list of papers covered in this survey and any relevant code that was publicly available at https://github.com/safr-ml-lab/survey-llm.
6/3/2024
🤯
Beyond Memorization: Violating Privacy Via Inference with Large Language Models
Robin Staab, Mark Vero, Mislav Balunovi'c, Martin Vechev
0
0
Current privacy research on large language models (LLMs) primarily focuses on the issue of extracting memorized training data. At the same time, models' inference capabilities have increased drastically. This raises the key question of whether current LLMs could violate individuals' privacy by inferring personal attributes from text given at inference time. In this work, we present the first comprehensive study on the capabilities of pretrained LLMs to infer personal attributes from text. We construct a dataset consisting of real Reddit profiles, and show that current LLMs can infer a wide range of personal attributes (e.g., location, income, sex), achieving up to $85%$ top-1 and $95%$ top-3 accuracy at a fraction of the cost ($100times$) and time ($240times$) required by humans. As people increasingly interact with LLM-powered chatbots across all aspects of life, we also explore the emerging threat of privacy-invasive chatbots trying to extract personal information through seemingly benign questions. Finally, we show that common mitigations, i.e., text anonymization and model alignment, are currently ineffective at protecting user privacy against LLM inference. Our findings highlight that current LLMs can infer personal data at a previously unattainable scale. In the absence of working defenses, we advocate for a broader discussion around LLM privacy implications beyond memorization, striving for a wider privacy protection.
5/7/2024

Large Language Models: A New Approach for Privacy Policy Analysis at Scale
David Rodriguez, Ian Yang, Jose M. Del Alamo, Norman Sadeh
0
0
The number and dynamic nature of web and mobile applications presents significant challenges for assessing their compliance with data protection laws. In this context, symbolic and statistical Natural Language Processing (NLP) techniques have been employed for the automated analysis of these systems' privacy policies. However, these techniques typically require labor-intensive and potentially error-prone manually annotated datasets for training and validation. This research proposes the application of Large Language Models (LLMs) as an alternative for effectively and efficiently extracting privacy practices from privacy policies at scale. Particularly, we leverage well-known LLMs such as ChatGPT and Llama 2, and offer guidance on the optimal design of prompts, parameters, and models, incorporating advanced strategies such as few-shot learning. We further illustrate its capability to detect detailed and varied privacy practices accurately. Using several renowned datasets in the domain as a benchmark, our evaluation validates its exceptional performance, achieving an F1 score exceeding 93%. Besides, it does so with reduced costs, faster processing times, and fewer technical knowledge requirements. Consequently, we advocate for LLM-based solutions as a sound alternative to traditional NLP techniques for the automated analysis of privacy policies at scale.
6/3/2024
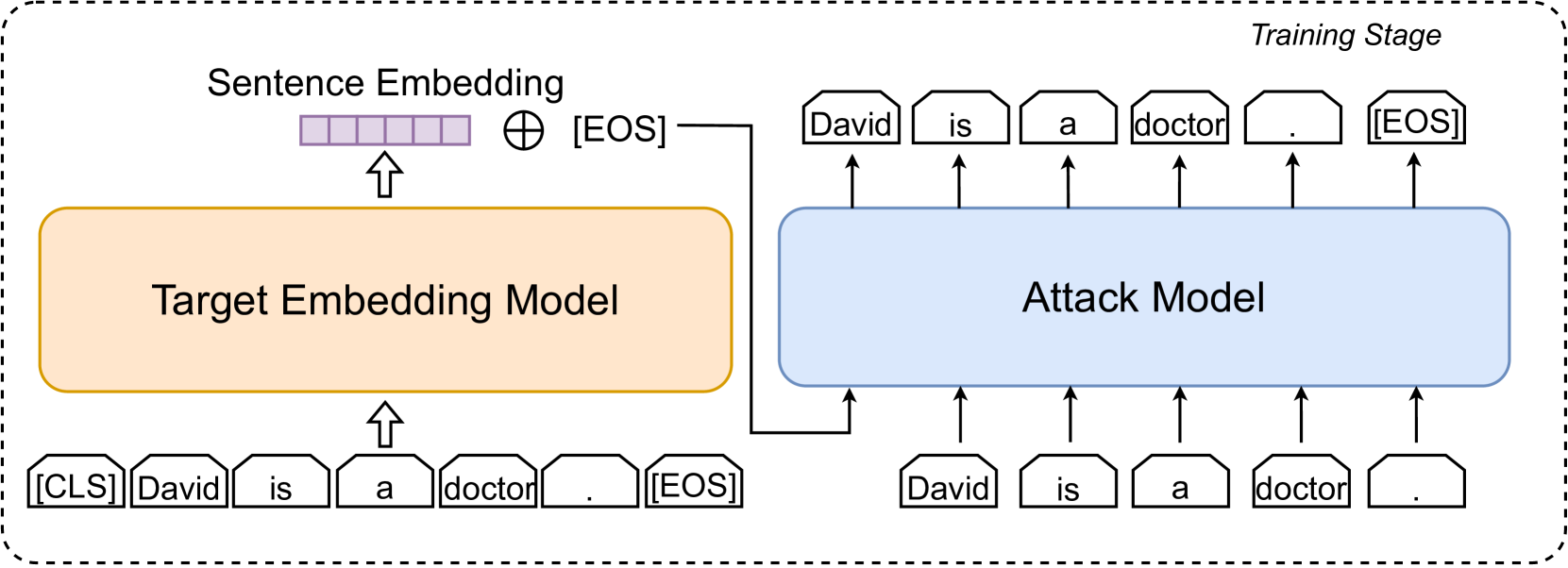
Understanding Privacy Risks of Embeddings Induced by Large Language Models
Zhihao Zhu, Ninglu Shao, Defu Lian, Chenwang Wu, Zheng Liu, Yi Yang, Enhong Chen
0
0
Large language models (LLMs) show early signs of artificial general intelligence but struggle with hallucinations. One promising solution to mitigate these hallucinations is to store external knowledge as embeddings, aiding LLMs in retrieval-augmented generation. However, such a solution risks compromising privacy, as recent studies experimentally showed that the original text can be partially reconstructed from text embeddings by pre-trained language models. The significant advantage of LLMs over traditional pre-trained models may exacerbate these concerns. To this end, we investigate the effectiveness of reconstructing original knowledge and predicting entity attributes from these embeddings when LLMs are employed. Empirical findings indicate that LLMs significantly improve the accuracy of two evaluated tasks over those from pre-trained models, regardless of whether the texts are in-distribution or out-of-distribution. This underscores a heightened potential for LLMs to jeopardize user privacy, highlighting the negative consequences of their widespread use. We further discuss preliminary strategies to mitigate this risk.
4/26/2024