Large Language Models: A New Approach for Privacy Policy Analysis at Scale
2405.20900
0
0

Abstract
The number and dynamic nature of web and mobile applications presents significant challenges for assessing their compliance with data protection laws. In this context, symbolic and statistical Natural Language Processing (NLP) techniques have been employed for the automated analysis of these systems' privacy policies. However, these techniques typically require labor-intensive and potentially error-prone manually annotated datasets for training and validation. This research proposes the application of Large Language Models (LLMs) as an alternative for effectively and efficiently extracting privacy practices from privacy policies at scale. Particularly, we leverage well-known LLMs such as ChatGPT and Llama 2, and offer guidance on the optimal design of prompts, parameters, and models, incorporating advanced strategies such as few-shot learning. We further illustrate its capability to detect detailed and varied privacy practices accurately. Using several renowned datasets in the domain as a benchmark, our evaluation validates its exceptional performance, achieving an F1 score exceeding 93%. Besides, it does so with reduced costs, faster processing times, and fewer technical knowledge requirements. Consequently, we advocate for LLM-based solutions as a sound alternative to traditional NLP techniques for the automated analysis of privacy policies at scale.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Identifying and Mitigating Privacy Risks Stemming from Language Models: A Survey
Victoria Smith, Ali Shahin Shamsabadi, Carolyn Ashurst, Adrian Weller
0
0
Large Language Models (LLMs) have shown greatly enhanced performance in recent years, attributed to increased size and extensive training data. This advancement has led to widespread interest and adoption across industries and the public. However, training data memorization in Machine Learning models scales with model size, particularly concerning for LLMs. Memorized text sequences have the potential to be directly leaked from LLMs, posing a serious threat to data privacy. Various techniques have been developed to attack LLMs and extract their training data. As these models continue to grow, this issue becomes increasingly critical. To help researchers and policymakers understand the state of knowledge around privacy attacks and mitigations, including where more work is needed, we present the first SoK on data privacy for LLMs. We (i) identify a taxonomy of salient dimensions where attacks differ on LLMs, (ii) systematize existing attacks, using our taxonomy of dimensions to highlight key trends, (iii) survey existing mitigation strategies, highlighting their strengths and limitations, and (iv) identify key gaps, demonstrating open problems and areas for concern.
6/19/2024

Privacy Issues in Large Language Models: A Survey
Seth Neel, Peter Chang
0
0
This is the first survey of the active area of AI research that focuses on privacy issues in Large Language Models (LLMs). Specifically, we focus on work that red-teams models to highlight privacy risks, attempts to build privacy into the training or inference process, enables efficient data deletion from trained models to comply with existing privacy regulations, and tries to mitigate copyright issues. Our focus is on summarizing technical research that develops algorithms, proves theorems, and runs empirical evaluations. While there is an extensive body of legal and policy work addressing these challenges from a different angle, that is not the focus of our survey. Nevertheless, these works, along with recent legal developments do inform how these technical problems are formalized, and so we discuss them briefly in Section 1. While we have made our best effort to include all the relevant work, due to the fast moving nature of this research we may have missed some recent work. If we have missed some of your work please contact us, as we will attempt to keep this survey relatively up to date. We are maintaining a repository with the list of papers covered in this survey and any relevant code that was publicly available at https://github.com/safr-ml-lab/survey-llm.
6/3/2024
💬
Enhancing Legal Compliance and Regulation Analysis with Large Language Models
Shabnam Hassani
0
0
This research explores the application of Large Language Models (LLMs) for automating the extraction of requirement-related legal content in the food safety domain and checking legal compliance of regulatory artifacts. With Industry 4.0 revolutionizing the food industry and with the General Data Protection Regulation (GDPR) reshaping privacy policies and data processing agreements, there is a growing gap between regulatory analysis and recent technological advancements. This study aims to bridge this gap by leveraging LLMs, namely BERT and GPT models, to accurately classify legal provisions and automate compliance checks. Our findings demonstrate promising results, indicating LLMs' significant potential to enhance legal compliance and regulatory analysis efficiency, notably by reducing manual workload and improving accuracy within reasonable time and financial constraints.
4/29/2024
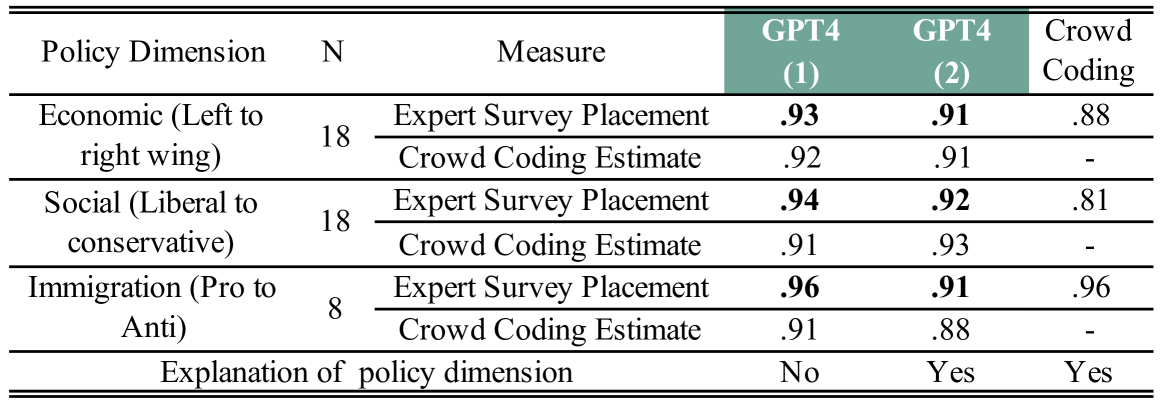
Scaling Political Texts with Large Language Models: Asking a Chatbot Might Be All You Need
Gael Le Mens, Aina Gallego
0
0
We use instruction-tuned Large Language Models (LLMs) such as GPT-4, MiXtral, and Llama 3 to position political texts within policy and ideological spaces. We directly ask the LLMs where a text document or its author stand on the focal policy dimension. We illustrate and validate the approach by scaling British party manifestos on the economic, social, and immigration policy dimensions; speeches from a European Parliament debate in 10 languages on the anti- to pro-subsidy dimension; Senators of the 117th US Congress based on their tweets on the left-right ideological spectrum; and tweets published by US Representatives and Senators after the training cutoff date of GPT-4. The correlation between the position estimates obtained with the best LLMs and benchmarks based on coding by experts, crowdworkers or roll call votes exceeds .90. This training-free approach also outperforms supervised classifiers trained on large amounts of data. Using instruction-tuned LLMs to scale texts in policy and ideological spaces is fast, cost-efficient, reliable, and reproducible (in the case of open LLMs) even if the texts are short and written in different languages. We conclude with cautionary notes about the need for empirical validation.
5/14/2024