Privacy in LLM-based Recommendation: Recent Advances and Future Directions
2406.01363
0
0
🤷
Abstract
Nowadays, large language models (LLMs) have been integrated with conventional recommendation models to improve recommendation performance. However, while most of the existing works have focused on improving the model performance, the privacy issue has only received comparatively less attention. In this paper, we review recent advancements in privacy within LLM-based recommendation, categorizing them into privacy attacks and protection mechanisms. Additionally, we highlight several challenges and propose future directions for the community to address these critical problems.
Create account to get full access
Overview
• This paper explores recent advances and future directions in privacy-preserving recommendations using large language models (LLMs).
• LLMs have revolutionized many areas of AI, including recommender systems, but there are growing concerns about their potential to violate user privacy through inference attacks.
• The paper provides a comprehensive overview of the current state of privacy research in LLM-based recommendations and identifies key challenges and promising directions for future work.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become incredibly powerful tools for a wide range of AI applications, including recommender systems that suggest products, content, or services that users might enjoy. However, as these models become more advanced, there are growing concerns about their ability to potentially violate user privacy.
Through sophisticated inference attacks, LLMs may be able to extract sensitive information about users, even if that information was not directly provided to the model. This could include details about a person's interests, behaviors, or personal circumstances. This raises important questions about how to develop recommendation systems that can provide useful suggestions while still protecting the privacy of the individuals using them.
This paper provides an overview of the current state of research in this area, exploring various approaches that have been proposed to address privacy concerns in LLM-based recommender systems. It also identifies key challenges and promising directions for future work, highlighting the need to balance the powerful capabilities of LLMs with robust privacy safeguards.
Technical Explanation
The paper begins by providing a Preliminary overview of the key concepts and issues related to privacy in LLM-based recommendation systems. It discusses the vulnerabilities of these systems to inference attacks that can extract sensitive user information, as well as the limitations of traditional privacy-preserving techniques in the context of LLMs.
The paper then explores several recent advances in privacy-preserving recommendation, including techniques like differential privacy, homomorphic encryption, and federated learning. It examines how these approaches can be adapted to work with LLM-based recommender systems, highlighting their strengths and weaknesses.
Additionally, the paper discusses the broader implications of privacy concerns in LLM-based recommendations, such as the need for new privacy policies and user trust frameworks. It also explores the potential of alternative approaches that focus on identifying the limits of LLM reliability and transparency.
Critical Analysis
The paper provides a comprehensive and well-researched overview of the current state of privacy research in LLM-based recommendation systems. It acknowledges the significant potential of LLMs to enhance recommender systems, while also highlighting the serious privacy risks that must be addressed.
One potential limitation of the paper is that it does not delve too deeply into the technical details of the various privacy-preserving approaches it discusses. While this makes the content more accessible to a general audience, it may leave some readers wanting more in-depth information on the inner workings and trade-offs of these techniques.
Additionally, the paper does not explore the potential societal implications of privacy violations in LLM-based recommender systems, such as the disproportionate impact on marginalized communities or the broader erosion of trust in AI systems. Addressing these broader concerns could be an important area for future research.
Overall, the paper serves as a valuable resource for understanding the current landscape of privacy research in LLM-based recommendations, and it effectively outlines the key challenges and promising directions for the field going forward.
Conclusion
This paper provides a comprehensive overview of the current state of privacy research in LLM-based recommendation systems. It highlights the significant potential of LLMs to enhance recommender systems, but also the serious privacy risks that must be addressed.
The paper explores various privacy-preserving techniques, such as differential privacy, homomorphic encryption, and federated learning, and examines how they can be adapted to work with LLM-based recommender systems. It also discusses the broader implications of privacy concerns, including the need for new privacy policies and user trust frameworks.
While the paper does not delve too deeply into the technical details of the privacy-preserving approaches, it successfully outlines the key challenges and promising directions for future research in this important and rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
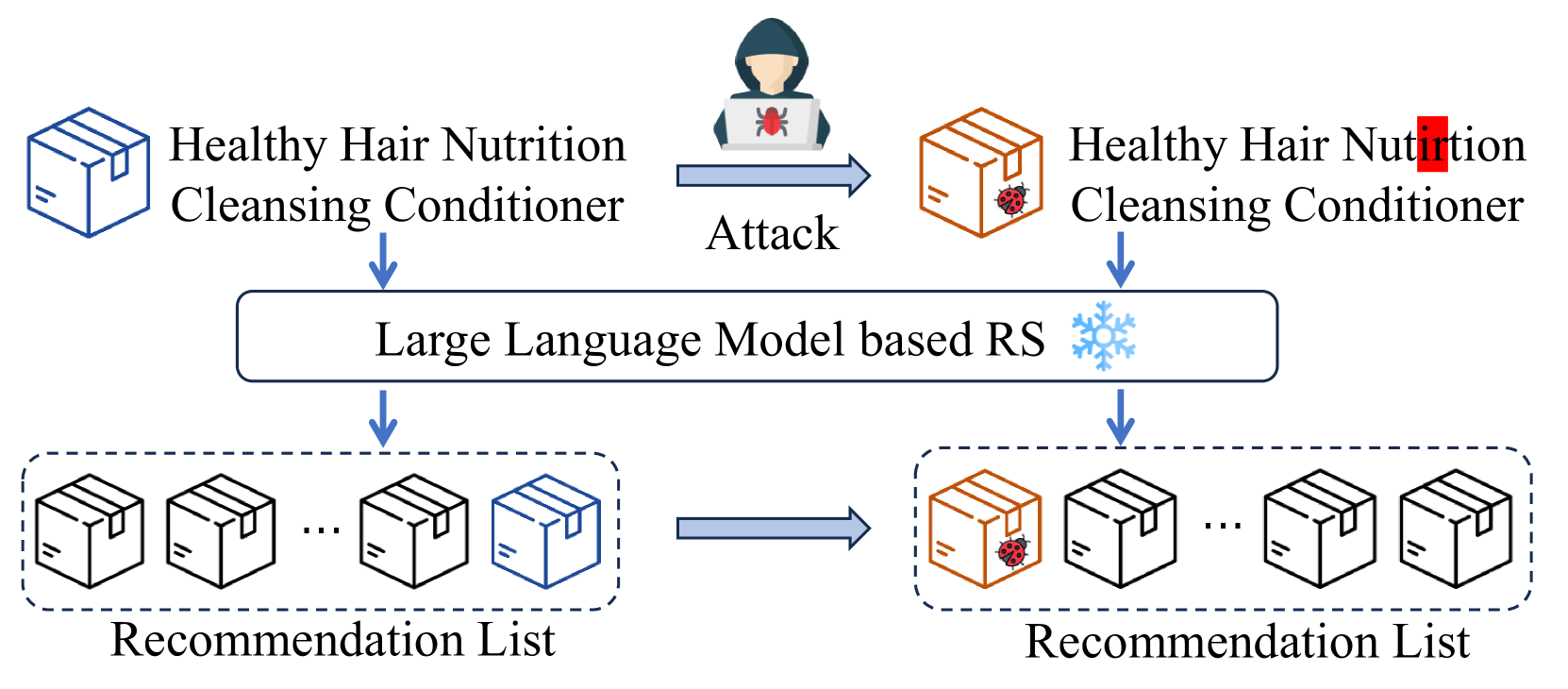
Stealthy Attack on Large Language Model based Recommendation
Jinghao Zhang, Yuting Liu, Qiang Liu, Shu Wu, Guibing Guo, Liang Wang
0
0
Recently, the powerful large language models (LLMs) have been instrumental in propelling the progress of recommender systems (RS). However, while these systems have flourished, their susceptibility to security threats has been largely overlooked. In this work, we reveal that the introduction of LLMs into recommendation models presents new security vulnerabilities due to their emphasis on the textual content of items. We demonstrate that attackers can significantly boost an item's exposure by merely altering its textual content during the testing phase, without requiring direct interference with the model's training process. Additionally, the attack is notably stealthy, as it does not affect the overall recommendation performance and the modifications to the text are subtle, making it difficult for users and platforms to detect. Our comprehensive experiments across four mainstream LLM-based recommendation models demonstrate the superior efficacy and stealthiness of our approach. Our work unveils a significant security gap in LLM-based recommendation systems and paves the way for future research on protecting these systems.
6/6/2024
💬
Identifying and Mitigating Privacy Risks Stemming from Language Models: A Survey
Victoria Smith, Ali Shahin Shamsabadi, Carolyn Ashurst, Adrian Weller
0
0
Large Language Models (LLMs) have shown greatly enhanced performance in recent years, attributed to increased size and extensive training data. This advancement has led to widespread interest and adoption across industries and the public. However, training data memorization in Machine Learning models scales with model size, particularly concerning for LLMs. Memorized text sequences have the potential to be directly leaked from LLMs, posing a serious threat to data privacy. Various techniques have been developed to attack LLMs and extract their training data. As these models continue to grow, this issue becomes increasingly critical. To help researchers and policymakers understand the state of knowledge around privacy attacks and mitigations, including where more work is needed, we present the first SoK on data privacy for LLMs. We (i) identify a taxonomy of salient dimensions where attacks differ on LLMs, (ii) systematize existing attacks, using our taxonomy of dimensions to highlight key trends, (iii) survey existing mitigation strategies, highlighting their strengths and limitations, and (iv) identify key gaps, demonstrating open problems and areas for concern.
6/19/2024

Privacy Issues in Large Language Models: A Survey
Seth Neel, Peter Chang
0
0
This is the first survey of the active area of AI research that focuses on privacy issues in Large Language Models (LLMs). Specifically, we focus on work that red-teams models to highlight privacy risks, attempts to build privacy into the training or inference process, enables efficient data deletion from trained models to comply with existing privacy regulations, and tries to mitigate copyright issues. Our focus is on summarizing technical research that develops algorithms, proves theorems, and runs empirical evaluations. While there is an extensive body of legal and policy work addressing these challenges from a different angle, that is not the focus of our survey. Nevertheless, these works, along with recent legal developments do inform how these technical problems are formalized, and so we discuss them briefly in Section 1. While we have made our best effort to include all the relevant work, due to the fast moving nature of this research we may have missed some recent work. If we have missed some of your work please contact us, as we will attempt to keep this survey relatively up to date. We are maintaining a repository with the list of papers covered in this survey and any relevant code that was publicly available at https://github.com/safr-ml-lab/survey-llm.
6/3/2024
💬
A Survey on Large Language Models for Recommendation
Likang Wu, Zhi Zheng, Zhaopeng Qiu, Hao Wang, Hongchao Gu, Tingjia Shen, Chuan Qin, Chen Zhu, Hengshu Zhu, Qi Liu, Hui Xiong, Enhong Chen
0
0
Large Language Models (LLMs) have emerged as powerful tools in the field of Natural Language Processing (NLP) and have recently gained significant attention in the domain of Recommendation Systems (RS). These models, trained on massive amounts of data using self-supervised learning, have demonstrated remarkable success in learning universal representations and have the potential to enhance various aspects of recommendation systems by some effective transfer techniques such as fine-tuning and prompt tuning, and so on. The crucial aspect of harnessing the power of language models in enhancing recommendation quality is the utilization of their high-quality representations of textual features and their extensive coverage of external knowledge to establish correlations between items and users. To provide a comprehensive understanding of the existing LLM-based recommendation systems, this survey presents a taxonomy that categorizes these models into two major paradigms, respectively Discriminative LLM for Recommendation (DLLM4Rec) and Generative LLM for Recommendation (GLLM4Rec), with the latter being systematically sorted out for the first time. Furthermore, we systematically review and analyze existing LLM-based recommendation systems within each paradigm, providing insights into their methodologies, techniques, and performance. Additionally, we identify key challenges and several valuable findings to provide researchers and practitioners with inspiration. We have also created a GitHub repository to index relevant papers on LLMs for recommendation, https://github.com/WLiK/LLM4Rec.
6/19/2024