Identifying the Source of Generation for Large Language Models

0

Sign in to get full access
Overview
- This research paper explores techniques for identifying the source of generation for large language models (LLMs), which are powerful AI systems that can generate human-like text.
- The paper investigates methods for detecting whether a given text was generated by an LLM or written by a human, as well as approaches for attributing generated text to a specific LLM model or training dataset.
- Understanding the source of generated text has important applications in areas like copyright protection, content moderation, and the prevention of misinformation.
Plain English Explanation
Large language models (LLMs) are AI systems that can generate human-like text on a wide range of topics. While these models have many beneficial applications, there are also concerns about their potential misuse, such as the creation of fake content or plagiarism. To address these issues, researchers in this paper explored techniques for identifying the source of generated text - whether it was written by a human or produced by a specific LLM.
One key approach they examined is
The researchers also looked at ways to attribute generated text to specific models or training datasets, which could be important for copyright protection and content moderation. Additionally, they investigated how factors like text originality and source context can be used to identify the source of generated text.
Overall, this research provides valuable insights into the challenge of distinguishing human-written and AI-generated text, and it opens up new avenues for addressing the risks associated with the growing use of large language models. By better understanding the "fingerprints" of these models, we can work towards developing more robust techniques for source identification and safeguarding against the misuse of powerful language generation technologies.
Technical Explanation
The paper presents a comprehensive investigation into techniques for identifying the source of text generated by large language models (LLMs). The researchers employed a probing approach, designing specialized tasks to test the capabilities and limitations of different LLM architectures, including GPT-2, GPT-3, and T5.
Through these probing experiments, the researchers were able to identify various "fingerprints" or distinctive characteristics of the LLM outputs. For example, they found that LLMs tend to exhibit patterns in their use of language, such as particular word choices, sentence structures, and even logical reasoning capabilities, that can be used to distinguish their generated text from human-written content.
Furthermore, the researchers explored methods for attributing generated text to specific LLM models or training datasets. This could be valuable for applications like copyright protection, content moderation, and the prevention of misinformation. They investigated how factors like text originality and source context can be leveraged to identify the source of generated text.
The paper also touches on the broader challenges of distinguishing human-written and AI-generated text, as the capabilities of LLMs continue to advance. The researchers highlight the need for further research and the development of robust techniques for source identification to address the risks associated with the growing use of these powerful language generation technologies.
Critical Analysis
The research presented in this paper offers valuable insights into the challenge of identifying the source of text generated by large language models. The probing approach used by the researchers provides a systematic way to uncover various "fingerprints" of LLM outputs, which can be leveraged for source identification tasks.
However, the paper also acknowledges some limitations of the proposed techniques. For instance, the researchers note that as LLM architectures and training methods continue to evolve, the distinctive characteristics they identified may become less reliable over time. Additionally, the researchers highlight the potential for LLMs to adapt and become more adept at concealing their "fingerprints," making source identification increasingly difficult.
Another area that could benefit from further exploration is the potential for adversarial attacks, where individuals or organizations may actively try to obfuscate the source of generated text. The paper does not delve deeply into this issue, and it would be valuable to understand how the proposed techniques might hold up against such adversarial efforts.
Overall, this research represents an important step forward in the quest to understand and address the challenges posed by the growing use of large language models. By continuing to explore and refine techniques for source identification, the research community can help develop more robust safeguards against the misuse of these powerful technologies.
Conclusion
This paper offers a comprehensive investigation into methods for identifying the source of text generated by large language models (LLMs). The researchers employed a probing approach to uncover various "fingerprints" or distinctive characteristics of LLM outputs, which can be used to distinguish AI-generated text from human-written content.
The findings have important implications for applications such as copyright protection, content moderation, and the prevention of misinformation. By better understanding the characteristics of LLM-generated text, researchers can develop more robust techniques for source identification and work towards addressing the risks associated with the growing use of these powerful language generation technologies.
While the proposed techniques show promise, the paper also highlights the need for continued research to address the evolving nature of LLM architectures and the potential for adversarial attacks. Ongoing efforts in this area will be crucial for ensuring the responsible development and deployment of large language models in the years to come.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Identifying the Source of Generation for Large Language Models
Bumjin Park, Jaesik Choi
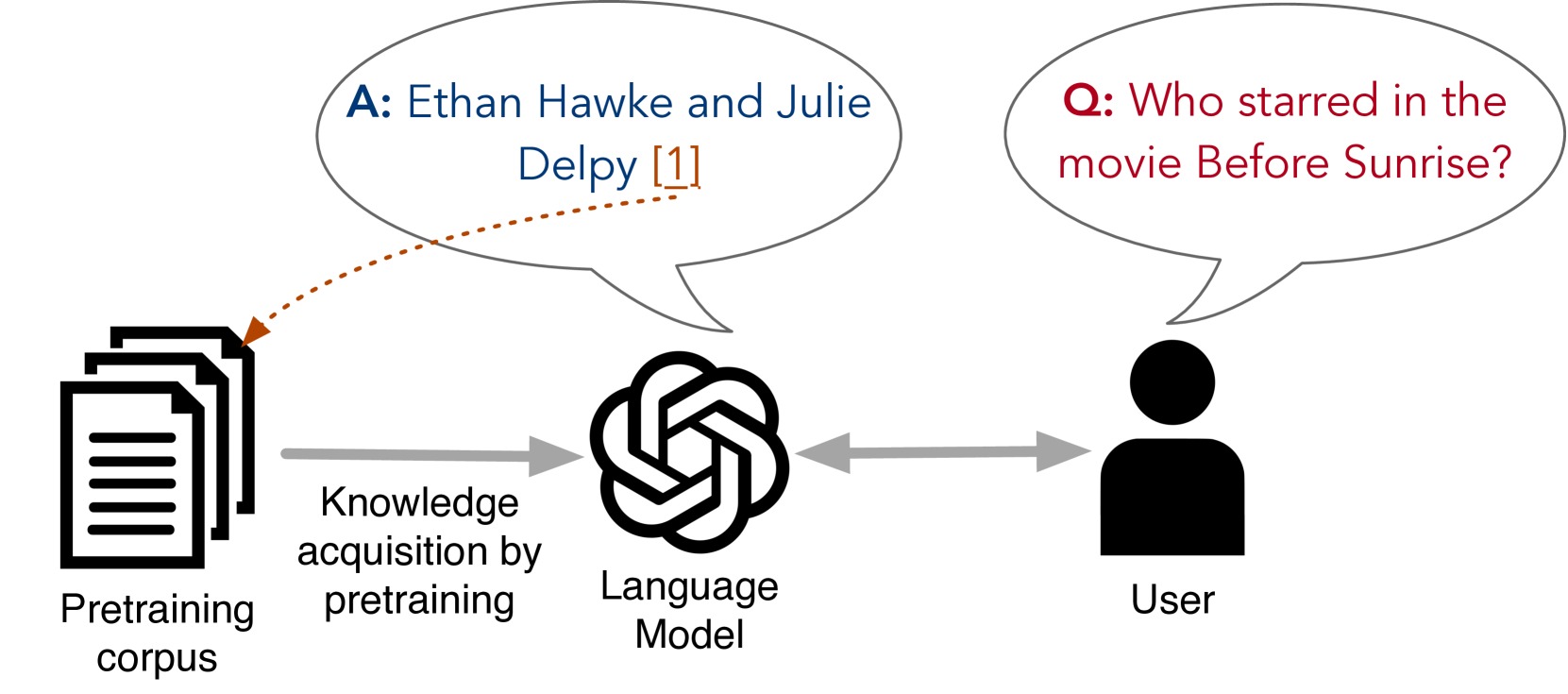
Large language models (LLMs) memorize text from several sources of documents. In pretraining, LLM trains to maximize the likelihood of text but neither receives the source of the text nor memorizes the source. Accordingly, LLM can not provide document information on the generated content, and users do not obtain any hint of reliability, which is crucial for factuality or privacy infringement. This work introduces token-level source identification in the decoding step, which maps the token representation to the reference document. We propose a bi-gram source identifier, a multi-layer perceptron with two successive token representations as input for better generalization. We conduct extensive experiments on Wikipedia and PG19 datasets with several LLMs, layer locations, and identifier sizes. The overall results show a possibility of token-level source identifiers for tracing the document, a crucial problem for the safe use of LLMs.
Read more7/19/2024
0
Source-Aware Training Enables Knowledge Attribution in Language Models
Muhammad Khalifa, David Wadden, Emma Strubell, Honglak Lee, Lu Wang, Iz Beltagy, Hao Peng
Large language models (LLMs) learn a vast amount of knowledge during pretraining, but they are often oblivious to the source(s) of such knowledge. We investigate the problem of intrinsic source citation, where LLMs are required to cite the pretraining source supporting a generated response. Intrinsic source citation can enhance LLM transparency, interpretability, and verifiability. To give LLMs such ability, we explore source-aware training -- a recipe that involves (i) training the LLM to associate unique source document identifiers with the knowledge in each document, followed by (ii) an instruction-tuning stage to teach the LLM to cite a supporting pretraining source when prompted. Source-aware training borrows from existing pretraining/fine-tuning frameworks and requires minimal changes to the model architecture or implementation. Through experiments on synthetic data, we demonstrate that our training recipe can enable faithful attribution to the pretraining data without a substantial impact on the model's perplexity compared to standard pretraining. Our findings also highlight the importance of pretraining data augmentation in achieving attribution. Code and data available here: url{https://github.com/mukhal/intrinsic-source-citation}
Read more8/14/2024

0
SPOT: Text Source Prediction from Originality Score Thresholding
Edouard Yvinec, Gabriel Kasser
The wide acceptance of large language models (LLMs) has unlocked new applications and social risks. Popular countermeasures aim at detecting misinformation, usually involve domain specific models trained to recognize the relevance of any information. Instead of evaluating the validity of the information, we propose to investigate LLM generated text from the perspective of trust. In this study, we define trust as the ability to know if an input text was generated by a LLM or a human. To do so, we design SPOT, an efficient method, that classifies the source of any, standalone, text input based on originality score. This score is derived from the prediction of a given LLM to detect other LLMs. We empirically demonstrate the robustness of the method to the architecture, training data, evaluation data, task and compression of modern LLMs.
Read more6/3/2024
💬
0
Lost in the Source Language: How Large Language Models Evaluate the Quality of Machine Translation
Xu Huang, Zhirui Zhang, Xiang Geng, Yichao Du, Jiajun Chen, Shujian Huang
This study investigates how Large Language Models (LLMs) leverage source and reference data in machine translation evaluation task, aiming to better understand the mechanisms behind their remarkable performance in this task. We design the controlled experiments across various input modes and model types, and employ both coarse-grained and fine-grained prompts to discern the utility of source versus reference information. We find that reference information significantly enhances the evaluation accuracy, while surprisingly, source information sometimes is counterproductive, indicating LLMs' inability to fully leverage the cross-lingual capability when evaluating translations. Further analysis of the fine-grained evaluation and fine-tuning experiments show similar results. These findings also suggest a potential research direction for LLMs that fully exploits the cross-lingual capability of LLMs to achieve better performance in machine translation evaluation tasks.
Read more6/7/2024