Paying More Attention to Source Context: Mitigating Unfaithful Translations from Large Language Model

0

Sign in to get full access
Overview
- This research paper explores ways to improve the faithfulness of translations from large language models (LLMs) by paying more attention to the source context.
- The authors propose several techniques to enhance the contextual understanding of LLMs, including source-aware training, efficiently exploring large language models at the document-level, and enhancing contextual understanding of LLMs through additional signals.
- The goal is to mitigate the issue of unfaithful translations from LLMs, where the generated output may not accurately reflect the meaning of the source text.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text, but they can sometimes produce translations that don't accurately capture the original meaning of the source text. This is known as "unfaithful translation."
The researchers in this paper wanted to find ways to improve the faithfulness of translations from LLMs. They proposed several techniques to help the models better understand the context of the source text, which is crucial for producing accurate translations.
One approach is "source-aware training," where the model is trained to pay attention to the original source text when generating translations. This helps the model maintain a stronger connection to the original meaning.
Another idea is to explore the source text at the document level, rather than just looking at individual sentences. This can provide the model with a richer understanding of the overall context.
The researchers also suggest adding additional signals or cues to the model to enhance its contextual understanding. This could involve incorporating information about the topic, tone, or style of the source text.
By focusing on the source context and finding ways to deepen the model's understanding, the researchers hope to create LLMs that can produce more faithful and accurate translations, avoiding the issue of losing the original meaning.
Technical Explanation
The paper proposes several techniques to improve the faithfulness of translations from large language models (LLMs):
-
Source-aware training: The authors suggest training the LLM to explicitly pay attention to the source text when generating translations. This helps the model maintain a stronger connection to the original meaning and avoid producing output that deviates too far from the source.
-
Efficiently exploring large language models at the document-level: Rather than focusing only on individual sentences, the researchers propose exploring the source text at the document level. This provides the model with a richer understanding of the overall context, which can improve the faithfulness of the translations.
-
Enhancing contextual understanding of LLMs through additional signals: The authors suggest incorporating additional signals or cues into the LLM to enhance its contextual understanding. This could involve information about the topic, tone, or style of the source text, which can help the model generate more faithful translations.
The experiments in the paper demonstrate the effectiveness of these techniques in improving the faithfulness of translations generated by LLMs, mitigating the issue of unfaithful translations.
Critical Analysis
The paper presents a thoughtful approach to addressing the challenge of unfaithful translations from large language models. The proposed techniques, such as source-aware training and document-level exploration, seem promising for improving the faithfulness of translations.
However, the paper does not discuss the potential limitations or caveats of these approaches. For example, it's unclear how scalable or computationally efficient the proposed methods are, or how they might perform in real-world scenarios with diverse source texts and language pairs.
Additionally, the paper does not explore the potential trade-offs between faithfulness and other desirable qualities, such as fluency or naturalness of the generated translations. It would be valuable to understand how the techniques balance these different objectives.
Further research could investigate the long-term impact of these approaches, particularly on the trustworthiness and reliability of LLM-generated translations in critical applications. Towards faithful and robust LLM specialists is an area that could provide valuable insights.
Overall, the paper presents a solid foundation for improving the faithfulness of LLM translations, but more work is needed to fully understand the practical implications and limitations of the proposed solutions.
Conclusion
This research paper explores innovative ways to enhance the faithfulness of translations generated by large language models (LLMs). The authors propose several techniques, such as source-aware training, document-level exploration, and the incorporation of additional contextual signals, to help LLMs better understand and preserve the meaning of the source text.
By focusing on the source context and finding ways to deepen the model's understanding, the researchers aim to mitigate the issue of unfaithful translations, where the generated output may not accurately reflect the original meaning. The proposed approaches show promising results and could have significant implications for the development of more trustworthy and reliable LLM-based translation systems.
As the use of LLMs continues to expand, ensuring the faithfulness of their outputs will be crucial, particularly in critical applications where accuracy and trustworthiness are paramount. This paper lays the groundwork for further research and development in this important area of language AI.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Paying More Attention to Source Context: Mitigating Unfaithful Translations from Large Language Model
Hongbin Zhang, Kehai Chen, Xuefeng Bai, Yang Xiang, Min Zhang
Large language models (LLMs) have showcased impressive multilingual machine translation ability. However, unlike encoder-decoder style models, decoder-only LLMs lack an explicit alignment between source and target contexts. Analyzing contribution scores during generation processes revealed that LLMs can be biased towards previously generated tokens over corresponding source tokens, leading to unfaithful translations. To address this issue, we propose to encourage LLMs to pay more attention to the source context from both source and target perspectives in zeroshot prompting: 1) adjust source context attention weights; 2) suppress irrelevant target prefix influence; Additionally, we propose 3) avoiding over-reliance on the target prefix in instruction tuning. Experimental results from both human-collected unfaithfulness test sets focusing on LLM-generated unfaithful translations and general test sets, verify our methods' effectiveness across multiple language pairs. Further human evaluation shows our method's efficacy in reducing hallucinatory translations and facilitating faithful translation generation.
Read more6/12/2024
💬
0
Lost in the Source Language: How Large Language Models Evaluate the Quality of Machine Translation
Xu Huang, Zhirui Zhang, Xiang Geng, Yichao Du, Jiajun Chen, Shujian Huang
This study investigates how Large Language Models (LLMs) leverage source and reference data in machine translation evaluation task, aiming to better understand the mechanisms behind their remarkable performance in this task. We design the controlled experiments across various input modes and model types, and employ both coarse-grained and fine-grained prompts to discern the utility of source versus reference information. We find that reference information significantly enhances the evaluation accuracy, while surprisingly, source information sometimes is counterproductive, indicating LLMs' inability to fully leverage the cross-lingual capability when evaluating translations. Further analysis of the fine-grained evaluation and fine-tuning experiments show similar results. These findings also suggest a potential research direction for LLMs that fully exploits the cross-lingual capability of LLMs to achieve better performance in machine translation evaluation tasks.
Read more6/7/2024
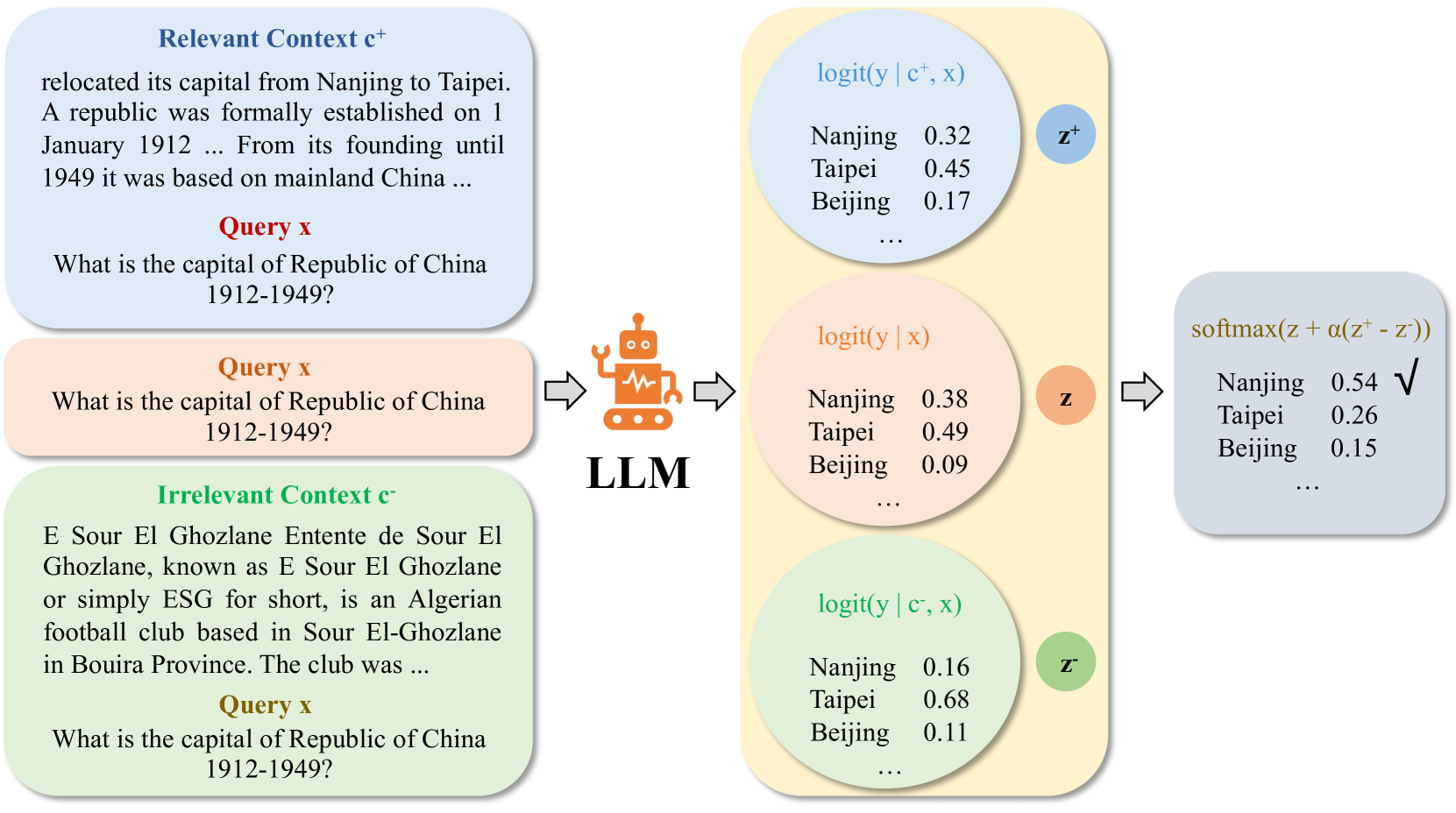
0
Enhancing Contextual Understanding in Large Language Models through Contrastive Decoding
Zheng Zhao, Emilio Monti, Jens Lehmann, Haytham Assem
Large language models (LLMs) tend to inadequately integrate input context during text generation, relying excessively on encoded prior knowledge in model parameters, potentially resulting in generated text with factual inconsistencies or contextually unfaithful content. LLMs utilize two primary knowledge sources: 1) prior (parametric) knowledge from pretraining, and 2) contextual (non-parametric) knowledge from input prompts. The study addresses the open question of how LLMs effectively balance these knowledge sources during the generation process, specifically in the context of open-domain question answering. To address this issue, we introduce a novel approach integrating contrastive decoding with adversarial irrelevant passages as negative samples to enhance robust context grounding during generation. Notably, our method operates at inference time without requiring further training. We conduct comprehensive experiments to demonstrate its applicability and effectiveness, providing empirical evidence showcasing its superiority over existing methodologies. Our code is publicly available at: https://github.com/amazon-science/ContextualUnderstanding-ContrastiveDecoding.
Read more5/7/2024

0
Identifying the Source of Generation for Large Language Models
Bumjin Park, Jaesik Choi
Large language models (LLMs) memorize text from several sources of documents. In pretraining, LLM trains to maximize the likelihood of text but neither receives the source of the text nor memorizes the source. Accordingly, LLM can not provide document information on the generated content, and users do not obtain any hint of reliability, which is crucial for factuality or privacy infringement. This work introduces token-level source identification in the decoding step, which maps the token representation to the reference document. We propose a bi-gram source identifier, a multi-layer perceptron with two successive token representations as input for better generalization. We conduct extensive experiments on Wikipedia and PG19 datasets with several LLMs, layer locations, and identifier sizes. The overall results show a possibility of token-level source identifiers for tracing the document, a crucial problem for the safe use of LLMs.
Read more7/19/2024