IDGenRec: LLM-RecSys Alignment with Textual ID Learning

0

Sign in to get full access
Overview
- This paper explores a method called "Textual ID Learning" to better align large language models (LLMs) with recommendation systems (RecSys).
- The key idea is to use text-based user and item representations to improve the personalization and accuracy of LLM-powered recommendation systems.
- The authors propose a framework that jointly learns textual user and item embeddings, which can then be used to enhance LLM-based recommendations.
Plain English Explanation
The paper is about finding a way to make large language models (LLMs) work better with recommendation systems (RecSys). LLMs are powerful AI models that can understand and generate human-like text, while RecSys are algorithms that suggest products, content, or information that users might be interested in.
The researchers think that by representing users and items (like products or articles) using textual information, they can improve the personalization and accuracy of LLM-powered recommendations. Their approach, called "Textual ID Learning," jointly learns embeddings (numerical representations) for both users and items based on the text associated with them.
These textual embeddings can then be used to enhance the recommendations made by the LLM. For example, the LLM might be able to better understand a user's interests and preferences by looking at the textual information in their profile, and then use that to suggest more relevant and personalized content.
The key idea is to bring together the strengths of LLMs, which are great at understanding and generating human-like text, with the personalization capabilities of RecSys, which can make tailored recommendations based on user preferences. By aligning these two technologies, the researchers hope to create recommendation systems that are more accurate, relevant, and helpful for users.
Technical Explanation
The paper proposes a framework called "Textual ID Learning" to better align large language models (LLMs) with recommendation systems (RecSys). The key components of this framework are:
-
Textual User and Item Embeddings: The method learns low-dimensional numerical representations (embeddings) of users and items based on the textual information associated with them, such as user profiles or item descriptions. These textual embeddings capture the semantic meaning and relationships between users and items.
-
Joint Optimization: The framework jointly optimizes the textual embeddings of users and items, as well as the recommendation model, in an end-to-end manner. This allows the textual representations to be tailored specifically for the recommendation task.
-
LLM Integration: The learned textual embeddings are then used to enhance the recommendation capabilities of the LLM. For example, the LLM can use the user and item embeddings to better understand user preferences and make more personalized suggestions.
The authors evaluate their approach on several benchmark datasets and show that it outperforms traditional RecSys methods, as well as approaches that use LLMs without the textual embedding component. The results demonstrate the benefits of aligning LLMs and RecSys through textual representations.
Critical Analysis
The paper presents a promising approach to improving the alignment between large language models and recommendation systems. The authors' key insight of using textual user and item embeddings to enhance LLM-powered recommendations is well-motivated and the experimental results are encouraging.
However, the paper does not address some potential limitations and areas for further research. For example, the authors do not discuss how the framework would scale to larger, more complex datasets or how it would handle cold-start scenarios where little textual information is available for new users or items.
Additionally, the paper does not provide a deeper exploration of the learned textual embeddings and how they capture the nuanced relationships between users and items. A more detailed analysis of these representations and their interpretability could provide additional insights into the workings of the system.
Future research could also investigate the robustness of the Textual ID Learning framework to noisy or incomplete textual data, as well as explore ways to extend the approach to incorporate other modalities beyond text, such as images or user interactions.
Conclusion
This paper presents a novel approach called "Textual ID Learning" that aims to better align large language models (LLMs) with recommendation systems (RecSys). By jointly learning textual embeddings for users and items, the framework can enhance the personalization and accuracy of LLM-powered recommendations.
The key contribution of this work is the insight that bridging the gap between the strengths of LLMs (in understanding and generating human-like text) and the personalization capabilities of RecSys can lead to more effective recommendation systems. The experimental results demonstrate the benefits of this approach, and the authors have laid the groundwork for further research in this area.
As language models continue to advance and become increasingly integrated into various applications, the Textual ID Learning framework offers a promising direction for aligning these powerful AI systems with personalized recommendation tasks, ultimately leading to more engaging and relevant user experiences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
IDGenRec: LLM-RecSys Alignment with Textual ID Learning
Juntao Tan, Shuyuan Xu, Wenyue Hua, Yingqiang Ge, Zelong Li, Yongfeng Zhang
Generative recommendation based on Large Language Models (LLMs) have transformed the traditional ranking-based recommendation style into a text-to-text generation paradigm. However, in contrast to standard NLP tasks that inherently operate on human vocabulary, current research in generative recommendations struggles to effectively encode recommendation items within the text-to-text framework using concise yet meaningful ID representations. To better align LLMs with recommendation needs, we propose IDGen, representing each item as a unique, concise, semantically rich, platform-agnostic textual ID using human language tokens. This is achieved by training a textual ID generator alongside the LLM-based recommender, enabling seamless integration of personalized recommendations into natural language generation. Notably, as user history is expressed in natural language and decoupled from the original dataset, our approach suggests the potential for a foundational generative recommendation model. Experiments show that our framework consistently surpasses existing models in sequential recommendation under standard experimental setting. Then, we explore the possibility of training a foundation recommendation model with the proposed method on data collected from 19 different datasets and tested its recommendation performance on 6 unseen datasets across different platforms under a completely zero-shot setting. The results show that the zero-shot performance of the pre-trained foundation model is comparable to or even better than some traditional recommendation models based on supervised training, showing the potential of the IDGen paradigm serving as the foundation model for generative recommendation. Code and data are open-sourced at https://github.com/agiresearch/IDGenRec.
Read more5/20/2024

0
TokenRec: Learning to Tokenize ID for LLM-based Generative Recommendation
Haohao Qu, Wenqi Fan, Zihuai Zhao, Qing Li
There is a growing interest in utilizing large-scale language models (LLMs) to advance next-generation Recommender Systems (RecSys), driven by their outstanding language understanding and in-context learning capabilities. In this scenario, tokenizing (i.e., indexing) users and items becomes essential for ensuring a seamless alignment of LLMs with recommendations. While several studies have made progress in representing users and items through textual contents or latent representations, challenges remain in efficiently capturing high-order collaborative knowledge into discrete tokens that are compatible with LLMs. Additionally, the majority of existing tokenization approaches often face difficulties in generalizing effectively to new/unseen users or items that were not in the training corpus. To address these challenges, we propose a novel framework called TokenRec, which introduces not only an effective ID tokenization strategy but also an efficient retrieval paradigm for LLM-based recommendations. Specifically, our tokenization strategy, Masked Vector-Quantized (MQ) Tokenizer, involves quantizing the masked user/item representations learned from collaborative filtering into discrete tokens, thus achieving a smooth incorporation of high-order collaborative knowledge and a generalizable tokenization of users and items for LLM-based RecSys. Meanwhile, our generative retrieval paradigm is designed to efficiently recommend top-$K$ items for users to eliminate the need for the time-consuming auto-regressive decoding and beam search processes used by LLMs, thus significantly reducing inference time. Comprehensive experiments validate the effectiveness of the proposed methods, demonstrating that TokenRec outperforms competitive benchmarks, including both traditional recommender systems and emerging LLM-based recommender systems.
Read more8/20/2024
💬
0
Adapting Large Language Models by Integrating Collaborative Semantics for Recommendation
Bowen Zheng, Yupeng Hou, Hongyu Lu, Yu Chen, Wayne Xin Zhao, Ming Chen, Ji-Rong Wen
Recently, large language models (LLMs) have shown great potential in recommender systems, either improving existing recommendation models or serving as the backbone. However, there exists a large semantic gap between LLMs and recommender systems, since items to be recommended are often indexed by discrete identifiers (item ID) out of the LLM's vocabulary. In essence, LLMs capture language semantics while recommender systems imply collaborative semantics, making it difficult to sufficiently leverage the model capacity of LLMs for recommendation. To address this challenge, in this paper, we propose a new LLM-based recommendation model called LC-Rec, which can better integrate language and collaborative semantics for recommender systems. Our approach can directly generate items from the entire item set for recommendation, without relying on candidate items. Specifically, we make two major contributions in our approach. For item indexing, we design a learning-based vector quantization method with uniform semantic mapping, which can assign meaningful and non-conflicting IDs (called item indices) for items. For alignment tuning, we propose a series of specially designed tuning tasks to enhance the integration of collaborative semantics in LLMs. Our fine-tuning tasks enforce LLMs to deeply integrate language and collaborative semantics (characterized by the learned item indices), so as to achieve an effective adaptation to recommender systems. Extensive experiments demonstrate the effectiveness of our method, showing that our approach can outperform a number of competitive baselines including traditional recommenders and existing LLM-based recommenders. Our code is available at https://github.com/RUCAIBox/LC-Rec/.
Read more4/22/2024
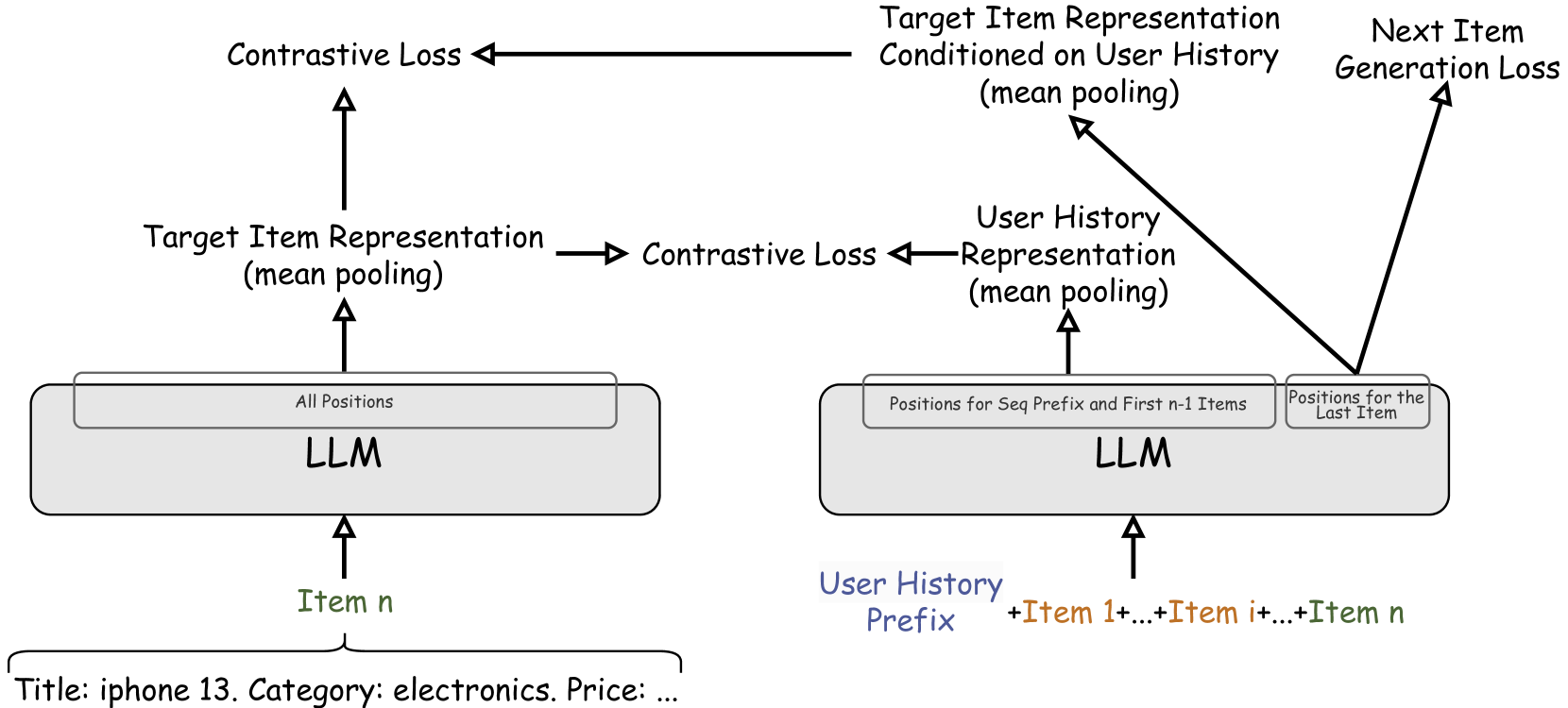
0
CALRec: Contrastive Alignment of Generative LLMs For Sequential Recommendation
Yaoyiran Li, Xiang Zhai, Moustafa Alzantot, Keyi Yu, Ivan Vuli'c, Anna Korhonen, Mohamed Hammad
Traditional recommender systems such as matrix factorization methods have primarily focused on learning a shared dense embedding space to represent both items and user preferences. Subsequently, sequence models such as RNN, GRUs, and, recently, Transformers have emerged and excelled in the task of sequential recommendation. This task requires understanding the sequential structure present in users' historical interactions to predict the next item they may like. Building upon the success of Large Language Models (LLMs) in a variety of tasks, researchers have recently explored using LLMs that are pretrained on vast corpora of text for sequential recommendation. To use LLMs for sequential recommendation, both the history of user interactions and the model's prediction of the next item are expressed in text form. We propose CALRec, a two-stage LLM finetuning framework that finetunes a pretrained LLM in a two-tower fashion using a mixture of two contrastive losses and a language modeling loss: the LLM is first finetuned on a data mixture from multiple domains followed by another round of target domain finetuning. Our model significantly outperforms many state-of-the-art baselines (+37% in Recall@1 and +24% in NDCG@10) and our systematic ablation studies reveal that (i) both stages of finetuning are crucial, and, when combined, we achieve improved performance, and (ii) contrastive alignment is effective among the target domains explored in our experiments.
Read more8/27/2024