II-MMR: Identifying and Improving Multi-modal Multi-hop Reasoning in Visual Question Answering
2402.11058
0
0

Abstract
Visual Question Answering (VQA) often involves diverse reasoning scenarios across Vision and Language (V&L). Most prior VQA studies, however, have merely focused on assessing the model's overall accuracy without evaluating it on different reasoning cases. Furthermore, some recent works observe that conventional Chain-of-Thought (CoT) prompting fails to generate effective reasoning for VQA, especially for complex scenarios requiring multi-hop reasoning. In this paper, we propose II-MMR, a novel idea to identify and improve multi-modal multi-hop reasoning in VQA. In specific, II-MMR takes a VQA question with an image and finds a reasoning path to reach its answer using two novel language promptings: (i) answer prediction-guided CoT prompt, or (ii) knowledge triplet-guided prompt. II-MMR then analyzes this path to identify different reasoning cases in current VQA benchmarks by estimating how many hops and what types (i.e., visual or beyond-visual) of reasoning are required to answer the question. On popular benchmarks including GQA and A-OKVQA, II-MMR observes that most of their VQA questions are easy to answer, simply demanding single-hop reasoning, whereas only a few questions require multi-hop reasoning. Moreover, while the recent V&L model struggles with such complex multi-hop reasoning questions even using the traditional CoT method, II-MMR shows its effectiveness across all reasoning cases in both zero-shot and fine-tuning settings.
Create account to get full access
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
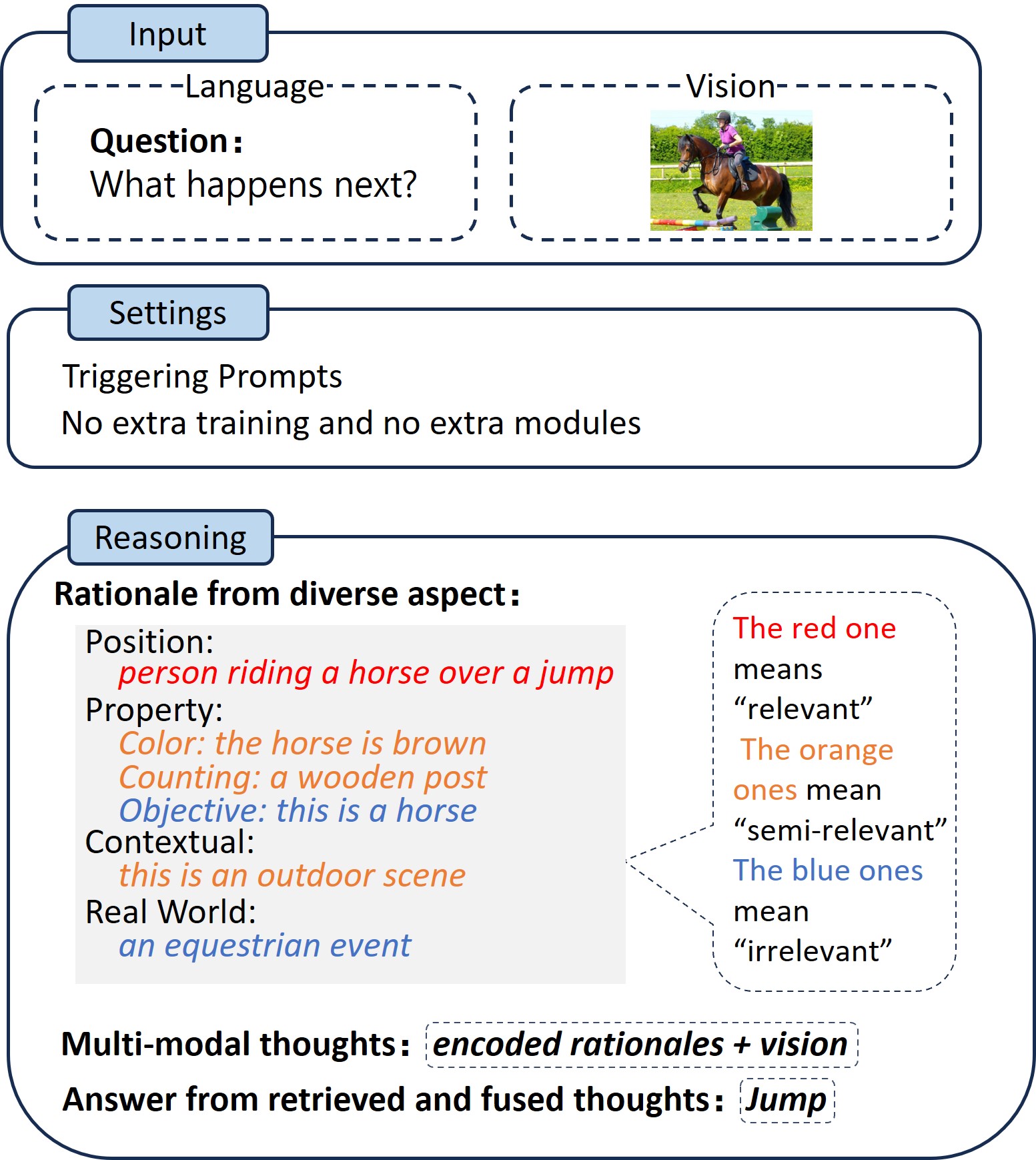
Mixture of Rationale: Multi-Modal Reasoning Mixture for Visual Question Answering
Tao Li, Linjun Shou, Xuejun Liu
0
0
Zero-shot visual question answering (VQA) is a challenging task that requires reasoning across modalities. While some existing methods rely on a single rationale within the Chain of Thoughts (CoT) framework, they may fall short of capturing the complexity of the VQA problem. On the other hand, some other methods that use multiple rationales may still suffer from low diversity, poor modality alignment, and inefficient retrieval and fusion. In response to these challenges, we propose emph{Mixture of Rationales (MoR)}, a novel multi-modal reasoning method that mixes multiple rationales for VQA. MoR uses a single frozen Vision-and-Language Pre-trained Models (VLPM) model to {dynamically generate, retrieve and fuse multi-modal thoughts}. We evaluate MoR on two challenging VQA datasets, i.e. NLVR2 and OKVQA, with two representative backbones OFA and VL-T5. MoR achieves a 12.43% accuracy improvement on NLVR2, and a 2.45% accuracy improvement on OKVQA-S( the science and technology category of OKVQA).
6/4/2024
💬
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
0
0
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
5/21/2024

MM-PhyQA: Multimodal Physics Question-Answering With Multi-Image CoT Prompting
Avinash Anand, Janak Kapuriya, Apoorv Singh, Jay Saraf, Naman Lal, Astha Verma, Rushali Gupta, Rajiv Shah
0
0
While Large Language Models (LLMs) can achieve human-level performance in various tasks, they continue to face challenges when it comes to effectively tackling multi-step physics reasoning tasks. To identify the shortcomings of existing models and facilitate further research in this area, we curated a novel dataset, MM-PhyQA, which comprises well-constructed, high schoollevel multimodal physics problems. By evaluating the performance of contemporary LLMs that are publicly available, both with and without the incorporation of multimodal elements in these problems, we aim to shed light on their capabilities. For generating answers for questions consisting of multimodal input (in this case, images and text) we employed Zero-shot prediction using GPT-4 and utilized LLaVA (LLaVA and LLaVA-1.5), the latter of which were fine-tuned on our dataset. For evaluating the performance of LLMs consisting solely of textual input, we tested the performance of the base and fine-tuned versions of the Mistral-7B and LLaMA2-7b models. We also showcased the performance of the novel Multi-Image Chain-of-Thought (MI-CoT) Prompting technique, which when used to train LLaVA-1.5 13b yielded the best results when tested on our dataset, with superior scores in most metrics and the highest accuracy of 71.65% on the test set.
4/16/2024

Retrieval Meets Reasoning: Even High-school Textbook Knowledge Benefits Multimodal Reasoning
Cheng Tan, Jingxuan Wei, Linzhuang Sun, Zhangyang Gao, Siyuan Li, Bihui Yu, Ruifeng Guo, Stan Z. Li
0
0
Large language models equipped with retrieval-augmented generation (RAG) represent a burgeoning field aimed at enhancing answering capabilities by leveraging external knowledge bases. Although the application of RAG with language-only models has been extensively explored, its adaptation into multimodal vision-language models remains nascent. Going beyond mere answer generation, the primary goal of multimodal RAG is to cultivate the models' ability to reason in response to relevant queries. To this end, we introduce a novel multimodal RAG framework named RMR (Retrieval Meets Reasoning). The RMR framework employs a bi-modal retrieval module to identify the most relevant question-answer pairs, which then serve as scaffolds for the multimodal reasoning process. This training-free approach not only encourages the model to engage deeply with the reasoning processes inherent in the retrieved content but also facilitates the generation of answers that are precise and richly interpretable. Surprisingly, utilizing solely the ScienceQA dataset, collected from elementary and high school science curricula, RMR significantly boosts the performance of various vision-language models across a spectrum of benchmark datasets, including A-OKVQA, MMBench, and SEED. These outcomes highlight the substantial potential of our multimodal retrieval and reasoning mechanism to improve the reasoning capabilities of vision-language models.
6/3/2024