Mixture of Rationale: Multi-Modal Reasoning Mixture for Visual Question Answering
2406.01402
0
0
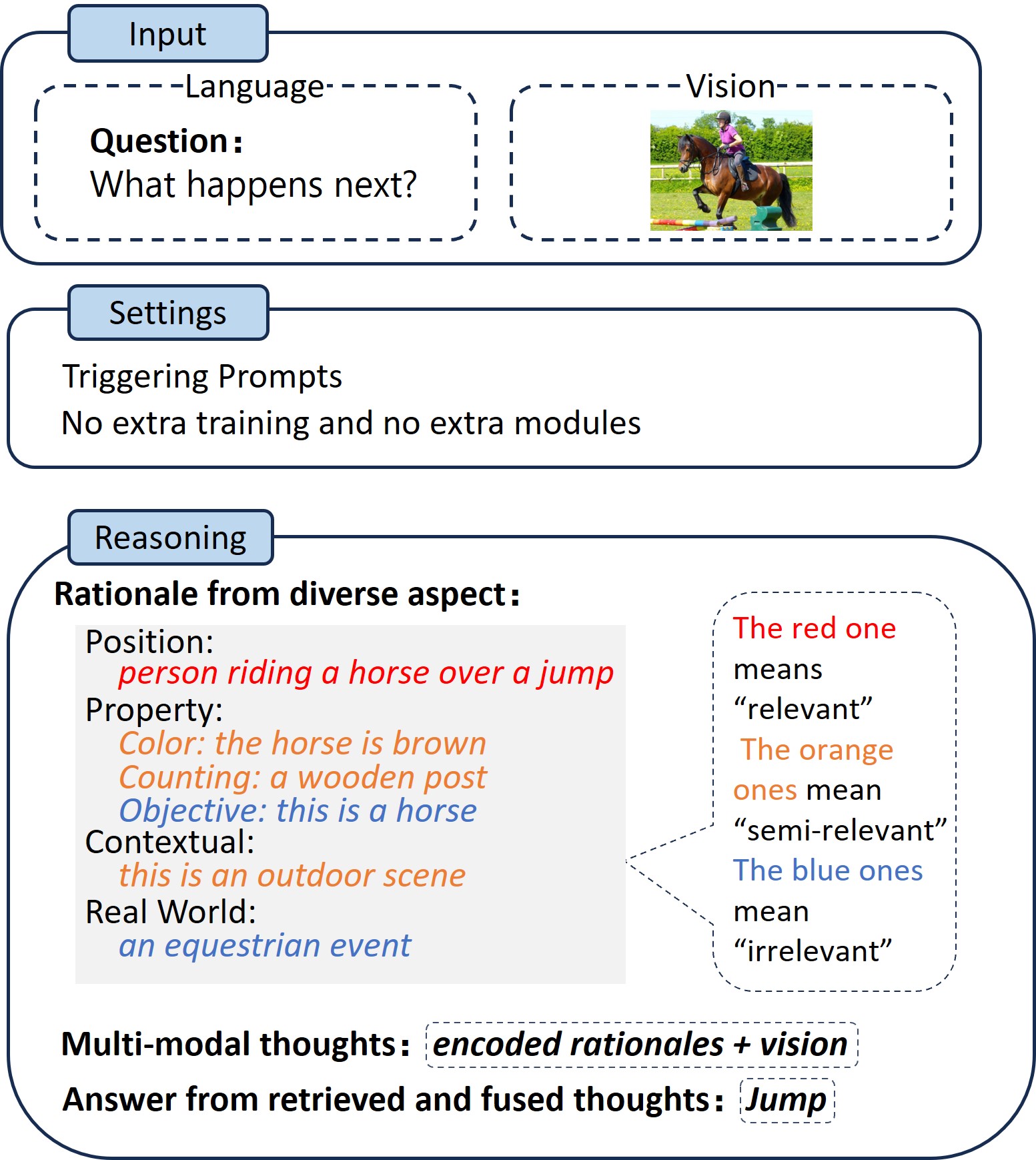
Abstract
Zero-shot visual question answering (VQA) is a challenging task that requires reasoning across modalities. While some existing methods rely on a single rationale within the Chain of Thoughts (CoT) framework, they may fall short of capturing the complexity of the VQA problem. On the other hand, some other methods that use multiple rationales may still suffer from low diversity, poor modality alignment, and inefficient retrieval and fusion. In response to these challenges, we propose emph{Mixture of Rationales (MoR)}, a novel multi-modal reasoning method that mixes multiple rationales for VQA. MoR uses a single frozen Vision-and-Language Pre-trained Models (VLPM) model to {dynamically generate, retrieve and fuse multi-modal thoughts}. We evaluate MoR on two challenging VQA datasets, i.e. NLVR2 and OKVQA, with two representative backbones OFA and VL-T5. MoR achieves a 12.43% accuracy improvement on NLVR2, and a 2.45% accuracy improvement on OKVQA-S( the science and technology category of OKVQA).
Create account to get full access
Overview
- This paper introduces a "Mixture of Rationale" (MoR) model for Visual Question Answering (VQA), which combines multiple reasoning mechanisms to answer questions about images.
- The model learns to dynamically select the most appropriate reasoning approach for a given question-image pair, drawing from a mixture of different reasoning modules.
- This allows the model to leverage distinct reasoning capabilities to tackle a wide range of VQA tasks, from visual recognition to commonsense reasoning.
Plain English Explanation
The researchers developed a new AI model called "Mixture of Rationale" (MoR) that is designed to answer questions about images. Most existing VQA models use a single, fixed reasoning approach, but the MoR model is more flexible - it can dynamically choose the best reasoning strategy for each question.
The model has several different "reasoning modules" that excel at different types of tasks, like recognizing objects in the image, understanding the relationship between elements, or applying common sense knowledge. When a new question is asked, the MoR model evaluates the question and image, then selects the most appropriate reasoning module or combination of modules to generate the answer.
This allows the MoR model to handle a wider variety of question types compared to models with a single reasoning approach. It can tackle questions that require visual recognition, logical reasoning, commonsense understanding, and other cognitive skills. By combining multiple reasoning capabilities, the model can provide more accurate and comprehensive answers.
The researchers tested the MoR model on standard VQA benchmarks and found that it outperformed state-of-the-art single-reasoning VQA models. This suggests the "mixture of rationale" approach is a promising direction for building more versatile and robust visual question answering systems.
Technical Explanation
The key innovation in this work is the Mixture of Rationale (MoR) model for Visual Question Answering (VQA). Rather than relying on a single reasoning mechanism, the MoR model learns to dynamically select the most appropriate reasoning approach from a mixture of specialized modules.
These reasoning modules include visual recognition (to detect objects, attributes, etc.), language understanding (to comprehend the question), commonsense reasoning, and other capabilities. The model evaluates the question and image, then chooses the optimal combination of modules to generate the final answer.
This multi-modal, multi-task approach allows the MoR model to tackle a broad range of VQA challenges, from pure visual recognition to higher-level reasoning tasks that require semantic understanding and commonsense inferences.
The researchers evaluated the MoR model on several VQA benchmarks and found that it outperformed state-of-the-art single-reasoning VQA models. This demonstrates the value of the "mixture of rationale" approach in building more versatile and powerful question answering systems.
Critical Analysis
While the MoR model shows promising results, the paper acknowledges some limitations and areas for future work. For example, the model's dynamic module selection process is not fully interpretable, so it can be difficult to understand why certain reasoning approaches were chosen for a given question.
Additionally, the paper does not explore the model's performance on more open-ended or complex VQA tasks that may require even more sophisticated reasoning capabilities. Expanding the range of reasoning modules and testing the model's generalization to novel domains could be valuable avenues for further research.
It would also be interesting to see how the MoR approach compares to other multi-modal, multi-task architectures, such as those that incorporate language model-based chain-of-thought reasoning. A more thorough evaluation and comparison to other state-of-the-art models could provide additional insights into the strengths and weaknesses of the MoR approach.
Conclusion
The Mixture of Rationale (MoR) model proposed in this paper represents an important step forward in Visual Question Answering. By dynamically selecting the most appropriate reasoning approach for each question-image pair, the model can leverage diverse cognitive capabilities to answer a wide range of VQA queries.
The promising results on standard benchmarks suggest that the "mixture of rationale" approach is a valuable direction for building more versatile and robust question answering systems. As the field of AI continues to advance, models like MoR that can fluidly combine multiple reasoning strategies may play an increasingly important role in developing AI systems that can truly understand and interact with the world like humans.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

II-MMR: Identifying and Improving Multi-modal Multi-hop Reasoning in Visual Question Answering
Jihyung Kil, Farideh Tavazoee, Dongyeop Kang, Joo-Kyung Kim
0
0
Visual Question Answering (VQA) often involves diverse reasoning scenarios across Vision and Language (V&L). Most prior VQA studies, however, have merely focused on assessing the model's overall accuracy without evaluating it on different reasoning cases. Furthermore, some recent works observe that conventional Chain-of-Thought (CoT) prompting fails to generate effective reasoning for VQA, especially for complex scenarios requiring multi-hop reasoning. In this paper, we propose II-MMR, a novel idea to identify and improve multi-modal multi-hop reasoning in VQA. In specific, II-MMR takes a VQA question with an image and finds a reasoning path to reach its answer using two novel language promptings: (i) answer prediction-guided CoT prompt, or (ii) knowledge triplet-guided prompt. II-MMR then analyzes this path to identify different reasoning cases in current VQA benchmarks by estimating how many hops and what types (i.e., visual or beyond-visual) of reasoning are required to answer the question. On popular benchmarks including GQA and A-OKVQA, II-MMR observes that most of their VQA questions are easy to answer, simply demanding single-hop reasoning, whereas only a few questions require multi-hop reasoning. Moreover, while the recent V&L model struggles with such complex multi-hop reasoning questions even using the traditional CoT method, II-MMR shows its effectiveness across all reasoning cases in both zero-shot and fine-tuning settings.
6/4/2024
💬
MedThink: Explaining Medical Visual Question Answering via Multimodal Decision-Making Rationale
Xiaotang Gai, Chenyi Zhou, Jiaxiang Liu, Yang Feng, Jian Wu, Zuozhu Liu
0
0
Medical Visual Question Answering (MedVQA), which offers language responses to image-based medical inquiries, represents a challenging task and significant advancement in healthcare. It assists medical experts to swiftly interpret medical images, thereby enabling faster and more accurate diagnoses. However, the model interpretability and transparency of existing MedVQA solutions are often limited, posing challenges in understanding their decision-making processes. To address this issue, we devise a semi-automated annotation process to streamlining data preparation and build new benchmark MedVQA datasets R-RAD and R-SLAKE. The R-RAD and R-SLAKE datasets provide intermediate medical decision-making rationales generated by multimodal large language models and human annotations for question-answering pairs in existing MedVQA datasets, i.e., VQA-RAD and SLAKE. Moreover, we design a novel framework which finetunes lightweight pretrained generative models by incorporating medical decision-making rationales into the training process. The framework includes three distinct strategies to generate decision outcomes and corresponding rationales, thereby clearly showcasing the medical decision-making process during reasoning. Extensive experiments demonstrate that our method can achieve an accuracy of 83.5% on R-RAD and 86.3% on R-SLAKE, significantly outperforming existing state-of-the-art baselines. Dataset and code will be released.
4/19/2024

Retrieval Meets Reasoning: Even High-school Textbook Knowledge Benefits Multimodal Reasoning
Cheng Tan, Jingxuan Wei, Linzhuang Sun, Zhangyang Gao, Siyuan Li, Bihui Yu, Ruifeng Guo, Stan Z. Li
0
0
Large language models equipped with retrieval-augmented generation (RAG) represent a burgeoning field aimed at enhancing answering capabilities by leveraging external knowledge bases. Although the application of RAG with language-only models has been extensively explored, its adaptation into multimodal vision-language models remains nascent. Going beyond mere answer generation, the primary goal of multimodal RAG is to cultivate the models' ability to reason in response to relevant queries. To this end, we introduce a novel multimodal RAG framework named RMR (Retrieval Meets Reasoning). The RMR framework employs a bi-modal retrieval module to identify the most relevant question-answer pairs, which then serve as scaffolds for the multimodal reasoning process. This training-free approach not only encourages the model to engage deeply with the reasoning processes inherent in the retrieved content but also facilitates the generation of answers that are precise and richly interpretable. Surprisingly, utilizing solely the ScienceQA dataset, collected from elementary and high school science curricula, RMR significantly boosts the performance of various vision-language models across a spectrum of benchmark datasets, including A-OKVQA, MMBench, and SEED. These outcomes highlight the substantial potential of our multimodal retrieval and reasoning mechanism to improve the reasoning capabilities of vision-language models.
6/3/2024

Rationale-based Ensemble of Multiple QA Strategies for Zero-shot Knowledge-based VQA
Miaoyu Li, Haoxin Li, Zilin Du, Boyang Li
0
0
Knowledge-based Visual Qustion-answering (K-VQA) necessitates the use of background knowledge beyond what is depicted in the image. Current zero-shot K-VQA methods usually translate an image to a single type of textual decision context and use a text-based model to answer the question based on it, which conflicts with the fact that K-VQA questions often require the combination of multiple question-answering strategies. In light of this, we propose Rationale-based Ensemble of Answer Context Tactics (REACT) to achieve a dynamic ensemble of multiple question-answering tactics, comprising Answer Candidate Generation (ACG) and Rationale-based Strategy Fusion (RSF). In ACG, we generate three distinctive decision contexts to provide different strategies for each question, resulting in the generation of three answer candidates. RSF generates automatic and mechanistic rationales from decision contexts for each candidate, allowing the model to select the correct answer from all candidates. We conduct comprehensive experiments on the OK-VQA and A-OKVQA datasets, and our method significantly outperforms state-of-the-art LLM-based baselines on all datasets.
6/26/2024