IIDM: Image-to-Image Diffusion Model for Semantic Image Synthesis

0

Sign in to get full access
Overview
- This paper presents a novel Image-to-Image Diffusion Model (IIDM) for semantic image synthesis.
- IIDM combines the strengths of diffusion models and conditional image generation to generate high-quality images from semantic segmentation maps.
- The model introduces several key innovations, including a mixed sampling strategy and a domain-agnostic architecture, to improve performance.
Plain English Explanation
IIDM: Image-to-Image Diffusion Model for Semantic Image Synthesis is a new technique for generating realistic images from simple sketches or segmentation maps. Traditional image generation models often struggle to create visually appealing results from these basic input formats.
The researchers behind IIDM have developed a novel approach that combines the strengths of two powerful machine learning techniques: diffusion models and conditional image generation. Diffusion models excel at generating high-quality, diverse images, but can be difficult to control. Conditional models, on the other hand, allow for more precise control over the output, but may not produce results as realistic or varied.
IIDM aims to get the best of both worlds. By carefully integrating these two paradigms, the model can generate vivid, context-aware images from simple semantic inputs like segmentation maps. Some of the key innovations include a mixed sampling strategy that blends different techniques to improve quality and diversity, and a domain-agnostic architecture that allows the model to work well across a wide range of datasets and tasks.
Overall, IIDM represents an exciting advance in the field of generative AI, pushing the boundaries of what's possible in terms of transforming basic sketches and outlines into compelling, photorealistic imagery.
Technical Explanation
IIDM: Image-to-Image Diffusion Model for Semantic Image Synthesis introduces a novel diffusion-based approach for conditional image generation, known as the Image-to-Image Diffusion Model (IIDM). The key innovations of IIDM include:
-
Mixed Sampling Strategy: IIDM employs a mixed sampling strategy that combines the strengths of different sampling techniques, such as latent diffusion and progressive distillation, to improve the quality and diversity of the generated images.
-
Domain-Agnostic Architecture: The IIDM architecture is designed to be domain-agnostic, allowing the model to be applied to a wide range of semantic image synthesis tasks without the need for extensive task-specific fine-tuning.
-
Improved Semantic Fidelity: IIDM demonstrates significant improvements in preserving the semantic fidelity of the input segmentation maps compared to previous conditional diffusion models.
The paper presents extensive experiments on several benchmarks, including Cityscapes, ADE20K, and COCO-Stuff, showcasing IIDM's superior performance in terms of image quality, semantic fidelity, and task-agnostic generalization compared to state-of-the-art conditional image synthesis models.
Critical Analysis
The IIDM: Image-to-Image Diffusion Model for Semantic Image Synthesis paper presents a compelling approach to semantic image synthesis, but there are a few potential limitations and areas for further research:
-
Computational Efficiency: While IIDM demonstrates impressive performance, the authors acknowledge that the model can be computationally intensive, particularly during training. Further optimizations to improve efficiency may be necessary for real-world deployment.
-
Generalization Across Datasets: The paper focuses on evaluating IIDM on a few well-known datasets, but it would be valuable to explore the model's performance on a wider range of datasets and domains to fully assess its generalization capabilities.
-
Robustness to Imperfect Inputs: The paper primarily evaluates IIDM on clean, high-quality segmentation maps as input. It would be interesting to see how the model performs when faced with noisy or incomplete input data, which is more representative of real-world scenarios.
-
Interpretability and Controllability: As with many deep learning models, the inner workings of IIDM may be opaque. Exploring ways to improve the interpretability and controllability of the model's outputs could enhance its practical applications.
Overall, the IIDM: Image-to-Image Diffusion Model for Semantic Image Synthesis paper presents a significant advancement in the field of generative AI, with promising results that warrant further investigation and refinement.
Conclusion
The IIDM: Image-to-Image Diffusion Model for Semantic Image Synthesis paper introduces a novel diffusion-based approach for conditional image generation that combines the strengths of diffusion models and conditional image generation. The key innovations of IIDM, including its mixed sampling strategy and domain-agnostic architecture, enable the model to generate high-quality, semantically-coherent images from simple segmentation maps.
The impressive results demonstrated by IIDM on various benchmarks suggest that this approach has the potential to significantly advance the field of generative AI, with applications ranging from digital art creation to computer-aided design. While the model has some limitations in terms of computational efficiency and robustness to imperfect inputs, the research team's thoughtful approach and the model's strong performance indicate that IIDM is a promising step forward in the quest for more versatile and controllable image synthesis systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
IIDM: Image-to-Image Diffusion Model for Semantic Image Synthesis
Feng Liu, Xiaobin Chang
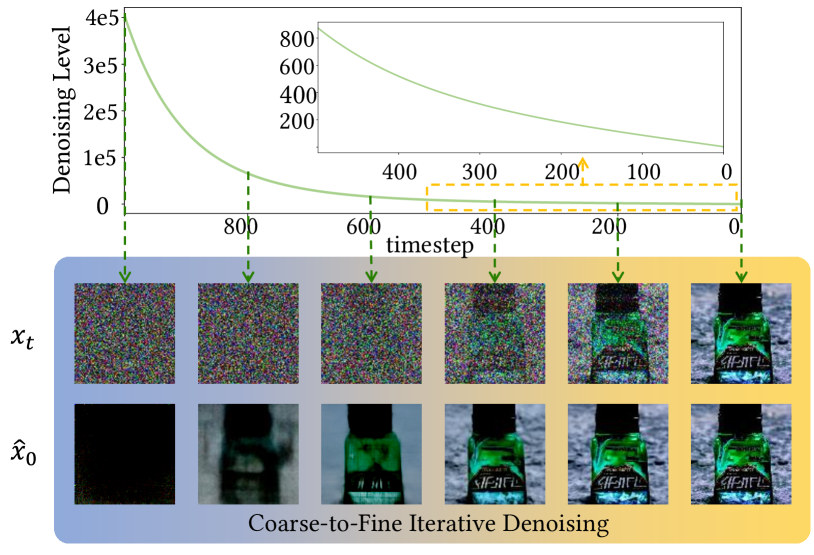
Semantic image synthesis aims to generate high-quality images given semantic conditions, i.e. segmentation masks and style reference images. Existing methods widely adopt generative adversarial networks (GANs). GANs take all conditional inputs and directly synthesize images in a single forward step. In this paper, semantic image synthesis is treated as an image denoising task and is handled with a novel image-to-image diffusion model (IIDM). Specifically, the style reference is first contaminated with random noise and then progressively denoised by IIDM, guided by segmentation masks. Moreover, three techniques, refinement, color-transfer and model ensembles, are proposed to further boost the generation quality. They are plug-in inference modules and do not require additional training. Extensive experiments show that our IIDM outperforms existing state-of-the-art methods by clear margins. Further analysis is provided via detailed demonstrations. We have implemented IIDM based on the Jittor framework; code is available at https://github.com/ader47/jittor-jieke-semantic_images_synthesis.
Read more8/21/2024
0
Stimulating the Diffusion Model for Image Denoising via Adaptive Embedding and Ensembling
Tong Li, Hansen Feng, Lizhi Wang, Zhiwei Xiong, Hua Huang
Image denoising is a fundamental problem in computational photography, where achieving high perception with low distortion is highly demanding. Current methods either struggle with perceptual quality or suffer from significant distortion. Recently, the emerging diffusion model has achieved state-of-the-art performance in various tasks and demonstrates great potential for image denoising. However, stimulating diffusion models for image denoising is not straightforward and requires solving several critical problems. For one thing, the input inconsistency hinders the connection between diffusion models and image denoising. For another, the content inconsistency between the generated image and the desired denoised image introduces distortion. To tackle these problems, we present a novel strategy called the Diffusion Model for Image Denoising (DMID) by understanding and rethinking the diffusion model from a denoising perspective. Our DMID strategy includes an adaptive embedding method that embeds the noisy image into a pre-trained unconditional diffusion model and an adaptive ensembling method that reduces distortion in the denoised image. Our DMID strategy achieves state-of-the-art performance on both distortion-based and perception-based metrics, for both Gaussian and real-world image denoising.The code is available at https://github.com/Li-Tong-621/DMID.
Read more4/16/2024
0
DGInStyle: Domain-Generalizable Semantic Segmentation with Image Diffusion Models and Stylized Semantic Control
Yuru Jia, Lukas Hoyer, Shengyu Huang, Tianfu Wang, Luc Van Gool, Konrad Schindler, Anton Obukhov
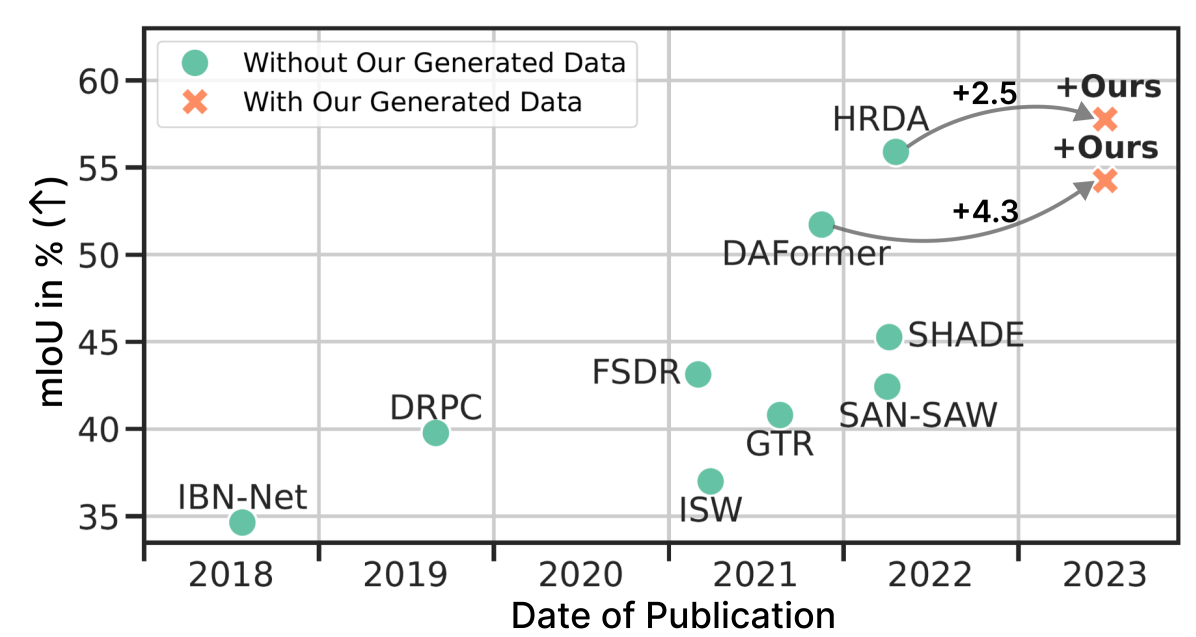
Large, pretrained latent diffusion models (LDMs) have demonstrated an extraordinary ability to generate creative content, specialize to user data through few-shot fine-tuning, and condition their output on other modalities, such as semantic maps. However, are they usable as large-scale data generators, e.g., to improve tasks in the perception stack, like semantic segmentation? We investigate this question in the context of autonomous driving, and answer it with a resounding yes. We propose an efficient data generation pipeline termed DGInStyle. First, we examine the problem of specializing a pretrained LDM to semantically-controlled generation within a narrow domain. Second, we propose a Style Swap technique to endow the rich generative prior with the learned semantic control. Third, we design a Multi-resolution Latent Fusion technique to overcome the bias of LDMs towards dominant objects. Using DGInStyle, we generate a diverse dataset of street scenes, train a domain-agnostic semantic segmentation model on it, and evaluate the model on multiple popular autonomous driving datasets. Our approach consistently increases the performance of several domain generalization methods compared to the previous state-of-the-art methods. The source code and the generated dataset are available at https://dginstyle.github.io.
Read more8/1/2024
🖼️
0
Stochastic Conditional Diffusion Models for Robust Semantic Image Synthesis
Juyeon Ko, Inho Kong, Dogyun Park, Hyunwoo J. Kim
Semantic image synthesis (SIS) is a task to generate realistic images corresponding to semantic maps (labels). However, in real-world applications, SIS often encounters noisy user inputs. To address this, we propose Stochastic Conditional Diffusion Model (SCDM), which is a robust conditional diffusion model that features novel forward and generation processes tailored for SIS with noisy labels. It enhances robustness by stochastically perturbing the semantic label maps through Label Diffusion, which diffuses the labels with discrete diffusion. Through the diffusion of labels, the noisy and clean semantic maps become similar as the timestep increases, eventually becoming identical at $t=T$. This facilitates the generation of an image close to a clean image, enabling robust generation. Furthermore, we propose a class-wise noise schedule to differentially diffuse the labels depending on the class. We demonstrate that the proposed method generates high-quality samples through extensive experiments and analyses on benchmark datasets, including a novel experimental setup simulating human errors during real-world applications. Code is available at https://github.com/mlvlab/SCDM.
Read more6/4/2024