An Image is Worth Multiple Words: Discovering Object Level Concepts using Multi-Concept Prompt Learning
2310.12274
0
0

Abstract
Textural Inversion, a prompt learning method, learns a singular text embedding for a new word to represent image style and appearance, allowing it to be integrated into natural language sentences to generate novel synthesised images. However, identifying multiple unknown object-level concepts within one scene remains a complex challenge. While recent methods have resorted to cropping or masking individual images to learn multiple concepts, these techniques often require prior knowledge of new concepts and are labour-intensive. To address this challenge, we introduce Multi-Concept Prompt Learning (MCPL), where multiple unknown words are simultaneously learned from a single sentence-image pair, without any imagery annotations. To enhance the accuracy of word-concept correlation and refine attention mask boundaries, we propose three regularisation techniques: Attention Masking, Prompts Contrastive Loss, and Bind Adjective. Extensive quantitative comparisons with both real-world categories and biomedical images demonstrate that our method can learn new semantically disentangled concepts. Our approach emphasises learning solely from textual embeddings, using less than 10% of the storage space compared to others. The project page, code, and data are available at https://astrazeneca.github.io/mcpl.github.io.
Create account to get full access
Overview
- This paper presents a novel approach called "Multi-Concept Prompt Learning" (MCPL) that enables language models to learn object-level concepts from images.
- MCPL trains language models to generate multi-word prompts that can accurately describe the objects present in an image, going beyond simple single-word labels.
- The method leverages a combination of image-text pairs and a constrained optimization process to learn prompts that capture nuanced object-level details.
Plain English Explanation
The researchers developed a new technique called "Multi-Concept Prompt Learning" (MCPL) that teaches language models to describe the objects in images using detailed, multi-word phrases. Typical image recognition models can only identify simple labels like "dog" or "car," but MCPL allows the models to generate more nuanced descriptions, like "brown Labrador retriever sitting on grass."
To achieve this, the researchers used a two-step process. First, they provided the language model with many example image-text pairs, where the text described the objects in the corresponding image using multiple words. This helped the model learn the associations between visual elements and the language used to describe them.
Next, the researchers used an optimization technique to fine-tune the language model. This process encouraged the model to generate prompts that accurately captured the objects in new, unseen images. The key insight was to constrain the optimization in a way that pushed the model to produce multi-word prompts rather than single-word labels.
The advantage of MCPL is that it allows language models to develop a richer understanding of the visual world, going beyond simple categorization to describe objects in greater detail. This could have applications in areas like image captioning, visual question answering, and even human-robot interaction, where more nuanced descriptions of the environment can be valuable.
Technical Explanation
The paper introduces a novel approach called "Multi-Concept Prompt Learning" (MCPL) that enables language models to learn object-level concepts from images. MCPL builds on the concept of prompt learning, where language models are trained to generate specific prompts that can be used to guide their behavior.
In the context of this work, the researchers trained language models to generate multi-word prompts that accurately describe the objects present in an image. This goes beyond simple single-word labels and allows the models to capture more nuanced object-level details.
The key components of the MCPL approach are:
-
Image-Text Pairs: The researchers collected a dataset of image-text pairs, where the text descriptions used multiple words to describe the objects in the corresponding image. This provided the language model with the necessary training data to learn the associations between visual elements and their linguistic representations.
-
Constrained Optimization: To fine-tune the language model, the researchers used a constrained optimization process that encouraged the model to generate multi-word prompts rather than single-word labels. This was achieved by incorporating a regularization term that penalized the model for producing prompts that were too short or lacked the desired level of detail.
-
Multi-Concept Prompts: The output of the MCPL training process is a language model that can generate detailed, multi-word prompts that accurately describe the objects present in an image. These prompts go beyond simple classification and capture nuanced object-level concepts.
The advantages of MCPL are that it allows language models to develop a richer understanding of the visual world and can be applied to a variety of tasks, such as image captioning, visual question answering, and human-robot interaction, where more detailed object descriptions can be beneficial.
Critical Analysis
The paper presents a well-designed and methodologically sound approach to teaching language models to generate detailed, multi-word prompts for object-level concepts in images. However, there are a few potential caveats and areas for further research:
-
Dataset Bias: The performance of MCPL is likely dependent on the quality and diversity of the image-text pairs used for training. If the dataset contains biases or lacks representation of certain object types or scenes, the generated prompts may reflect these limitations.
-
Prompt Quality Evaluation: The paper relies on human evaluation to assess the quality of the generated prompts, which can be subjective. It would be valuable to explore more objective metrics for evaluating the accuracy, specificity, and linguistic quality of the prompts.
-
Generalization to Unseen Concepts: While the paper demonstrates the ability of MCPL to generate prompts for objects present in the training data, it is unclear how well the approach would generalize to completely novel object types or concepts that were not encountered during training.
-
Computational Complexity: The constrained optimization process used in MCPL may be computationally intensive, particularly for large-scale language models. Investigating ways to improve the efficiency of the training process could be an area for future research.
Despite these potential limitations, the MCPL approach represents an important contribution to the field of visual-language understanding, expanding on previous work in multi-modal prompting and joint visual-text learning. The ability to generate detailed, multi-word prompts that capture object-level concepts has the potential to significantly enhance the capabilities of language models in a wide range of applications.
Conclusion
The "Multi-Concept Prompt Learning" (MCPL) approach presented in this paper represents a significant advancement in teaching language models to understand and describe the visual world in more nuanced and detailed ways. By leveraging a combination of image-text pairs and constrained optimization, the researchers were able to train language models to generate multi-word prompts that accurately capture object-level concepts, going beyond simple single-word labels.
The potential applications of MCPL are wide-ranging, from image captioning and visual question answering to human-robot interaction and beyond. As language models continue to play an increasingly important role in our interactions with technology, the ability to generate detailed, context-aware descriptions of the visual environment will be crucial for enhancing the overall user experience and enabling more natural and intuitive interactions.
While the paper highlights a few areas for further research and improvement, the MCPL approach represents a significant step forward in the field of visual-language understanding and sets the stage for continued advancements in this rapidly evolving field of study.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
Multi-Prompt with Depth Partitioned Cross-Modal Learning
Yingjie Tian, Yiqi Wang, Xianda Guo, Zheng Zhu, Long Chen
0
0
In recent years, soft prompt learning methods have been proposed to fine-tune large-scale vision-language pre-trained models for various downstream tasks. These methods typically combine learnable textual tokens with class tokens as input for models with frozen parameters. However, they often employ a single prompt to describe class contexts, failing to capture categories' diverse attributes adequately. This study introduces the Partitioned Multi-modal Prompt (PMPO), a multi-modal prompting technique that extends the soft prompt from a single learnable prompt to multiple prompts. Our method divides the visual encoder depths and connects learnable prompts to the separated visual depths, enabling different prompts to capture the hierarchical contextual depths of visual representations. Furthermore, to maximize the advantages of multi-prompt learning, we incorporate prior information from manually designed templates and learnable multi-prompts, thus improving the generalization capabilities of our approach. We evaluate the effectiveness of our approach on three challenging tasks: new class generalization, cross-dataset evaluation, and domain generalization. For instance, our method achieves a $79.28$ harmonic mean, averaged over 11 diverse image recognition datasets ($+7.62$ compared to CoOp), demonstrating significant competitiveness compared to state-of-the-art prompting methods.
5/1/2024

Understanding Visual Concepts Across Models
Brandon Trabucco, Max Gurinas, Kyle Doherty, Ruslan Salakhutdinov
0
0
Large multimodal models such as Stable Diffusion can generate, detect, and classify new visual concepts after fine-tuning just a single word embedding. Do models learn similar words for the same concepts (i.e. = orange + cat)? We conduct a large-scale analysis on three state-of-the-art models in text-to-image generation, open-set object detection, and zero-shot classification, and find that new word embeddings are model-specific and non-transferable. Across 4,800 new embeddings trained for 40 diverse visual concepts on four standard datasets, we find perturbations within an $epsilon$-ball to any prior embedding that generate, detect, and classify an arbitrary concept. When these new embeddings are spliced into new models, fine-tuning that targets the original model is lost. We show popular soft prompt-tuning approaches find these perturbative solutions when applied to visual concept learning tasks, and embeddings for visual concepts are not transferable. Code for reproducing our work is available at: https://visual-words.github.io.
6/12/2024

TAI++: Text as Image for Multi-Label Image Classification by Co-Learning Transferable Prompt
Xiangyu Wu, Qing-Yuan Jiang, Yang Yang, Yi-Feng Wu, Qing-Guo Chen, Jianfeng Lu
0
0
The recent introduction of prompt tuning based on pre-trained vision-language models has dramatically improved the performance of multi-label image classification. However, some existing strategies that have been explored still have drawbacks, i.e., either exploiting massive labeled visual data at a high cost or using text data only for text prompt tuning and thus failing to learn the diversity of visual knowledge. Hence, the application scenarios of these methods are limited. In this paper, we propose a pseudo-visual prompt~(PVP) module for implicit visual prompt tuning to address this problem. Specifically, we first learn the pseudo-visual prompt for each category, mining diverse visual knowledge by the well-aligned space of pre-trained vision-language models. Then, a co-learning strategy with a dual-adapter module is designed to transfer visual knowledge from pseudo-visual prompt to text prompt, enhancing their visual representation abilities. Experimental results on VOC2007, MS-COCO, and NUSWIDE datasets demonstrate that our method can surpass state-of-the-art~(SOTA) methods across various settings for multi-label image classification tasks. The code is available at https://github.com/njustkmg/PVP.
5/14/2024
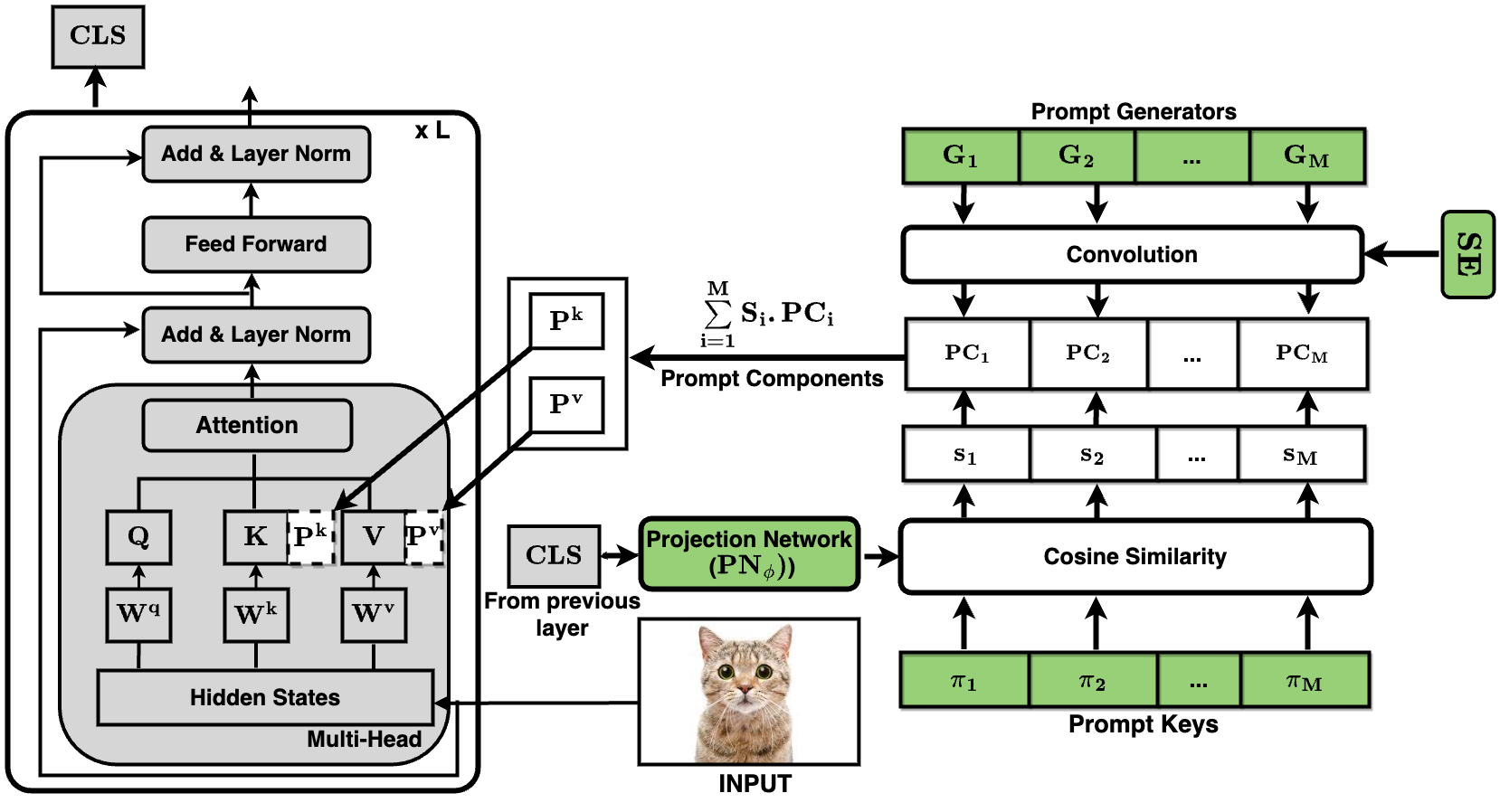
Convolutional Prompting meets Language Models for Continual Learning
Anurag Roy, Riddhiman Moulick, Vinay K. Verma, Saptarshi Ghosh, Abir Das
0
0
Continual Learning (CL) enables machine learning models to learn from continuously shifting new training data in absence of data from old tasks. Recently, pretrained vision transformers combined with prompt tuning have shown promise for overcoming catastrophic forgetting in CL. These approaches rely on a pool of learnable prompts which can be inefficient in sharing knowledge across tasks leading to inferior performance. In addition, the lack of fine-grained layer specific prompts does not allow these to fully express the strength of the prompts for CL. We address these limitations by proposing ConvPrompt, a novel convolutional prompt creation mechanism that maintains layer-wise shared embeddings, enabling both layer-specific learning and better concept transfer across tasks. The intelligent use of convolution enables us to maintain a low parameter overhead without compromising performance. We further leverage Large Language Models to generate fine-grained text descriptions of each category which are used to get task similarity and dynamically decide the number of prompts to be learned. Extensive experiments demonstrate the superiority of ConvPrompt and improves SOTA by ~3% with significantly less parameter overhead. We also perform strong ablation over various modules to disentangle the importance of different components.
4/1/2024