Understanding Visual Concepts Across Models
2406.07506
0
0

Abstract
Large multimodal models such as Stable Diffusion can generate, detect, and classify new visual concepts after fine-tuning just a single word embedding. Do models learn similar words for the same concepts (i.e. = orange + cat)? We conduct a large-scale analysis on three state-of-the-art models in text-to-image generation, open-set object detection, and zero-shot classification, and find that new word embeddings are model-specific and non-transferable. Across 4,800 new embeddings trained for 40 diverse visual concepts on four standard datasets, we find perturbations within an $epsilon$-ball to any prior embedding that generate, detect, and classify an arbitrary concept. When these new embeddings are spliced into new models, fine-tuning that targets the original model is lost. We show popular soft prompt-tuning approaches find these perturbative solutions when applied to visual concept learning tasks, and embeddings for visual concepts are not transferable. Code for reproducing our work is available at: https://visual-words.github.io.
Create account to get full access
Overview
- This paper explores how different machine learning models understand and represent visual concepts, and how these representations can be compared and aligned across models.
- The authors investigate the idea of "visual concepts" - the high-level semantic categories and attributes that humans use to describe and recognize objects and scenes.
- They propose methods to discover and analyze these visual concepts, and to understand how they are captured by different machine learning models, including text-to-image models, large language models, and interpretable visual classifiers.
Plain English Explanation
The paper looks at how different AI models, like text-to-image generators and large language models, understand and represent high-level visual concepts. Visual concepts are the categories and attributes that humans use to describe and recognize objects and scenes, like "dog," "red," or "wooden chair."
The researchers develop methods to discover and analyze these visual concepts across different AI models. This allows them to understand how each model captures and represents these important visual building blocks. By comparing the visual concept representations between models, they can also find ways to better align and combine the knowledge of different AI systems.
Technical Explanation
The paper proposes several approaches to discover and analyze visual concepts across machine learning models:
-
Concept Extraction: The authors develop techniques to automatically extract the high-level visual concepts learned by different models, including text-to-image generators, large language models, and interpretable visual classifiers.
-
Concept Alignment: They then devise methods to align the visual concept representations between models, allowing for direct comparisons and knowledge transfer.
-
Concept Analysis: Using the extracted and aligned concepts, the researchers analyze properties like concept similarity, hierarchical structure, and model-specific biases.
Through these analyses, the paper sheds light on how different AI models internalize and represent the visual world, and how these representations can be better understood and leveraged. The findings have implications for improving model interpretability, robustness, and generalization capabilities.
Critical Analysis
The paper makes a valuable contribution to understanding the inner workings of complex machine learning models and how they represent high-level visual information. By focusing on the notion of "visual concepts," the authors provide a principled way to analyze and compare the conceptual knowledge captured by different models.
One limitation mentioned in the paper is the challenge of validating the extracted visual concepts, as there is no ground truth for what the "correct" set of concepts should be. The authors acknowledge this issue and propose various evaluation approaches, but further work is needed to establish robust concept discovery and validation techniques.
Additionally, the paper primarily focuses on analyzing pre-trained models, without exploring how the visual concept representations might change during the training process. Investigating the developmental trajectory of these representations could yield additional insights.
Overall, the research represents an important step forward in understanding the inner workings of complex AI systems and the ways in which they encode and represent the visual world. By continuing to probe these issues, the field can work towards more interpretable, robust, and generalized machine learning models.
Conclusion
This paper presents a novel approach to analyzing visual concept representations across different machine learning models, including text-to-image generators, large language models, and interpretable visual classifiers. By developing methods to extract, align, and compare these high-level visual concepts, the authors shed light on how diverse AI systems internalize and encode the visual world.
The findings have implications for improving model interpretability, robustness, and generalization capabilities, as well as for understanding the similarities and differences in how various AI models represent and reason about visual information. As the field of artificial intelligence continues to advance, this type of research will be crucial for building more transparent and capable systems that can effectively interact with and understand the visual world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
Language-Informed Visual Concept Learning
Sharon Lee, Yunzhi Zhang, Shangzhe Wu, Jiajun Wu
0
0
Our understanding of the visual world is centered around various concept axes, characterizing different aspects of visual entities. While different concept axes can be easily specified by language, e.g. color, the exact visual nuances along each axis often exceed the limitations of linguistic articulations, e.g. a particular style of painting. In this work, our goal is to learn a language-informed visual concept representation, by simply distilling large pre-trained vision-language models. Specifically, we train a set of concept encoders to encode the information pertinent to a set of language-informed concept axes, with an objective of reproducing the input image through a pre-trained Text-to-Image (T2I) model. To encourage better disentanglement of different concept encoders, we anchor the concept embeddings to a set of text embeddings obtained from a pre-trained Visual Question Answering (VQA) model. At inference time, the model extracts concept embeddings along various axes from new test images, which can be remixed to generate images with novel compositions of visual concepts. With a lightweight test-time finetuning procedure, it can also generalize to novel concepts unseen at training.
4/4/2024
🤔
Probing Conceptual Understanding of Large Visual-Language Models
Madeline Schiappa, Raiyaan Abdullah, Shehreen Azad, Jared Claypoole, Michael Cogswell, Ajay Divakaran, Yogesh Rawat
0
0
In recent years large visual-language (V+L) models have achieved great success in various downstream tasks. However, it is not well studied whether these models have a conceptual grasp of the visual content. In this work we focus on conceptual understanding of these large V+L models. To facilitate this study, we propose novel benchmarking datasets for probing three different aspects of content understanding, 1) textit{relations}, 2) textit{composition}, and 3) textit{context}. Our probes are grounded in cognitive science and help determine if a V+L model can, for example, determine if snow garnished with a man is implausible, or if it can identify beach furniture by knowing it is located on a beach. We experimented with many recent state-of-the-art V+L models and observe that these models mostly textit{fail to demonstrate} a conceptual understanding. This study reveals several interesting insights such as that textit{cross-attention} helps learning conceptual understanding, and that CNNs are better with textit{texture and patterns}, while Transformers are better at textit{color and shape}. We further utilize some of these insights and investigate a textit{simple finetuning technique} that rewards the three conceptual understanding measures with promising initial results. The proposed benchmarks will drive the community to delve deeper into conceptual understanding and foster advancements in the capabilities of large V+L models. The code and dataset is available at: url{https://tinyurl.com/vlm-robustness}
4/29/2024

An Image is Worth Multiple Words: Discovering Object Level Concepts using Multi-Concept Prompt Learning
Chen Jin, Ryutaro Tanno, Amrutha Saseendran, Tom Diethe, Philip Teare
0
0
Textural Inversion, a prompt learning method, learns a singular text embedding for a new word to represent image style and appearance, allowing it to be integrated into natural language sentences to generate novel synthesised images. However, identifying multiple unknown object-level concepts within one scene remains a complex challenge. While recent methods have resorted to cropping or masking individual images to learn multiple concepts, these techniques often require prior knowledge of new concepts and are labour-intensive. To address this challenge, we introduce Multi-Concept Prompt Learning (MCPL), where multiple unknown words are simultaneously learned from a single sentence-image pair, without any imagery annotations. To enhance the accuracy of word-concept correlation and refine attention mask boundaries, we propose three regularisation techniques: Attention Masking, Prompts Contrastive Loss, and Bind Adjective. Extensive quantitative comparisons with both real-world categories and biomedical images demonstrate that our method can learn new semantically disentangled concepts. Our approach emphasises learning solely from textual embeddings, using less than 10% of the storage space compared to others. The project page, code, and data are available at https://astrazeneca.github.io/mcpl.github.io.
5/28/2024
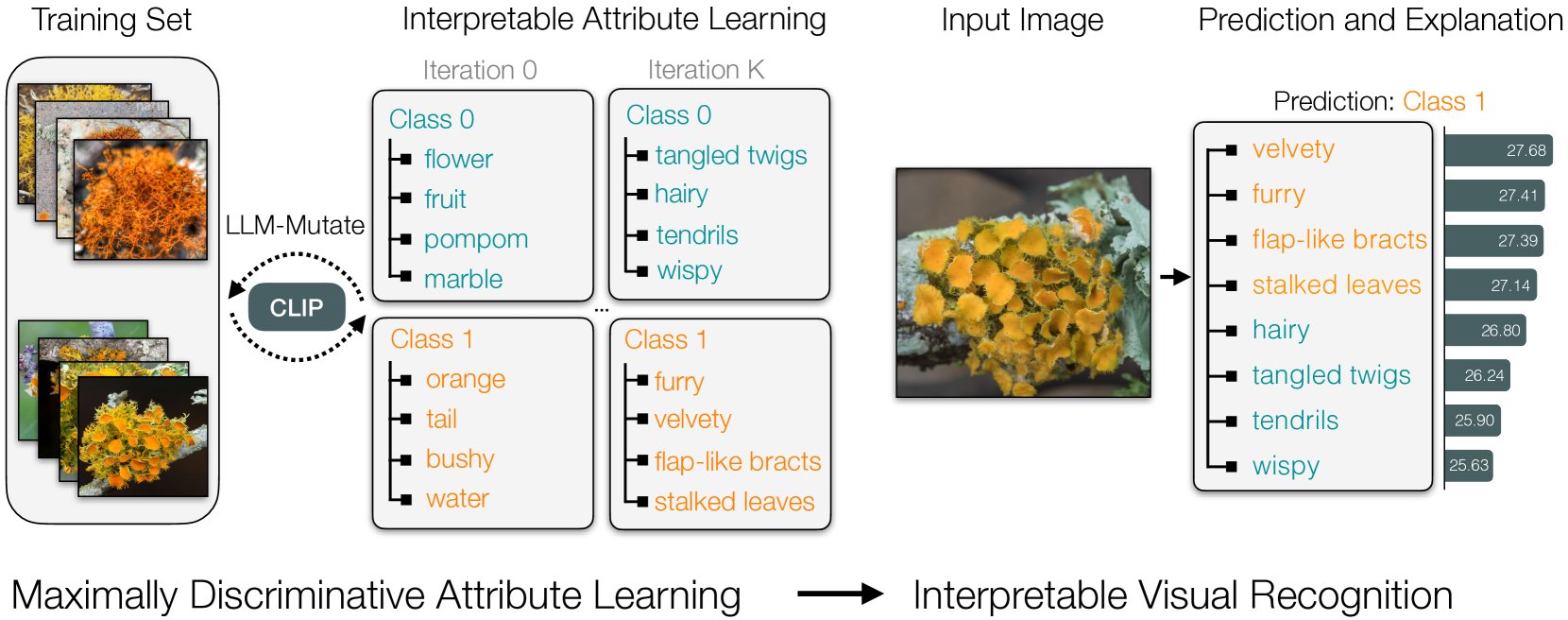
Evolving Interpretable Visual Classifiers with Large Language Models
Mia Chiquier, Utkarsh Mall, Carl Vondrick
0
0
Multimodal pre-trained models, such as CLIP, are popular for zero-shot classification due to their open-vocabulary flexibility and high performance. However, vision-language models, which compute similarity scores between images and class labels, are largely black-box, with limited interpretability, risk for bias, and inability to discover new visual concepts not written down. Moreover, in practical settings, the vocabulary for class names and attributes of specialized concepts will not be known, preventing these methods from performing well on images uncommon in large-scale vision-language datasets. To address these limitations, we present a novel method that discovers interpretable yet discriminative sets of attributes for visual recognition. We introduce an evolutionary search algorithm that uses a large language model and its in-context learning abilities to iteratively mutate a concept bottleneck of attributes for classification. Our method produces state-of-the-art, interpretable fine-grained classifiers. We outperform the latest baselines by 18.4% on five fine-grained iNaturalist datasets and by 22.2% on two KikiBouba datasets, despite the baselines having access to privileged information about class names.
4/16/2024