Image to Pseudo-Episode: Boosting Few-Shot Segmentation by Unlabeled Data

0
🖼️
Sign in to get full access
Overview
- Few-shot segmentation (FSS) aims to train a model that can segment objects from novel classes with just a few labeled samples.
- The limited generalization ability of existing models leads to poor performance when there is not enough labeled data for the novel classes.
- This paper proposes a method called Image to Pseudo-Episode (IPE) to leverage abundant unlabeled data and improve the model's generalization.
Plain English Explanation
The goal of few-shot segmentation (FSS) is to train a machine learning model that can accurately segment, or outline, objects from new classes using only a small number of labeled examples. This is a challenging task because models often struggle to generalize well when they don't have access to a lot of labeled data for the new classes.
However, in many real-world scenarios, there is a vast amount of unlabeled data available that could potentially be used to improve the model's performance. The authors of this paper propose a novel method called "Image to Pseudo-Episode" (IPE) to take advantage of this unlabeled data.
The IPE method has two main steps. First, it uses a technique called spectral clustering to automatically generate "pseudo-labels" for the unlabeled images, identifying the different objects in each image. Then, it applies data augmentation techniques to these pseudo-labeled images to create "pseudo-episodes" - simulated training examples that mimic the format of the original few-shot training data.
By leveraging this abundance of unlabeled data through the IPE method, the authors were able to train few-shot segmentation models that outperform state-of-the-art approaches on standard benchmarks. This suggests that finding ways to use unlabeled data can be a powerful technique for improving the performance of machine learning models, especially in areas like few-shot learning where labeled data is scarce.
Technical Explanation
The core of the proposed IPE method consists of two main modules:
-
Pseudo-Label Generation Module: This module uses spectral clustering to automatically generate pseudo-labels for the unlabeled images. Spectral clustering is an unsupervised machine learning technique that can identify distinct clusters or segments within the unlabeled data.
-
Episode Generation Module: This module takes the pseudo-labeled images and applies data augmentation techniques like flipping, scaling, and rotation to create "pseudo-episodes". These pseudo-episodes mimic the format of the original few-shot training data, which typically consists of a support set (with a few labeled examples) and a query set.
By generating these pseudo-episodes from the unlabeled data, the authors were able to enhance the semi-supervised training process for their few-shot segmentation model. This allowed the model to learn more robust features and improve its generalization to novel classes, even when only a small number of labeled examples were available.
The authors evaluated their IPE method on two standard few-shot segmentation benchmarks: PASCAL-$5^i$ and COCO-$20^i$. Their experiments demonstrated that the IPE-trained models achieved state-of-the-art performance, surpassing other few-shot segmentation approaches that did not leverage unlabeled data in the same way.
Critical Analysis
The authors acknowledge that their IPE method relies on the assumption that the unlabeled data contains objects from the same distribution as the novel classes in the few-shot setting. If the unlabeled data is significantly different from the target novel classes, the pseudo-labels and pseudo-episodes generated may not be as useful for improving the model's performance.
Additionally, the authors note that their method is computationally more expensive than some other few-shot segmentation approaches, due to the need to perform spectral clustering on the unlabeled data. This could be a limitation in scenarios where computation time is a critical factor.
It would also be interesting to see how the IPE method compares to other semi-supervised or weakly-supervised techniques for leveraging unlabeled data, such as self-supervised learning or generative adversarial networks. Exploring these alternative approaches could lead to further improvements in few-shot segmentation performance.
Conclusion
This paper presents a novel method called Image to Pseudo-Episode (IPE) that effectively leverages abundant unlabeled data to improve the generalization of few-shot segmentation models. By automatically generating pseudo-labels and pseudo-episodes from the unlabeled data, the authors were able to train models that outperform state-of-the-art few-shot segmentation approaches on standard benchmarks.
The success of the IPE method highlights the potential of using unlabeled data to enhance the performance of machine learning models, especially in data-scarce domains like few-shot learning. As the availability of unlabeled data continues to grow, finding effective ways to leverage this data will be an important area of research for improving the generalization and real-world applicability of AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🖼️
0
Image to Pseudo-Episode: Boosting Few-Shot Segmentation by Unlabeled Data
Jie Zhang, Yuhan Li, Yude Wang, Stephen Lin, Shiguang Shan
Few-shot segmentation (FSS) aims to train a model which can segment the object from novel classes with a few labeled samples. The insufficient generalization ability of models leads to unsatisfactory performance when the models lack enough labeled data from the novel classes. Considering that there are abundant unlabeled data available, it is promising to improve the generalization ability by exploiting these various data. For leveraging unlabeled data, we propose a novel method, named Image to Pseudo-Episode (IPE), to generate pseudo-episodes from unlabeled data. Specifically, our method contains two modules, i.e., the pseudo-label generation module and the episode generation module. The former module generates pseudo-labels from unlabeled images by the spectral clustering algorithm, and the latter module generates pseudo-episodes from pseudo-labeled images by data augmentation methods. Extensive experiments on PASCAL-$5^i$ and COCO-$20^i$ demonstrate that our method achieves the state-of-the-art performance for FSS.
Read more5/15/2024

0
Few-Shot Medical Image Segmentation with High-Fidelity Prototypes
Song Tang, Shaxu Yan, Xiaozhi Qi, Jianxin Gao, Mao Ye, Jianwei Zhang, Xiatian Zhu
Few-shot Semantic Segmentation (FSS) aims to adapt a pretrained model to new classes with as few as a single labelled training sample per class. Despite the prototype based approaches have achieved substantial success, existing models are limited to the imaging scenarios with considerably distinct objects and not highly complex background, e.g., natural images. This makes such models suboptimal for medical imaging with both conditions invalid. To address this problem, we propose a novel Detail Self-refined Prototype Network (DSPNet) to constructing high-fidelity prototypes representing the object foreground and the background more comprehensively. Specifically, to construct global semantics while maintaining the captured detail semantics, we learn the foreground prototypes by modelling the multi-modal structures with clustering and then fusing each in a channel-wise manner. Considering that the background often has no apparent semantic relation in the spatial dimensions, we integrate channel-specific structural information under sparse channel-aware regulation. Extensive experiments on three challenging medical image benchmarks show the superiority of DSPNet over previous state-of-the-art methods.
Read more6/27/2024

0
Organizing Background to Explore Latent Classes for Incremental Few-shot Semantic Segmentation
Lianlei Shan, Wenzhang Zhou, Wei Li, Xingyu Ding
The goal of incremental Few-shot Semantic Segmentation (iFSS) is to extend pre-trained segmentation models to new classes via few annotated images without access to old training data. During incrementally learning novel classes, the data distribution of old classes will be destroyed, leading to catastrophic forgetting. Meanwhile, the novel classes have only few samples, making models impossible to learn the satisfying representations of novel classes. For the iFSS problem, we propose a network called OINet, i.e., the background embedding space textbf{O}rganization and prototype textbf{I}nherit Network. Specifically, when training base classes, OINet uses multiple classification heads for the background and sets multiple sub-class prototypes to reserve embedding space for the latent novel classes. During incrementally learning novel classes, we propose a strategy to select the sub-class prototypes that best match the current learning novel classes and make the novel classes inherit the selected prototypes' embedding space. This operation allows the novel classes to be registered in the embedding space using few samples without affecting the distribution of the base classes. Results on Pascal-VOC and COCO show that OINet achieves a new state of the art.
Read more5/31/2024
0
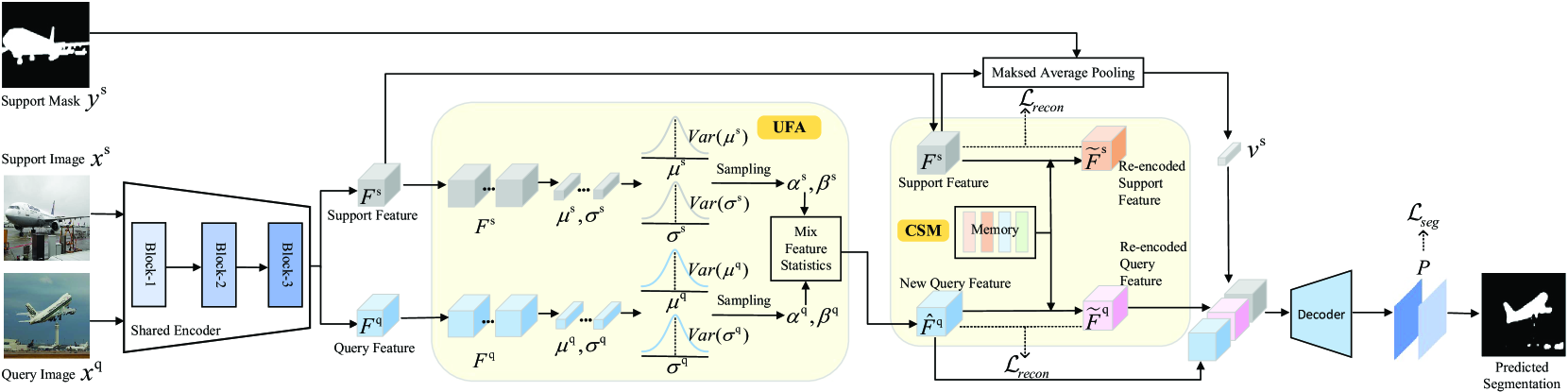
Memory-guided Network with Uncertainty-based Feature Augmentation for Few-shot Semantic Segmentation
Xinyue Chen, Miaojing Shi
The performance of supervised semantic segmentation methods highly relies on the availability of large-scale training data. To alleviate this dependence, few-shot semantic segmentation (FSS) is introduced to leverage the model trained on base classes with sufficient data into the segmentation of novel classes with few data. FSS methods face the challenge of model generalization on novel classes due to the distribution shift between base and novel classes. To overcome this issue, we propose a class-shared memory (CSM) module consisting of a set of learnable memory vectors. These memory vectors learn elemental object patterns from base classes during training whilst re-encoding query features during both training and inference, thereby improving the distribution alignment between base and novel classes. Furthermore, to cope with the performance degradation resulting from the intra-class variance across images, we introduce an uncertainty-based feature augmentation (UFA) module to produce diverse query features during training for improving the model's robustness. We integrate CSM and UFA into representative FSS works, with experimental results on the widely-used PASCAL-5$^i$ and COCO-20$^i$ datasets demonstrating the superior performance of ours over state of the art.
Read more6/11/2024