LLaFS: When Large Language Models Meet Few-Shot Segmentation
2311.16926
0
0
💬
Abstract
This paper proposes LLaFS, the first attempt to leverage large language models (LLMs) in few-shot segmentation. In contrast to the conventional few-shot segmentation methods that only rely on the limited and biased information from the annotated support images, LLaFS leverages the vast prior knowledge gained by LLM as an effective supplement and directly uses the LLM to segment images in a few-shot manner. To enable the text-based LLM to handle image-related tasks, we carefully design an input instruction that allows the LLM to produce segmentation results represented as polygons, and propose a region-attribute table to simulate the human visual mechanism and provide multi-modal guidance. We also synthesize pseudo samples and use curriculum learning for pretraining to augment data and achieve better optimization. LLaFS achieves state-of-the-art results on multiple datasets, showing the potential of using LLMs for few-shot computer vision tasks.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a new approach called LLaFS (Large Language model-based Few-Shot Segmentation) for few-shot image segmentation.
- The key idea is to leverage the vast prior knowledge gained by large language models (LLMs) to supplement the limited information from the annotated support images in few-shot segmentation tasks.
- LLaFS enables the text-based LLM to handle image-related tasks through carefully designed input instructions and a region-attribute table.
- The authors also use techniques like pseudo-sample synthesis and curriculum learning to improve the performance of LLaFS.
Plain English Explanation
Imagine you're an artist, and you're asked to paint a picture of a specific animal, like a giraffe, but you've only seen a few examples of that animal before. Traditionally, you'd have to rely solely on those limited examples to try to recreate the animal accurately. However, with LLaFS, you can also tap into a vast database of information about giraffes, stored in a large language model (LLM).
The researchers designed a way for the LLM to understand image-related tasks, like segmenting the different parts of a giraffe in a picture. They gave the LLM special instructions and a table of visual attributes to help it interpret the image. This allowed the LLM to use its broad knowledge about giraffes to segment the image, even with just a few example images to work with.
The researchers also used some clever techniques, like generating fake giraffe images and gradually increasing the difficulty of the task, to further improve the performance of LLaFS. The result is a system that can do a better job of segmenting images, even when it only has a few examples to learn from.
Technical Explanation
The key innovation of LLaFS is its ability to leverage the knowledge stored in large language models (LLMs) to supplement the limited information available in few-shot segmentation tasks. Conventional few-shot segmentation methods rely solely on the annotated support images, which can be biased or incomplete. In contrast, LLaFS directly uses the LLM to segment images in a few-shot manner, tapping into the vast prior knowledge the LLM has gained from being trained on a broad corpus of text data.
To enable the text-based LLM to handle image-related tasks, the researchers carefully designed an input instruction that allows the LLM to produce segmentation results represented as polygons. They also proposed a region-attribute table to simulate the human visual mechanism and provide multi-modal guidance to the LLM.
Additionally, the researchers synthesized pseudo samples and used curriculum learning for pretraining to augment the data and achieve better optimization. This helps the LLaFS model generalize better and perform well on few-shot segmentation tasks.
The experiments conducted on multiple datasets show that LLaFS achieves state-of-the-art results, demonstrating the potential of using LLMs for few-shot computer vision tasks.
Critical Analysis
The paper presents a promising approach to leveraging the power of large language models for few-shot image segmentation. However, there are a few potential limitations and areas for further research:
-
The performance of LLaFS is still dependent on the quality and coverage of the LLM's pre-trained knowledge. If the LLM lacks sufficient information about certain types of objects or visual concepts, the few-shot segmentation performance may still be limited.
-
The paper does not explore the scalability of the approach to more complex, real-world segmentation tasks. The experiments are conducted on relatively simple datasets, and it's unclear how well LLaFS would perform on more challenging, high-stakes applications.
-
The region-attribute table used to guide the LLM's understanding of the image is manually designed. An interesting area for future research would be to investigate ways to automatically generate or learn this table, making the system more adaptable and generalizable.
-
The paper does not provide a detailed analysis of the LLM's internal decision-making process or the specific types of knowledge it leverages for few-shot segmentation. A better understanding of these aspects could lead to further improvements in the approach.
Despite these potential limitations, the core idea of using LLMs to supplement few-shot computer vision tasks is a promising direction that could have significant implications for various real-world applications.
Conclusion
The LLaFS approach presented in this paper represents a novel way to leverage the power of large language models for few-shot image segmentation tasks. By tapping into the vast prior knowledge stored in LLMs, the system can perform better than traditional few-shot methods that rely solely on limited annotated data.
The techniques used, such as the carefully designed input instructions, region-attribute table, and data augmentation strategies, demonstrate the researchers' thoughtful approach to enabling LLMs to handle image-related tasks. While the current implementation has some limitations, the potential of this approach is significant, as it could pave the way for more effective few-shot learning in computer vision and other domains.
Overall, this paper highlights the exciting possibilities of bridging the gap between language models and computer vision, opening up new avenues for enhancing the performance of machine learning systems, even when faced with limited training data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
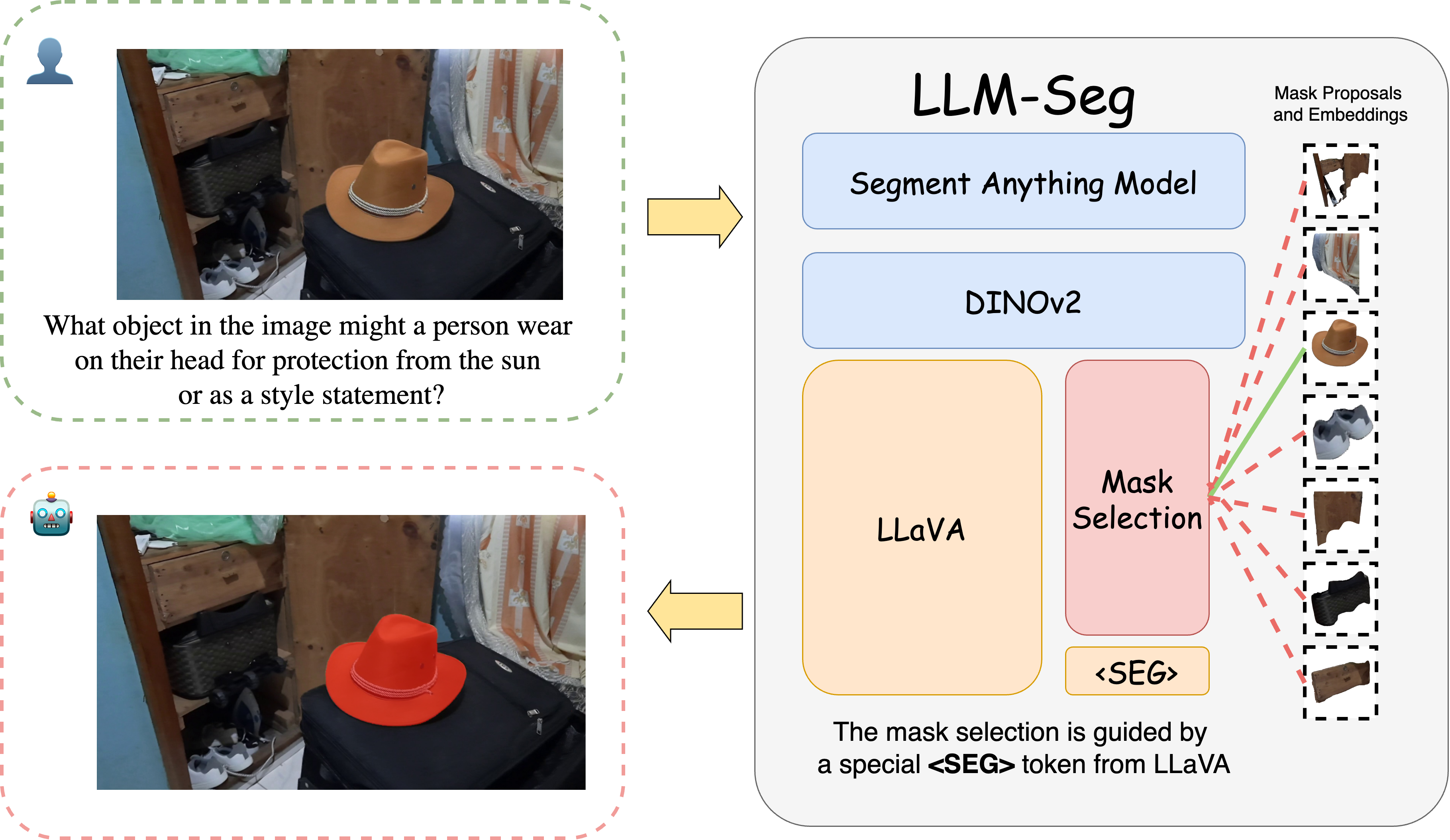
LLM-Seg: Bridging Image Segmentation and Large Language Model Reasoning
Junchi Wang, Lei Ke
0
0
Understanding human instructions to identify the target objects is vital for perception systems. In recent years, the advancements of Large Language Models (LLMs) have introduced new possibilities for image segmentation. In this work, we delve into reasoning segmentation, a novel task that enables segmentation system to reason and interpret implicit user intention via large language model reasoning and then segment the corresponding target. Our work on reasoning segmentation contributes on both the methodological design and dataset labeling. For the model, we propose a new framework named LLM-Seg. LLM-Seg effectively connects the current foundational Segmentation Anything Model and the LLM by mask proposals selection. For the dataset, we propose an automatic data generation pipeline and construct a new reasoning segmentation dataset named LLM-Seg40K. Experiments demonstrate that our LLM-Seg exhibits competitive performance compared with existing methods. Furthermore, our proposed pipeline can efficiently produce high-quality reasoning segmentation datasets. The LLM-Seg40K dataset, developed through this pipeline, serves as a new benchmark for training and evaluating various reasoning segmentation approaches. Our code, models and dataset are at https://github.com/wangjunchi/LLMSeg.
4/16/2024
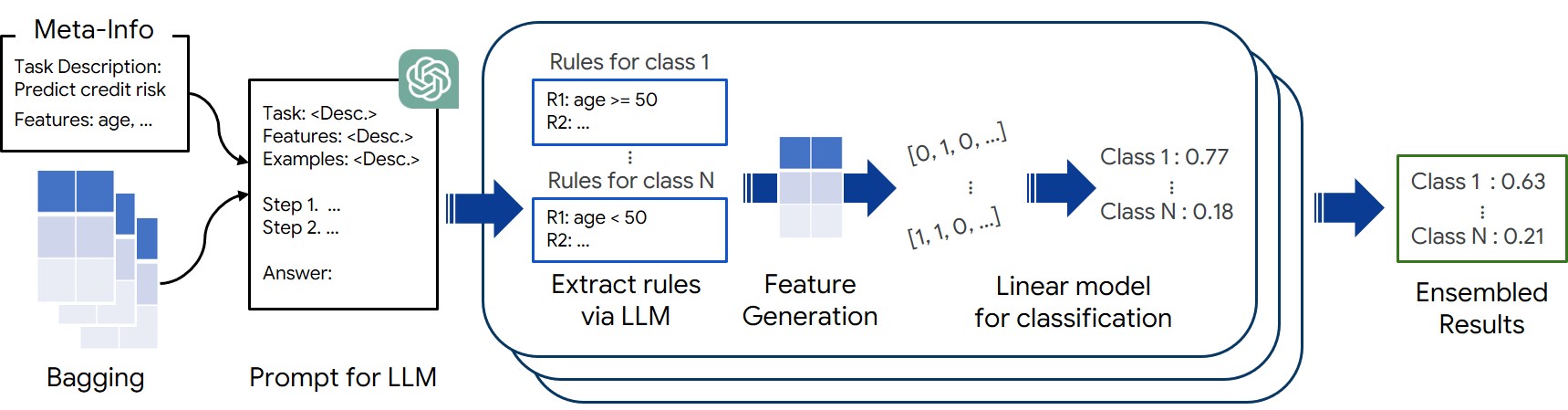
Large Language Models Can Automatically Engineer Features for Few-Shot Tabular Learning
Sungwon Han, Jinsung Yoon, Sercan O Arik, Tomas Pfister
0
0
Large Language Models (LLMs), with their remarkable ability to tackle challenging and unseen reasoning problems, hold immense potential for tabular learning, that is vital for many real-world applications. In this paper, we propose a novel in-context learning framework, FeatLLM, which employs LLMs as feature engineers to produce an input data set that is optimally suited for tabular predictions. The generated features are used to infer class likelihood with a simple downstream machine learning model, such as linear regression and yields high performance few-shot learning. The proposed FeatLLM framework only uses this simple predictive model with the discovered features at inference time. Compared to existing LLM-based approaches, FeatLLM eliminates the need to send queries to the LLM for each sample at inference time. Moreover, it merely requires API-level access to LLMs, and overcomes prompt size limitations. As demonstrated across numerous tabular datasets from a wide range of domains, FeatLLM generates high-quality rules, significantly (10% on average) outperforming alternatives such as TabLLM and STUNT.
5/7/2024

Large Language Models are Good Prompt Learners for Low-Shot Image Classification
Zhaoheng Zheng, Jingmin Wei, Xuefeng Hu, Haidong Zhu, Ram Nevatia
0
0
Low-shot image classification, where training images are limited or inaccessible, has benefited from recent progress on pre-trained vision-language (VL) models with strong generalizability, e.g. CLIP. Prompt learning methods built with VL models generate text features from the class names that only have confined class-specific information. Large Language Models (LLMs), with their vast encyclopedic knowledge, emerge as the complement. Thus, in this paper, we discuss the integration of LLMs to enhance pre-trained VL models, specifically on low-shot classification. However, the domain gap between language and vision blocks the direct application of LLMs. Thus, we propose LLaMP, Large Language Models as Prompt learners, that produces adaptive prompts for the CLIP text encoder, establishing it as the connecting bridge. Experiments show that, compared with other state-of-the-art prompt learning methods, LLaMP yields better performance on both zero-shot generalization and few-shot image classification, over a spectrum of 11 datasets. Code will be made available at: https://github.com/zhaohengz/LLaMP.
4/4/2024
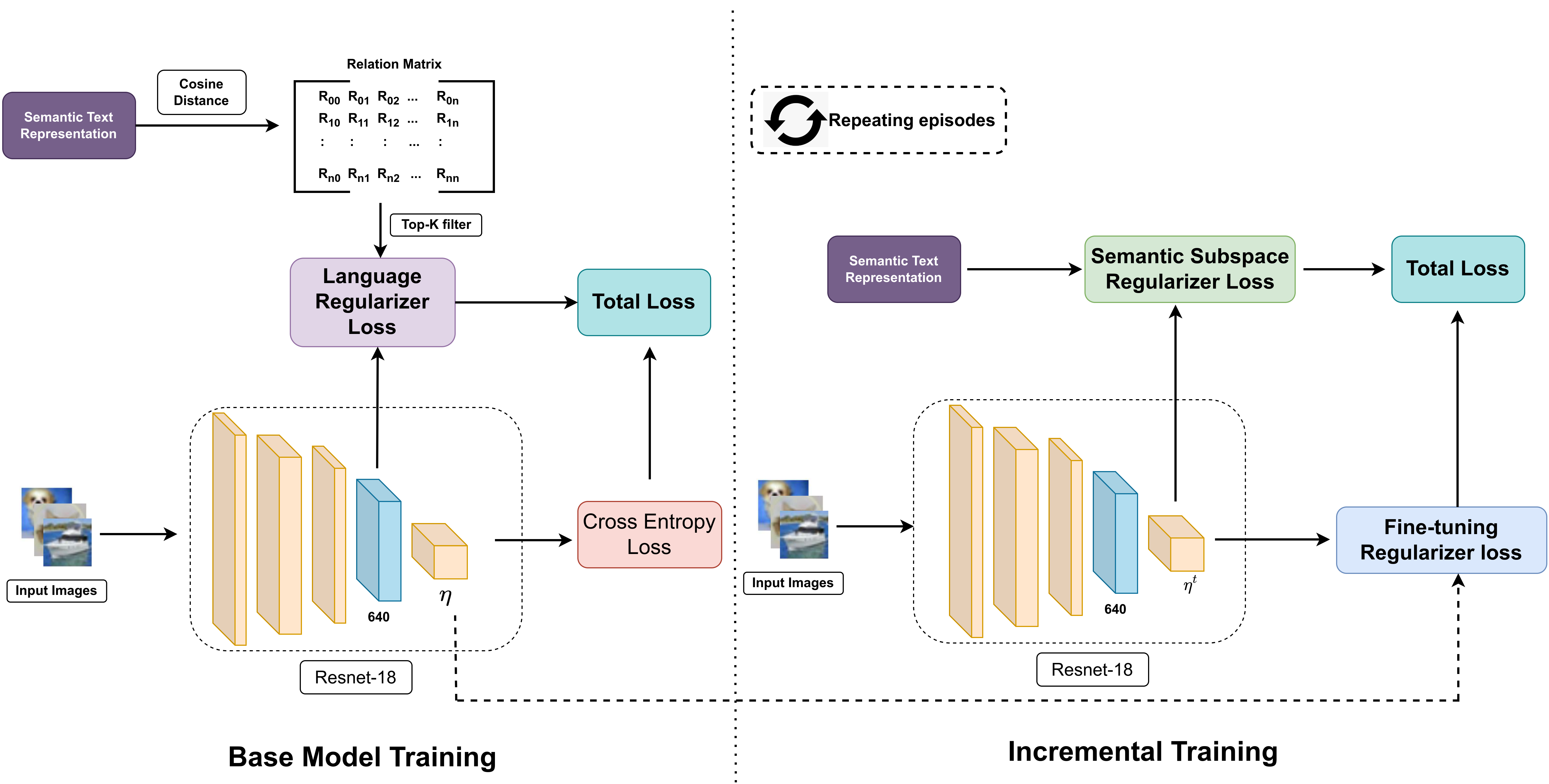
Few Shot Class Incremental Learning using Vision-Language models
Anurag Kumar, Chinmay Bharti, Saikat Dutta, Srikrishna Karanam, Biplab Banerjee
0
0
Recent advancements in deep learning have demonstrated remarkable performance comparable to human capabilities across various supervised computer vision tasks. However, the prevalent assumption of having an extensive pool of training data encompassing all classes prior to model training often diverges from real-world scenarios, where limited data availability for novel classes is the norm. The challenge emerges in seamlessly integrating new classes with few samples into the training data, demanding the model to adeptly accommodate these additions without compromising its performance on base classes. To address this exigency, the research community has introduced several solutions under the realm of few-shot class incremental learning (FSCIL). In this study, we introduce an innovative FSCIL framework that utilizes language regularizer and subspace regularizer. During base training, the language regularizer helps incorporate semantic information extracted from a Vision-Language model. The subspace regularizer helps in facilitating the model's acquisition of nuanced connections between image and text semantics inherent to base classes during incremental training. Our proposed framework not only empowers the model to embrace novel classes with limited data, but also ensures the preservation of performance on base classes. To substantiate the efficacy of our approach, we conduct comprehensive experiments on three distinct FSCIL benchmarks, where our framework attains state-of-the-art performance.
5/3/2024