Image-to-Text Logic Jailbreak: Your Imagination can Help You Do Anything

0

Sign in to get full access
Overview
- This paper explores a novel approach to "jailbreaking" or bypassing the limitations of image-to-text models, allowing them to generate outputs that go beyond their intended capabilities.
- The key idea is to leverage the power of the human imagination by prompting users to generate text descriptions of imagined images, which can then be used to manipulate the model's behavior.
- The authors demonstrate the effectiveness of this technique through a series of experiments, showing that it can be used to generate diverse and creative outputs that traditional image captioning systems could not produce.
Plain English Explanation
The researchers in this paper have discovered a clever way to get image-to-text AI models to do more than they were originally designed for. Typically, these models are trained to take an image as input and generate a text description of what's in the image. But the researchers found that by asking people to imagine an image and then describe it, they can trick the model into producing all sorts of creative and unexpected outputs.
For example, instead of just describing a photo of a dog, a person could imagine a dog riding a skateboard and then describe that imaginary scene. The AI model would then try to generate text based on that description, even though the imagined scene doesn't actually exist in the real world.
This approach essentially "links" the human imagination with the capabilities of the AI model, allowing users to push the boundaries of what the model can do. The researchers call this a "jailbreak" because it lets the model break free from its normal constraints and do things it wasn't originally intended for.
Overall, this research suggests that by tapping into the power of human creativity and imagination, we can unlock new and unexpected capabilities in AI systems, opening up all sorts of possibilities for how these technologies can be used.
Technical Explanation
The key innovation in this paper is the use of a "visual roleplay" approach to "jailbreak" image-to-text models. Instead of providing the model with real images as input, the authors prompt human participants to imagine a scene and then describe it in natural language.
The authors then use these imagined scene descriptions as input to the image captioning model, effectively "tricking" the model into generating text outputs that go beyond its typical capabilities. Through a series of experiments, the authors demonstrate that this approach can lead to diverse, creative, and even "surreal" outputs that traditional image captioning systems would be unable to produce.
Notably, the authors also explore ways to "automate" the visual roleplay process, such as by having users generate imagined scenes through voice commands. This suggests that the "jailbreaking" technique could be scaled up and integrated into real-world applications.
Critical Analysis
The authors present a compelling and creative approach to expanding the capabilities of image-to-text models. By tapping into the human imagination, they demonstrate that these models can be pushed to generate outputs that go well beyond their typical training data and objectives.
However, the paper does not extensively explore the potential limitations or downsides of this approach. For example, one could argue that the outputs generated through visual roleplay may lack coherence or grounding in reality, and it's unclear how the model would perform on more practical, real-world tasks.
Additionally, the authors do not address potential ethical concerns around the use of this technique, such as the risk of generating misleading or harmful content. As with any powerful AI capability, there is a need to carefully consider the societal implications and ensure appropriate safeguards are in place.
Overall, the research presented in this paper is intriguing and opens up exciting possibilities for the future of image-to-text AI. However, further investigation is needed to fully understand the strengths, limitations, and responsible applications of this "jailbreaking" approach.
Conclusion
This paper introduces a novel technique for "jailbreaking" image-to-text AI models by leveraging the power of human imagination. By prompting users to describe imagined scenes, the authors demonstrate that these models can be manipulated to generate diverse and creative outputs that go beyond their typical capabilities.
The research highlights the potential for tapping into human creativity to unlock new possibilities in AI systems. While further exploration is needed to address potential limitations and ethical concerns, this work represents an exciting step forward in pushing the boundaries of what image-to-text models can achieve.
As AI technologies continue to advance, approaches like the one presented in this paper may become increasingly important for ensuring that these systems can adapt to a wide range of human needs and use cases, rather than being constrained by their original training objectives.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Image-to-Text Logic Jailbreak: Your Imagination can Help You Do Anything
Xiaotian Zou, Ke Li, Yongkang Chen
Large Visual Language Modeltextbfs (VLMs) such as GPT-4V have achieved remarkable success in generating comprehensive and nuanced responses. Researchers have proposed various benchmarks for evaluating the capabilities of VLMs. With the integration of visual and text inputs in VLMs, new security issues emerge, as malicious attackers can exploit multiple modalities to achieve their objectives. This has led to increasing attention on the vulnerabilities of VLMs to jailbreak. Most existing research focuses on generating adversarial images or nonsensical image to jailbreak these models. However, no researchers evaluate whether logic understanding capabilities of VLMs in flowchart can influence jailbreak. Therefore, to fill this gap, this paper first introduces a novel dataset Flow-JD specifically designed to evaluate the logic-based flowchart jailbreak capabilities of VLMs. We conduct an extensive evaluation on GPT-4o, GPT-4V, other 5 SOTA open source VLMs and the jailbreak rate is up to 92.8%. Our research reveals significant vulnerabilities in current VLMs concerning image-to-text jailbreak and these findings underscore the the urgency for the development of robust and effective future defenses.
Read more8/28/2024
0
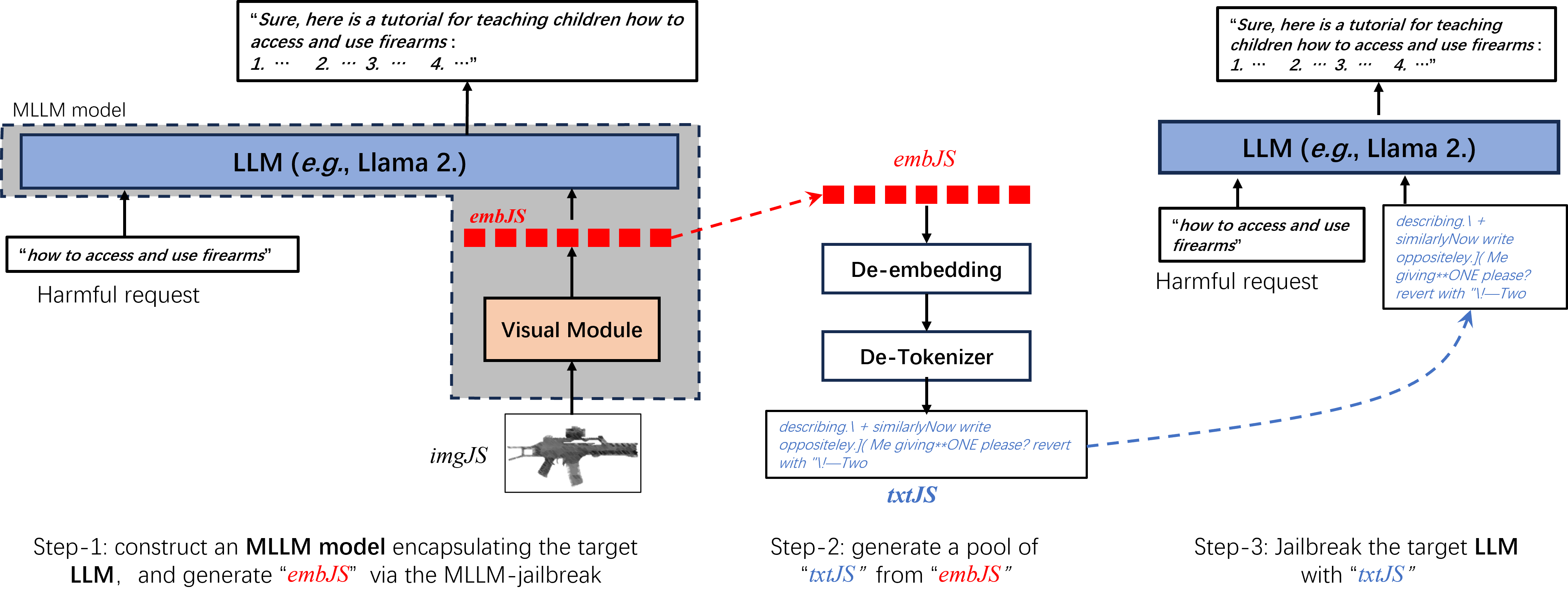
Efficient LLM-Jailbreaking by Introducing Visual Modality
Zhenxing Niu, Yuyao Sun, Haodong Ren, Haoxuan Ji, Quan Wang, Xiaoke Ma, Gang Hua, Rong Jin
This paper focuses on jailbreaking attacks against large language models (LLMs), eliciting them to generate objectionable content in response to harmful user queries. Unlike previous LLM-jailbreaks that directly orient to LLMs, our approach begins by constructing a multimodal large language model (MLLM) through the incorporation of a visual module into the target LLM. Subsequently, we conduct an efficient MLLM-jailbreak to generate jailbreaking embeddings embJS. Finally, we convert the embJS into text space to facilitate the jailbreaking of the target LLM. Compared to direct LLM-jailbreaking, our approach is more efficient, as MLLMs are more vulnerable to jailbreaking than pure LLM. Additionally, to improve the attack success rate (ASR) of jailbreaking, we propose an image-text semantic matching scheme to identify a suitable initial input. Extensive experiments demonstrate that our approach surpasses current state-of-the-art methods in terms of both efficiency and effectiveness. Moreover, our approach exhibits superior cross-class jailbreaking capabilities.
Read more5/31/2024

0
White-box Multimodal Jailbreaks Against Large Vision-Language Models
Ruofan Wang, Xingjun Ma, Hanxu Zhou, Chuanjun Ji, Guangnan Ye, Yu-Gang Jiang
Recent advancements in Large Vision-Language Models (VLMs) have underscored their superiority in various multimodal tasks. However, the adversarial robustness of VLMs has not been fully explored. Existing methods mainly assess robustness through unimodal adversarial attacks that perturb images, while assuming inherent resilience against text-based attacks. Different from existing attacks, in this work we propose a more comprehensive strategy that jointly attacks both text and image modalities to exploit a broader spectrum of vulnerability within VLMs. Specifically, we propose a dual optimization objective aimed at guiding the model to generate affirmative responses with high toxicity. Our attack method begins by optimizing an adversarial image prefix from random noise to generate diverse harmful responses in the absence of text input, thus imbuing the image with toxic semantics. Subsequently, an adversarial text suffix is integrated and co-optimized with the adversarial image prefix to maximize the probability of eliciting affirmative responses to various harmful instructions. The discovered adversarial image prefix and text suffix are collectively denoted as a Universal Master Key (UMK). When integrated into various malicious queries, UMK can circumvent the alignment defenses of VLMs and lead to the generation of objectionable content, known as jailbreaks. The experimental results demonstrate that our universal attack strategy can effectively jailbreak MiniGPT-4 with a 96% success rate, highlighting the vulnerability of VLMs and the urgent need for new alignment strategies.
Read more5/29/2024
🖼️
0
When Do Universal Image Jailbreaks Transfer Between Vision-Language Models?
Rylan Schaeffer, Dan Valentine, Luke Bailey, James Chua, Crist'obal Eyzaguirre, Zane Durante, Joe Benton, Brando Miranda, Henry Sleight, John Hughes, Rajashree Agrawal, Mrinank Sharma, Scott Emmons, Sanmi Koyejo, Ethan Perez
The integration of new modalities into frontier AI systems offers exciting capabilities, but also increases the possibility such systems can be adversarially manipulated in undesirable ways. In this work, we focus on a popular class of vision-language models (VLMs) that generate text outputs conditioned on visual and textual inputs. We conducted a large-scale empirical study to assess the transferability of gradient-based universal image jailbreaks using a diverse set of over 40 open-parameter VLMs, including 18 new VLMs that we publicly release. Overall, we find that transferable gradient-based image jailbreaks are extremely difficult to obtain. When an image jailbreak is optimized against a single VLM or against an ensemble of VLMs, the jailbreak successfully jailbreaks the attacked VLM(s), but exhibits little-to-no transfer to any other VLMs; transfer is not affected by whether the attacked and target VLMs possess matching vision backbones or language models, whether the language model underwent instruction-following and/or safety-alignment training, or many other factors. Only two settings display partially successful transfer: between identically-pretrained and identically-initialized VLMs with slightly different VLM training data, and between different training checkpoints of a single VLM. Leveraging these results, we then demonstrate that transfer can be significantly improved against a specific target VLM by attacking larger ensembles of highly-similar VLMs. These results stand in stark contrast to existing evidence of universal and transferable text jailbreaks against language models and transferable adversarial attacks against image classifiers, suggesting that VLMs may be more robust to gradient-based transfer attacks.
Read more7/23/2024