ImageNot: A contrast with ImageNet preserves model rankings

0

Sign in to get full access
Overview
- The paper proposes a new dataset called "ImageNot" as a contrast to the widely-used ImageNet dataset for evaluating computer vision models.
- The key finding is that model rankings on ImageNot preserve the rankings obtained on ImageNet, suggesting ImageNot could be a viable alternative for benchmarking.
- The authors create ImageNot by modifying ImageNet images to reduce their visual similarity to the original images, while preserving the semantic content.
Plain English Explanation
Imagine you're training a computer to recognize different objects in images, like cats, dogs, or cars. Researchers often use a famous dataset called ImageNet to test and compare the performance of these computer vision models. ImageNet contains millions of images across thousands of categories.
However, the ImageNet dataset has some limitations. The images can be very similar to each other, making it easier for models to learn shortcuts and recognize objects without truly understanding them. The authors of this paper wanted to create a new dataset that would be more challenging and force models to learn more robust and generalizable representations.
They call this new dataset "ImageNot" - a play on the idea that it's the opposite, or "not," the original ImageNet. To create ImageNot, they took the ImageNet images and made subtle changes, like altering the colors or textures, to reduce the visual similarity between images in the same category. But they made sure to preserve the semantic content, so a picture of a cat in ImageNet would still be a picture of a cat in ImageNot.
The key finding is that even with these modifications, the rankings of different computer vision models on ImageNot closely matched their rankings on the original ImageNet dataset. This suggests that ImageNot could be a viable alternative for benchmarking model performance, providing a more challenging and potentially more meaningful test of a model's capabilities.
Technical Explanation
The paper introduces a new dataset called "ImageNot" as a contrast to the widely-used ImageNet dataset for evaluating computer vision models. The authors hypothesized that by reducing the visual similarity between images in the same category, ImageNot would provide a more challenging testbed for models while still preserving the underlying semantic content.
To create ImageNot, the authors took the ImageNet images and applied a series of transformations, including color jittering, texture mixing, and style transfer. These modifications reduced the low-level visual similarity between images in the same category, while maintaining the high-level semantic information.
The authors then evaluated the performance of several state-of-the-art computer vision models on both ImageNet and ImageNot. Surprisingly, they found that the rankings of the models on ImageNot closely matched their rankings on the original ImageNet dataset, despite the significant changes made to the images.
This finding suggests that ImageNot could serve as a viable alternative to ImageNet for benchmarking model performance. By providing a more challenging test set that still preserves the underlying semantic structure, ImageNot may encourage the development of more robust and generalizable computer vision models.
Critical Analysis
The authors acknowledge that ImageNot is not a perfect substitute for ImageNet, as the dataset modifications could introduce new biases or challenges that are not representative of real-world visual recognition tasks. Additionally, the paper does not explore the extent to which the performance on ImageNot correlates with real-world deployment scenarios.
Furthermore, the authors' claim that ImageNot "preserves model rankings" is based on a limited set of experiments, and it remains to be seen how well this finding generalizes to a wider range of models and tasks. It would be helpful to see more extensive evaluations, including on emerging model architectures and training approaches.
Nevertheless, the introduction of ImageNot as a novel dataset for computer vision benchmarking is a valuable contribution to the field. The authors' approach of introducing controlled shifts in the visual characteristics of images, while preserving semantic content, represents an interesting and potentially fruitful direction for creating more challenging and informative evaluation datasets.
Conclusion
The ImageNot dataset proposed in this paper offers a compelling alternative to the widely-used ImageNet benchmark for evaluating computer vision models. By reducing the visual similarity between images within the same categories, ImageNot poses a more challenging test for models, potentially encouraging the development of more robust and generalizable visual recognition systems.
The key finding that model rankings on ImageNot closely match those on ImageNet suggests that ImageNot could serve as a viable substitute for benchmarking, providing a more rigorous assessment of a model's capabilities. While further research is needed to fully understand the implications and limitations of the ImageNot dataset, this work represents an important step towards creating more meaningful and informative evaluation tools for the computer vision community.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
ImageNot: A contrast with ImageNet preserves model rankings
Olawale Salaudeen, Moritz Hardt
We introduce ImageNot, a dataset designed to match the scale of ImageNet while differing drastically in other aspects. We show that key model architectures developed for ImageNet over the years rank identically when trained and evaluated on ImageNot to how they rank on ImageNet. This is true when training models from scratch or fine-tuning them. Moreover, the relative improvements of each model over earlier models strongly correlate in both datasets. We further give evidence that ImageNot has a similar utility as ImageNet for transfer learning purposes. Our work demonstrates a surprising degree of external validity in the relative performance of image classification models. This stands in contrast with absolute accuracy numbers that typically drop sharply even under small changes to a dataset.
Read more4/3/2024

0
ImagiNet: A Multi-Content Dataset for Generalizable Synthetic Image Detection via Contrastive Learning
Delyan Boychev, Radostin Cholakov
Generative models, such as diffusion models (DMs), variational autoencoders (VAEs), and generative adversarial networks (GANs), produce images with a level of authenticity that makes them nearly indistinguishable from real photos and artwork. While this capability is beneficial for many industries, the difficulty of identifying synthetic images leaves online media platforms vulnerable to impersonation and misinformation attempts. To support the development of defensive methods, we introduce ImagiNet, a high-resolution and balanced dataset for synthetic image detection, designed to mitigate potential biases in existing resources. It contains 200K examples, spanning four content categories: photos, paintings, faces, and uncategorized. Synthetic images are produced with open-source and proprietary generators, whereas real counterparts of the same content type are collected from public datasets. The structure of ImagiNet allows for a two-track evaluation system: i) classification as real or synthetic and ii) identification of the generative model. To establish a baseline, we train a ResNet-50 model using a self-supervised contrastive objective (SelfCon) for each track. The model demonstrates state-of-the-art performance and high inference speed across established benchmarks, achieving an AUC of up to 0.99 and balanced accuracy ranging from 86% to 95%, even under social network conditions that involve compression and resizing. Our data and code are available at https://github.com/delyan-boychev/imaginet.
Read more7/30/2024
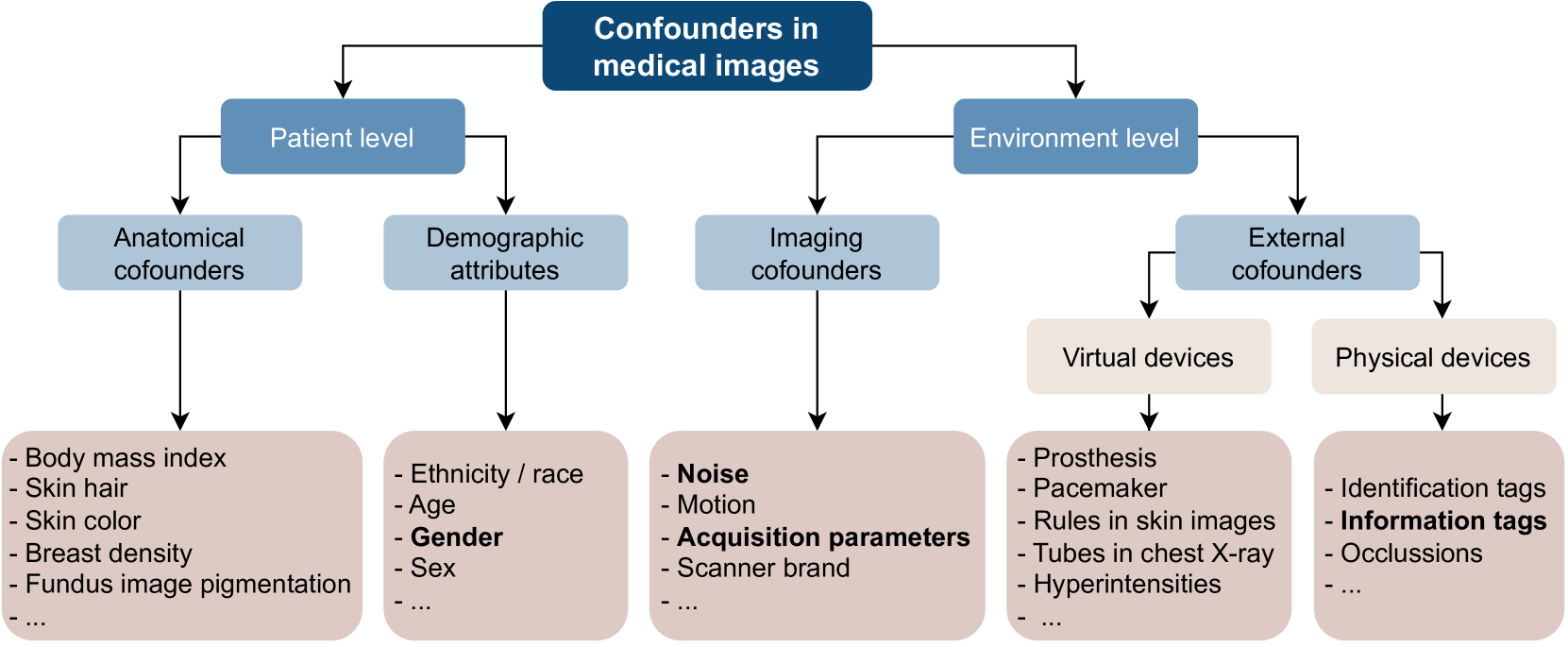
0
Source Matters: Source Dataset Impact on Model Robustness in Medical Imaging
Dovile Juodelyte, Yucheng Lu, Amelia Jim'enez-S'anchez, Sabrina Bottazzi, Enzo Ferrante, Veronika Cheplygina
Transfer learning has become an essential part of medical imaging classification algorithms, often leveraging ImageNet weights. The domain shift from natural to medical images has prompted alternatives such as RadImageNet, often showing comparable classification performance. However, it remains unclear whether the performance gains from transfer learning stem from improved generalization or shortcut learning. To address this, we conceptualize confounders by introducing the Medical Imaging Contextualized Confounder Taxonomy (MICCAT) and investigate a range of confounders across it -- whether synthetic or sampled from the data -- using two public chest X-ray and CT datasets. We show that ImageNet and RadImageNet achieve comparable classification performance, yet ImageNet is much more prone to overfitting to confounders. We recommend that researchers using ImageNet-pretrained models reexamine their model robustness by conducting similar experiments. Our code and experiments are available at https://github.com/DovileDo/source-matters.
Read more8/20/2024

0
Img-Diff: Contrastive Data Synthesis for Multimodal Large Language Models
Qirui Jiao, Daoyuan Chen, Yilun Huang, Yaliang Li, Ying Shen
High-performance Multimodal Large Language Models (MLLMs) rely heavily on data quality. This study introduces a novel dataset named Img-Diff, designed to enhance fine-grained image recognition in MLLMs by leveraging insights from contrastive learning and image difference captioning. By analyzing object differences between similar images, we challenge models to identify both matching and distinct components. We utilize the Stable-Diffusion-XL model and advanced image editing techniques to create pairs of similar images that highlight object replacements. Our methodology includes a Difference Area Generator for object differences identifying, followed by a Difference Captions Generator for detailed difference descriptions. The result is a relatively small but high-quality dataset of object replacement samples. We use the the proposed dataset to finetune state-of-the-art (SOTA) MLLMs such as MGM-7B, yielding comprehensive improvements of performance scores over SOTA models that trained with larger-scale datasets, in numerous image difference and Visual Question Answering tasks. For instance, our trained models notably surpass the SOTA models GPT-4V and Gemini on the MMVP benchmark. Besides, we investigate alternative methods for generating image difference data through object removal and conduct a thorough evaluation to confirm the dataset's diversity, quality, and robustness, presenting several insights on the synthesis of such a contrastive dataset. To encourage further research and advance the field of multimodal data synthesis and enhancement of MLLMs' fundamental capabilities for image understanding, we release our codes and dataset at https://github.com/modelscope/data-juicer/tree/ImgDiff.
Read more8/12/2024