Source Matters: Source Dataset Impact on Model Robustness in Medical Imaging

0
Sign in to get full access
Overview
- The research paper explores the impact of the source dataset on the robustness of medical imaging models.
- It investigates how the selection of the training dataset affects the model's performance and generalization to different real-world scenarios.
- The paper proposes a standardized taxonomy for medical image classification tasks and conducts extensive experiments to understand the source dataset's influence.
Plain English Explanation
The researchers wanted to understand how the choice of the training dataset affects the performance and reliability of AI models used in medical imaging. They recognized that models trained on one type of medical data may not work as well when applied to different real-world scenarios.
To study this, the researchers created a standardized system for categorizing medical image classification tasks. This allowed them to systematically test how models perform when trained on different datasets and then evaluated on related but distinct tasks.
The key insight from their experiments is that the choice of the training dataset has a substantial impact on the model's robustness. Models trained on datasets that are more representative of real-world diversity tended to perform better and generalize more effectively to new scenarios. In contrast, models trained on narrow or biased datasets struggled when faced with variations in the input data.
The researchers emphasize the importance of carefully selecting the training data to ensure medical imaging models can be reliably deployed in clinical practice. Their work highlights the need to go beyond just maximizing performance on a single benchmark and instead focus on building models that are truly robust to the diverse cases encountered in the real world.
Technical Explanation
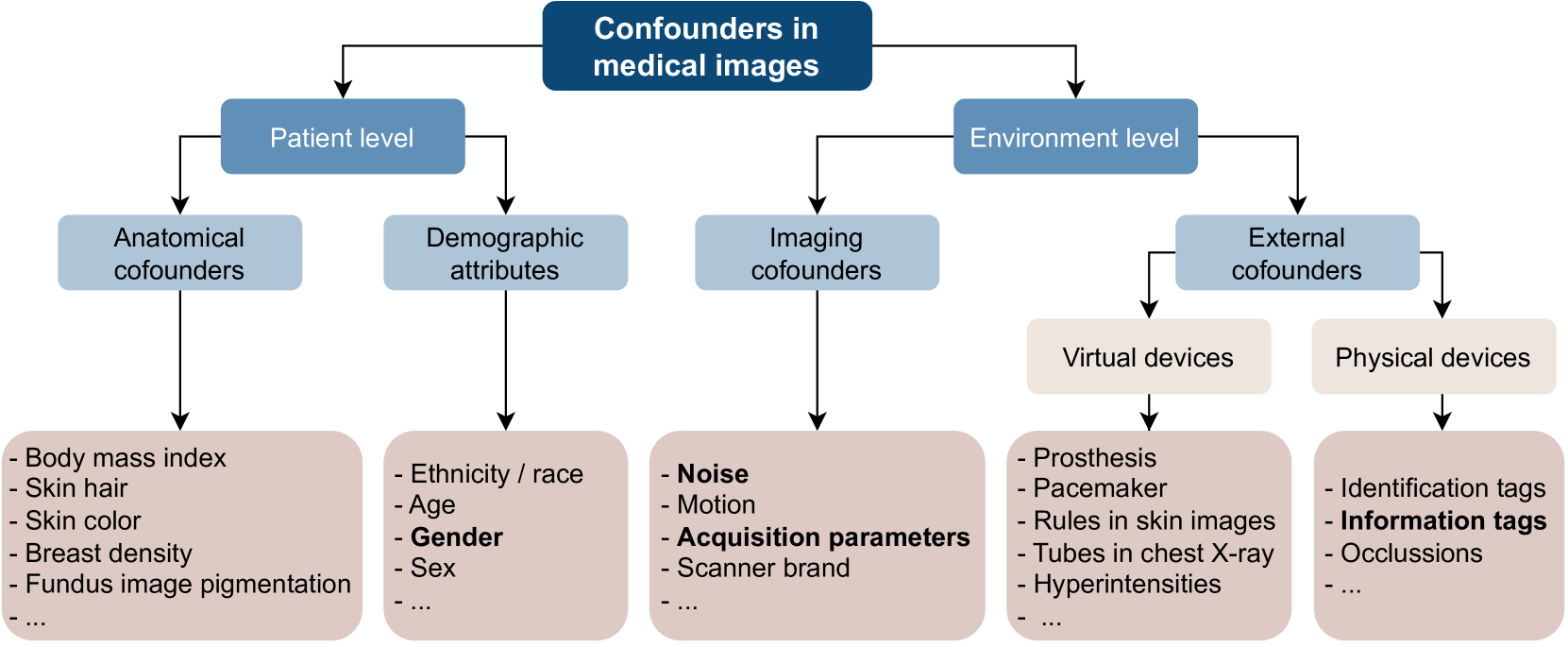
The researchers proposed the MICCAT (Medical Image Classification Categorization Taxonomy) framework to systematically assess the impact of the source dataset on model robustness. MICCAT defines a hierarchical taxonomy of medical image classification tasks based on factors like imaging modality, body region, and clinical task.
Using this taxonomy, the researchers conducted extensive experiments training classification models on different source datasets and evaluating their performance on related but distinct target tasks. They found that models trained on datasets with greater diversity and distribution alignment to the target task tended to exhibit stronger robustness.
Specifically, the researchers observed that transfer learning from a broader, more representative source dataset led to better performance compared to training solely on the target dataset or using a narrow source dataset. They also identified "shortcut" patterns learned by the models that were specific to the source dataset, demonstrating how this can lead to poor generalization.
The paper's key technical contributions are the MICCAT taxonomy, the experimental protocol for evaluating model robustness, and the insights into how the choice of the source dataset impacts classification performance and generalization. The researchers emphasize the need for the medical imaging community to move beyond single-dataset benchmarks and instead focus on building models that can reliably handle the diverse real-world scenarios encountered in clinical practice.
Critical Analysis
The research presented in this paper makes an important contribution to understanding the challenges of building robust medical imaging models. The authors rightly point out that performance on a single benchmark dataset is an incomplete measure of a model's practical utility, as it may not generalize well to the varied cases seen in the real world.
One limitation of the study is that the experiments were conducted on a relatively small number of datasets, all of which were from the medical domain. It would be valuable to extend this analysis to a broader range of medical and non-medical datasets to further validate the findings.
Additionally, the paper does not deeply explore the reasons why certain source datasets lead to more robust models. While the concept of "shortcut" learning is introduced, a more detailed investigation of the specific factors (e.g., dataset size, diversity, label distribution) that impact transfer learning performance could provide additional insights.
Future research could also examine the relationship between model architecture, training procedures, and source dataset selection. Certain model types or learning approaches may be more or less sensitive to the choice of the training data, and understanding these interactions could inform more effective model development strategies.
Overall, this paper makes a strong case for the importance of carefully considering the source dataset when building medical imaging models. Its emphasis on robustness and generalization is a welcome shift from the typical focus on single-benchmark performance, and the work provides a solid foundation for further research in this critical area.
Conclusion
This research paper highlights the significant impact that the choice of the training dataset can have on the robustness and generalization of medical imaging models. By proposing a standardized taxonomy for medical image classification tasks and conducting extensive experiments, the authors demonstrate that models trained on more diverse and representative datasets tend to perform better and generalize more effectively to real-world variations.
The key takeaway is that the medical imaging community needs to move beyond optimizing for single-dataset benchmarks and instead focus on building models that can reliably handle the diverse range of cases encountered in clinical practice. Careful selection of the source dataset, as well as a deeper understanding of the factors that contribute to model robustness, will be crucial for developing AI systems that can be safely and effectively deployed in healthcare settings.
This research paves the way for further advancements in medical imaging AI, highlighting the importance of addressing dataset bias and promoting the development of more generalizable and trustworthy models. As the use of AI in healthcare continues to grow, studies like this one will be instrumental in ensuring that these technologies can be leveraged to improve patient outcomes and support clinical decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Source Matters: Source Dataset Impact on Model Robustness in Medical Imaging
Dovile Juodelyte, Yucheng Lu, Amelia Jim'enez-S'anchez, Sabrina Bottazzi, Enzo Ferrante, Veronika Cheplygina
Transfer learning has become an essential part of medical imaging classification algorithms, often leveraging ImageNet weights. The domain shift from natural to medical images has prompted alternatives such as RadImageNet, often showing comparable classification performance. However, it remains unclear whether the performance gains from transfer learning stem from improved generalization or shortcut learning. To address this, we conceptualize confounders by introducing the Medical Imaging Contextualized Confounder Taxonomy (MICCAT) and investigate a range of confounders across it -- whether synthetic or sampled from the data -- using two public chest X-ray and CT datasets. We show that ImageNet and RadImageNet achieve comparable classification performance, yet ImageNet is much more prone to overfitting to confounders. We recommend that researchers using ImageNet-pretrained models reexamine their model robustness by conducting similar experiments. Our code and experiments are available at https://github.com/DovileDo/source-matters.
Read more8/20/2024
0
Disease Classification and Impact of Pretrained Deep Convolution Neural Networks on Diverse Medical Imaging Datasets across Imaging Modalities
Jutika Borah, Kumaresh Sarmah, Hidam Kumarjit Singh
Imaging techniques such as Chest X-rays, whole slide images, and optical coherence tomography serve as the initial screening and detection for a wide variety of medical pulmonary and ophthalmic conditions respectively. This paper investigates the intricacies of using pretrained deep convolutional neural networks with transfer learning across diverse medical imaging datasets with varying modalities for binary and multiclass classification. We conducted a comprehensive performance analysis with ten network architectures and model families each with pretraining and random initialization. Our finding showed that the use of pretrained models as fixed feature extractors yields poor performance irrespective of the datasets. Contrary, histopathology microscopy whole slide images have better performance. It is also found that deeper and more complex architectures did not necessarily result in the best performance. This observation implies that the improvements in ImageNet are not parallel to the medical imaging tasks. Within a medical domain, the performance of the network architectures varies within model families with shifts in datasets. This indicates that the performance of models within a specific modality may not be conclusive for another modality within the same domain. This study provides a deeper understanding of the applications of deep learning techniques in medical imaging and highlights the impact of pretrained networks across different medical imaging datasets under five different experimental settings.
Read more9/4/2024

0
MedMNIST-C: Comprehensive benchmark and improved classifier robustness by simulating realistic image corruptions
Francesco Di Salvo, Sebastian Doerrich, Christian Ledig
The integration of neural-network-based systems into clinical practice is limited by challenges related to domain generalization and robustness. The computer vision community established benchmarks such as ImageNet-C as a fundamental prerequisite to measure progress towards those challenges. Similar datasets are largely absent in the medical imaging community which lacks a comprehensive benchmark that spans across imaging modalities and applications. To address this gap, we create and open-source MedMNIST-C, a benchmark dataset based on the MedMNIST+ collection covering 12 datasets and 9 imaging modalities. We simulate task and modality-specific image corruptions of varying severity to comprehensively evaluate the robustness of established algorithms against real-world artifacts and distribution shifts. We further provide quantitative evidence that our simple-to-use artificial corruptions allow for highly performant, lightweight data augmentation to enhance model robustness. Unlike traditional, generic augmentation strategies, our approach leverages domain knowledge, exhibiting significantly higher robustness when compared to widely adopted methods. By introducing MedMNIST-C and open-sourcing the corresponding library allowing for targeted data augmentations, we contribute to the development of increasingly robust methods tailored to the challenges of medical imaging. The code is available at https://github.com/francescodisalvo05/medmnistc-api .
Read more7/24/2024

0
The Impact of Scanner Domain Shift on Deep Learning Performance in Medical Imaging: an Experimental Study
Gregory Szumel, Brian Guo, Darui Lu, Rongze Gui, Tingyu Wang, Nicholas Konz, Maciej A. Mazurowski
Purpose: Medical images acquired using different scanners and protocols can differ substantially in their appearance. This phenomenon, scanner domain shift, can result in a drop in the performance of deep neural networks which are trained on data acquired by one scanner and tested on another. This significant practical issue is well-acknowledged, however, no systematic study of the issue is available across different modalities and diagnostic tasks. Materials and Methods: In this paper, we present a broad experimental study evaluating the impact of scanner domain shift on convolutional neural network performance for different automated diagnostic tasks. We evaluate this phenomenon in common radiological modalities, including X-ray, CT, and MRI. Results: We find that network performance on data from a different scanner is almost always worse than on same-scanner data, and we quantify the degree of performance drop across different datasets. Notably, we find that this drop is most severe for MRI, moderate for X-ray, and quite small for CT, on average, which we attribute to the standardized nature of CT acquisition systems which is not present in MRI or X-ray. We also study how injecting varying amounts of target domain data into the training set, as well as adding noise to the training data, helps with generalization. Conclusion: Our results provide extensive experimental evidence and quantification of the extent of performance drop caused by scanner domain shift in deep learning across different modalities, with the goal of guiding the future development of robust deep learning models for medical image analysis.
Read more9/9/2024