(Implicit) Ensembles of Ensembles: Epistemic Uncertainty Collapse in Large Models

0

Sign in to get full access
Overview
- Examines the phenomenon of "epistemic uncertainty collapse" in large language models
- Proposes that large models implicitly form ensembles of ensembles, leading to reduced uncertainty estimates
- Provides theoretical insights and empirical evidence to support this hypothesis
Plain English Explanation
The research paper explores a phenomenon called "epistemic uncertainty collapse" observed in large language models. These models, which are trained on vast amounts of data, tend to produce highly confident predictions even when facing uncertain or ambiguous inputs.
The authors suggest that this collapse of epistemic uncertainty is due to the models implicitly forming "ensembles of ensembles". In other words, the individual components within the model effectively form their own ensemble, further reducing the overall uncertainty estimates.
This implicit ensemble effect can lead to overly confident predictions, even in cases where the model's true understanding is limited. The paper provides both theoretical reasoning and empirical evidence to support this hypothesis, offering valuable insights into the inner workings of large language models and the challenges of accurately capturing and communicating their uncertainty.
Technical Explanation
The paper begins by introducing the concept of epistemic uncertainty and how it relates to the performance of large language models. It then proposes the "ensembles of ensembles" hypothesis as a potential explanation for the observed uncertainty collapse.
The authors' theoretical framework suggests that the individual components within a large language model, such as attention heads or layers, can be viewed as an ensemble of "mini-models." These mini-models, when combined, form a larger ensemble that further reduces the overall epistemic uncertainty.
To support this hypothesis, the researchers conduct several experiments, including analyzing the uncertainty estimates of individual model components and investigating the impact of architectural choices on uncertainty quantification. The results provide evidence for the "ensembles of ensembles" phenomenon and its role in the epistemic uncertainty collapse observed in large language models.
The paper also discusses the implications of this finding, highlighting the potential challenges in accurately capturing and communicating the true uncertainty of these powerful models. The authors suggest that addressing this issue may require rethinking the training and evaluation of large language models to better preserve and represent their epistemic uncertainty.
Critical Analysis
The paper presents a compelling and well-researched explanation for the epistemic uncertainty collapse in large language models. The proposed "ensembles of ensembles" hypothesis is a novel and insightful contribution to the understanding of these models' inner workings.
However, the paper acknowledges several caveats and limitations in its analysis. For instance, the authors note that the observed uncertainty collapse may be more pronounced in certain types of language models or tasks. Additionally, the paper does not explore the potential impact of other architectural choices or training techniques on the epistemic uncertainty of these models.
Further research may be needed to fully understand the generalizability of the "ensembles of ensembles" phenomenon and its implications for the development and deployment of large language models. Exploring ways to mitigate the uncertainty collapse, such as through specialized training approaches or architectural modifications, could be valuable avenues for future work.
Conclusion
The research paper presents a compelling explanation for the epistemic uncertainty collapse observed in large language models. By proposing the "ensembles of ensembles" hypothesis, the authors offer a theoretical framework and empirical evidence to understand this intriguing phenomenon.
This work has important implications for the development and deployment of large language models, as accurately capturing and communicating their uncertainty is crucial for many real-world applications. The insights provided in this paper can inform future research efforts to address the challenges of uncertainty quantification in these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
(Implicit) Ensembles of Ensembles: Epistemic Uncertainty Collapse in Large Models
Andreas Kirsch
Epistemic uncertainty is crucial for safety-critical applications and out-of-distribution detection tasks. Yet, we uncover a paradoxical phenomenon in deep learning models: an epistemic uncertainty collapse as model complexity increases, challenging the assumption that larger models invariably offer better uncertainty quantification. We propose that this stems from implicit ensembling within large models. To support this hypothesis, we demonstrate epistemic uncertainty collapse empirically across various architectures, from explicit ensembles of ensembles and simple MLPs to state-of-the-art vision models, including ResNets and Vision Transformers -- for the latter, we examine implicit ensemble extraction and decompose larger models into diverse sub-models, recovering epistemic uncertainty. We provide theoretical justification for these phenomena and explore their implications for uncertainty estimation.
Read more9/5/2024
🔎
0
On the Calibration of Epistemic Uncertainty: Principles, Paradoxes and Conflictual Loss
Mohammed Fellaji, Fr'ed'eric Pennerath, Brieuc Conan-Guez, Miguel Couceiro
The calibration of predictive distributions has been widely studied in deep learning, but the same cannot be said about the more specific epistemic uncertainty as produced by Deep Ensembles, Bayesian Deep Networks, or Evidential Deep Networks. Although measurable, this form of uncertainty is difficult to calibrate on an objective basis as it depends on the prior for which a variety of choices exist. Nevertheless, epistemic uncertainty must in all cases satisfy two formal requirements: first, it must decrease when the training dataset gets larger and, second, it must increase when the model expressiveness grows. Despite these expectations, our experimental study shows that on several reference datasets and models, measures of epistemic uncertainty violate these requirements, sometimes presenting trends completely opposite to those expected. These paradoxes between expectation and reality raise the question of the true utility of epistemic uncertainty as estimated by these models. A formal argument suggests that this disagreement is due to a poor approximation of the posterior distribution rather than to a flaw in the measure itself. Based on this observation, we propose a regularization function for deep ensembles, called conflictual loss in line with the above requirements. We emphasize its strengths by showing experimentally that it restores both requirements of epistemic uncertainty, without sacrificing either the performance or the calibration of the deep ensembles.
Read more7/18/2024
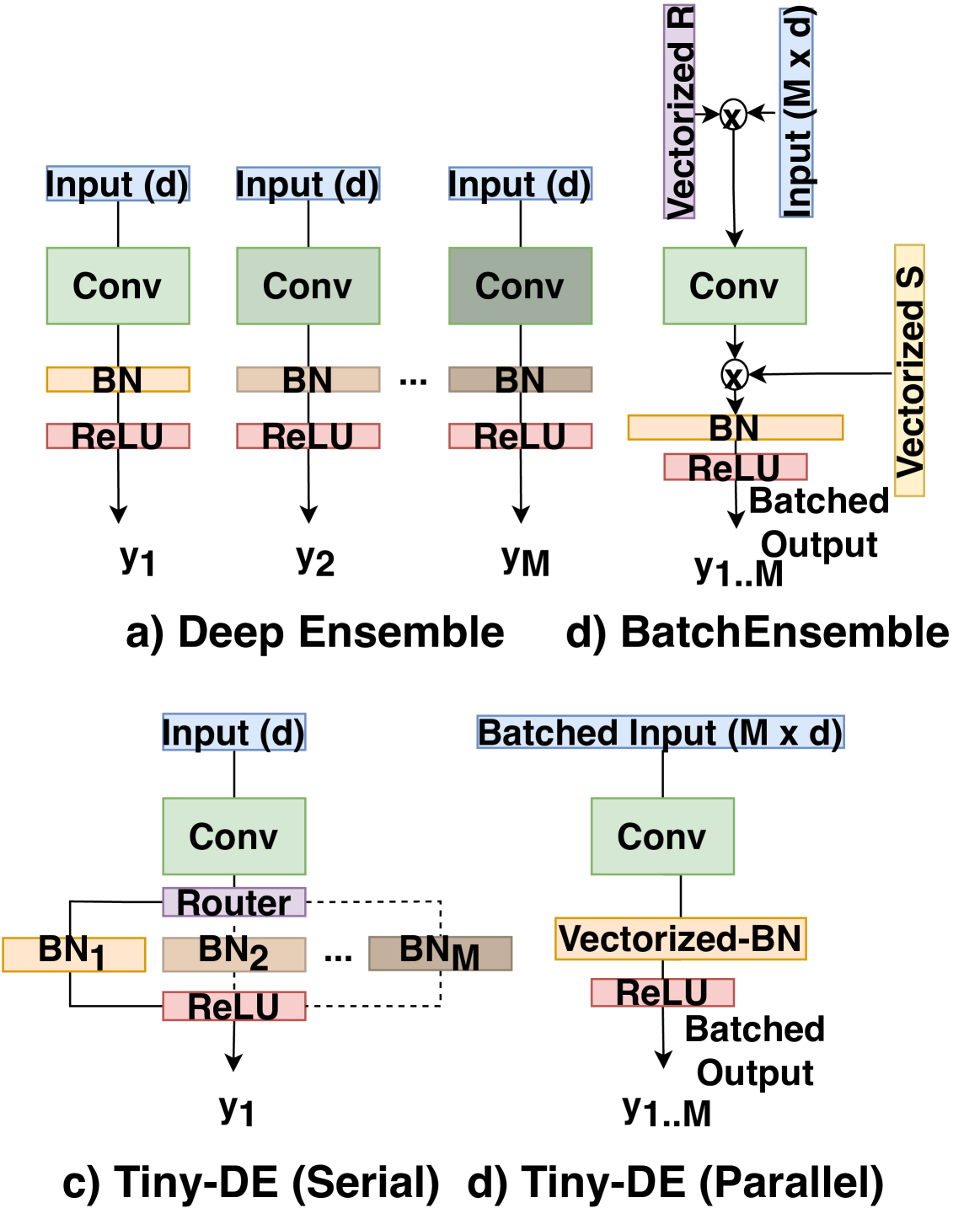
0
Tiny Deep Ensemble: Uncertainty Estimation in Edge AI Accelerators via Ensembling Normalization Layers with Shared Weights
Soyed Tuhin Ahmed, Michael Hefenbrock, Mehdi B. Tahoori
The applications of artificial intelligence (AI) are rapidly evolving, and they are also commonly used in safety-critical domains, such as autonomous driving and medical diagnosis, where functional safety is paramount. In AI-driven systems, uncertainty estimation allows the user to avoid overconfidence predictions and achieve functional safety. Therefore, the robustness and reliability of model predictions can be improved. However, conventional uncertainty estimation methods, such as the deep ensemble method, impose high computation and, accordingly, hardware (latency and energy) overhead because they require the storage and processing of multiple models. Alternatively, Monte Carlo dropout (MC-dropout) methods, although having low memory overhead, necessitate numerous ($sim 100$) forward passes, leading to high computational overhead and latency. Thus, these approaches are not suitable for battery-powered edge devices with limited computing and memory resources. In this paper, we propose the Tiny-Deep Ensemble approach, a low-cost approach for uncertainty estimation on edge devices. In our approach, only normalization layers are ensembled $M$ times, with all ensemble members sharing common weights and biases, leading to a significant decrease in storage requirements and latency. Moreover, our approach requires only one forward pass in a hardware architecture that allows batch processing for inference and uncertainty estimation. Furthermore, it has approximately the same memory overhead compared to a single model. Therefore, latency and memory overhead are reduced by a factor of up to $sim Mtimes$. Nevertheless, our method does not compromise accuracy, with an increase in inference accuracy of up to $sim 1%$ and a reduction in RMSE of $17.17%$ in various benchmark datasets, tasks, and state-of-the-art architectures.
Read more5/10/2024
📉
0
LoRA-Ensemble: Efficient Uncertainty Modelling for Self-attention Networks
Michelle Halbheer, Dominik J. Muhlematter, Alexander Becker, Dominik Narnhofer, Helge Aasen, Konrad Schindler, Mehmet Ozgur Turkoglu
Numerous crucial tasks in real-world decision-making rely on machine learning algorithms with calibrated uncertainty estimates. However, modern methods often yield overconfident and uncalibrated predictions. Various approaches involve training an ensemble of separate models to quantify the uncertainty related to the model itself, known as epistemic uncertainty. In an explicit implementation, the ensemble approach has high computational cost and high memory requirements. This particular challenge is evident in state-of-the-art neural networks such as transformers, where even a single network is already demanding in terms of compute and memory. Consequently, efforts are made to emulate the ensemble model without actually instantiating separate ensemble members, referred to as implicit ensembling. We introduce LoRA-Ensemble, a parameter-efficient deep ensemble method for self-attention networks, which is based on Low-Rank Adaptation (LoRA). Initially developed for efficient LLM fine-tuning, we extend LoRA to an implicit ensembling approach. By employing a single pre-trained self-attention network with weights shared across all members, we train member-specific low-rank matrices for the attention projections. Our method exhibits superior calibration compared to explicit ensembles and achieves similar or better accuracy across various prediction tasks and datasets.
Read more5/24/2024