Improve Student's Reasoning Generalizability through Cascading Decomposed CoTs Distillation
2405.19842
0
0
Abstract
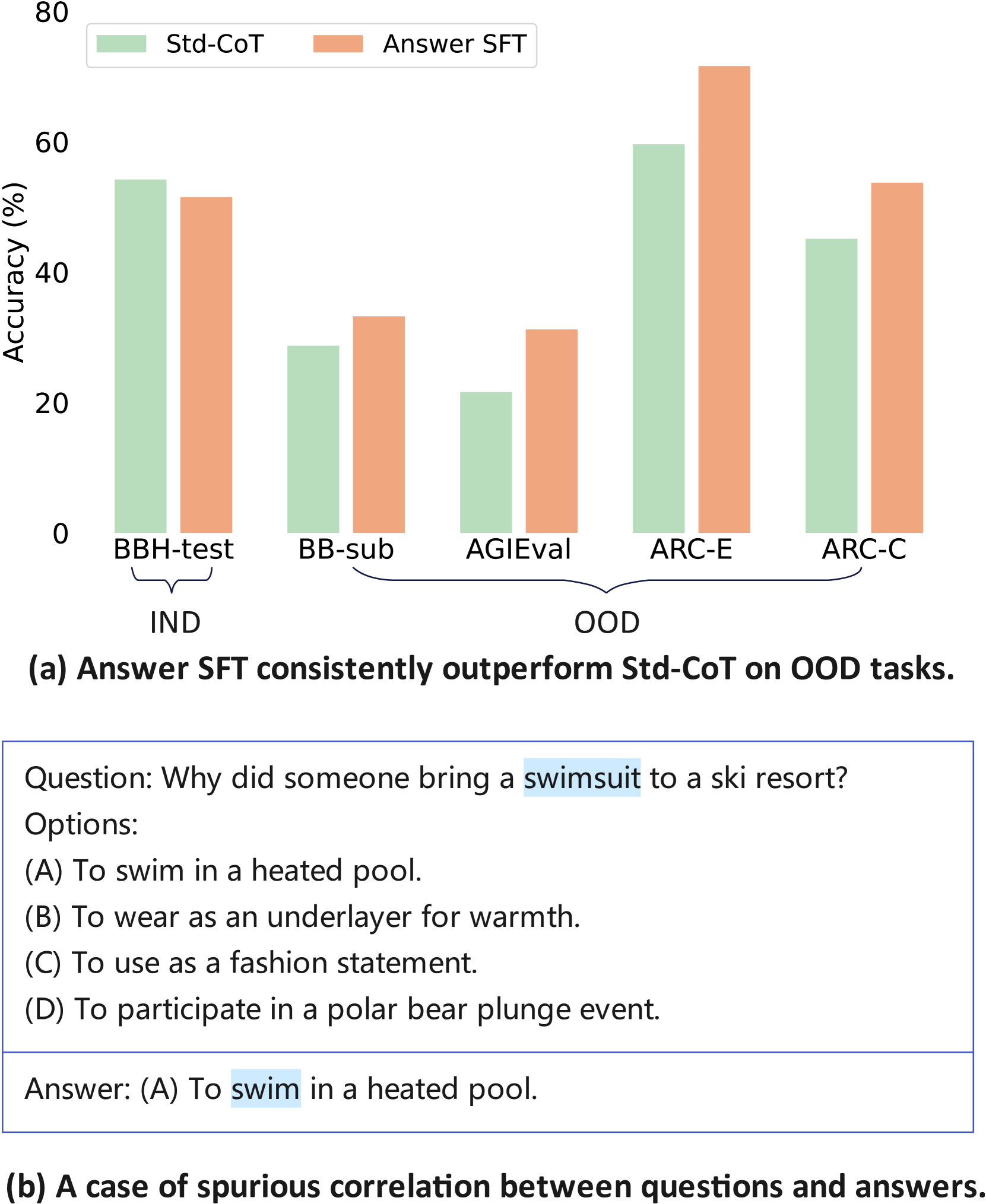
Large language models (LLMs) exhibit enhanced reasoning at larger scales, driving efforts to distill these capabilities into smaller models via teacher-student learning. Previous works simply fine-tune student models on teachers' generated Chain-of-Thoughts (CoTs) data. Although these methods enhance in-domain (IND) reasoning performance, they struggle to generalize to out-of-domain (OOD) tasks. We believe that the widespread spurious correlations between questions and answers may lead the model to preset a specific answer which restricts the diversity and generalizability of its reasoning process. In this paper, we propose Cascading Decomposed CoTs Distillation (CasCoD) to address these issues by decomposing the traditional single-step learning process into two cascaded learning steps. Specifically, by restructuring the training objectives -- removing the answer from outputs and concatenating the question with the rationale as input -- CasCoD's two-step learning process ensures that students focus on learning rationales without interference from the preset answers, thus improving reasoning generalizability. Extensive experiments demonstrate the effectiveness of CasCoD on both IND and OOD benchmark reasoning datasets. Code can be found at https://github.com/C-W-D/CasCoD.
Create account to get full access
Overview
- This paper introduces a method called "Cascading Decomposed CoTs Distillation" to improve students' reasoning generalizability.
- The approach involves distilling knowledge from a large language model that performs multi-step reasoning, and transferring this knowledge to a smaller student model.
- The key ideas include decomposing the reasoning process into steps, and using a "cascading" approach to gradually transfer knowledge from the teacher to the student.
Plain English Explanation
The paper is focused on helping smaller AI models (like chatbots or virtual assistants) become better at multi-step reasoning and problem-solving. The main idea is to take a large, powerful AI model that is good at this kind of "chain of thought" reasoning, and use a special training process to transfer its knowledge to a smaller, simpler model.
The process involves breaking down the reasoning process into a series of smaller steps, and then gradually teaching the smaller model how to do each step. This "cascading" approach allows the knowledge to be transferred effectively, even though the smaller model has more limited capabilities. The paper cites related work like that also explored decomposing reasoning into steps.
The goal is to end up with a smaller AI assistant that can still perform complex, multi-step reasoning, but in a more efficient and scalable way. This could be useful for deploying AI systems on devices with limited computing power, or for creating AI tutors and educational tools that can provide personalized, step-by-step guidance.
Technical Explanation
The key technical ideas in the paper are:
-
Cascading Decomposed CoTs Distillation: This is the core training process, where knowledge is distilled from a large "teacher" model that can perform multi-step "Chain of Thought" (CoT) reasoning, and transferred to a smaller "student" model. The process involves decomposing the reasoning into a sequence of steps, and gradually teaching the student model to mimic each step.
-
Decomposing Reasoning into Steps: The researchers break down the overall reasoning process into a series of sub-tasks or "reasoning steps." This allows the knowledge to be transferred in a more structured and interpretable way.
-
Cascading Knowledge Transfer: The distillation process happens in a "cascading" manner, where the student model first learns the easiest reasoning steps, and then progressively takes on more complex ones. This helps the student model build up its capabilities incrementally.
The paper presents experiments on both language understanding and math problem-solving tasks, showing that the proposed method can significantly improve the reasoning skills of the student model compared to other knowledge distillation approaches. The authors build on prior work like that explored similar ideas of decomposing reasoning.
Critical Analysis
The paper presents a promising approach to improving the reasoning capabilities of smaller AI models. The core ideas of decomposing reasoning and using a cascading distillation process seem well-motivated and the experimental results are compelling.
However, the paper does not provide much insight into the limitations or potential failure modes of the method. For example, it's unclear how sensitive the approach is to the specific way the reasoning process is decomposed, or how well it would scale to very complex reasoning tasks.
Additionally, the paper does not address potential issues around the interpretability and transparency of the distilled student models. While the decomposition into steps may help, it's unclear if the students will be able to provide clear, step-by-step explanations of their reasoning.
Further research could explore how to better incorporate human-understandable representations and reasoning steps into the distillation process. There may also be opportunities to apply this approach to other domains beyond language and math, such as physical reasoning or common sense understanding.
Conclusion
Overall, the "Cascading Decomposed CoTs Distillation" method presented in this paper is a promising step towards creating more capable and efficient AI assistants. By distilling knowledge from powerful "teacher" models in a structured, step-by-step manner, the researchers have shown that it's possible to imbue smaller "student" models with strong multi-step reasoning skills.
This work could have important implications for deploying AI systems in resource-constrained environments, as well as for developing educational and training tools that can provide personalized, interpretable guidance. While the paper raises some open questions, it represents an exciting advance in the field of AI reasoning and knowledge transfer.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Beyond Imitation: Learning Key Reasoning Steps from Dual Chain-of-Thoughts in Reasoning Distillation
Chengwei Dai, Kun Li, Wei Zhou, Songlin Hu
0
0
As Large Language Models (LLMs) scale up and gain powerful Chain-of-Thoughts (CoTs) reasoning abilities, practical resource constraints drive efforts to distill these capabilities into more compact Smaller Language Models (SLMs). We find that CoTs consist mainly of simple reasoning forms, with a small proportion ($approx 4.7%$) of key reasoning steps that truly impact conclusions. However, previous distillation methods typically involve supervised fine-tuning student SLMs only on correct CoTs data produced by teacher LLMs, resulting in students struggling to learn the key reasoning steps, instead imitating the teacher's reasoning forms and making errors or omissions on these steps. To address these issues, drawing an analogy to human learning, where analyzing mistakes according to correct solutions often reveals the crucial steps leading to successes or failures, we propose mistaktextbf{E}-textbf{D}riven key reasontextbf{I}ng step distillatextbf{T}ion (textbf{EDIT}), a novel method that further aids SLMs learning key reasoning steps rather than mere simple fine-tuning. Firstly, to expose these crucial steps in CoTs, we design specific prompts to generate dual CoTs data with similar reasoning paths but divergent conclusions. Then, we apply the minimum edit distance algorithm on the dual CoTs data to locate these key steps and optimize the likelihood of these steps. Extensive experiments validate the effectiveness of EDIT across both in-domain and out-of-domain benchmark reasoning datasets. Further analysis shows that EDIT can generate high-quality CoTs with more correct key reasoning steps. Notably, we also explore how different mistake patterns affect performance and find that EDIT benefits more from logical errors than from knowledge or mathematical calculation errors in dual CoTsfootnote{Code can be found at url{https://github.com/C-W-D/EDIT}}.
5/31/2024

Symbolic Chain-of-Thought Distillation: Small Models Can Also Think Step-by-Step
Liunian Harold Li, Jack Hessel, Youngjae Yu, Xiang Ren, Kai-Wei Chang, Yejin Choi
0
0
Chain-of-thought prompting (e.g., Let's think step-by-step) primes large language models to verbalize rationalization for their predictions. While chain-of-thought can lead to dramatic performance gains, benefits appear to emerge only for sufficiently large models (beyond 50B parameters). We show that orders-of-magnitude smaller models (125M -- 1.3B parameters) can still benefit from chain-of-thought prompting. To achieve this, we introduce Symbolic Chain-of-Thought Distillation (SCoTD), a method to train a smaller student model on rationalizations sampled from a significantly larger teacher model. Experiments across several commonsense benchmarks show that: 1) SCoTD enhances the performance of the student model in both supervised and few-shot settings, and especially for challenge sets; 2) sampling many reasoning chains per instance from the teacher is paramount; and 3) after distillation, student chain-of-thoughts are judged by humans as comparable to the teacher, despite orders of magnitude fewer parameters. We test several hypotheses regarding what properties of chain-of-thought samples are important, e.g., diversity vs. teacher likelihood vs. open-endedness. We release our corpus of chain-of-thought samples and code.
4/17/2024
💬
Multimodal Chain-of-Thought Reasoning in Language Models
Zhuosheng Zhang, Aston Zhang, Mu Li, Hai Zhao, George Karypis, Alex Smola
0
0
Large language models (LLMs) have shown impressive performance on complex reasoning by leveraging chain-of-thought (CoT) prompting to generate intermediate reasoning chains as the rationale to infer the answer. However, existing CoT studies have primarily focused on the language modality. We propose Multimodal-CoT that incorporates language (text) and vision (images) modalities into a two-stage framework that separates rationale generation and answer inference. In this way, answer inference can leverage better generated rationales that are based on multimodal information. Experimental results on ScienceQA and A-OKVQA benchmark datasets show the effectiveness of our proposed approach. With Multimodal-CoT, our model under 1 billion parameters achieves state-of-the-art performance on the ScienceQA benchmark. Our analysis indicates that Multimodal-CoT offers the advantages of mitigating hallucination and enhancing convergence speed. Code is publicly available at https://github.com/amazon-science/mm-cot.
5/21/2024
Investigating Mysteries of CoT-Augmented Distillation
Somin Wadhwa, Silvio Amir, Byron C. Wallace
0
0
Eliciting chain of thought (CoT) rationales -- sequences of token that convey a reasoning process -- has been shown to consistently improve LLM performance on tasks like question answering. More recent efforts have shown that such rationales can also be used for model distillation: Including CoT sequences (elicited from a large teacher model) in addition to target labels when fine-tuning a small student model yields (often substantial) improvements. In this work we ask: Why and how does this additional training signal help in model distillation? We perform ablations to interrogate this, and report some potentially surprising results. Specifically: (1) Placing CoT sequences after labels (rather than before) realizes consistently better downstream performance -- this means that no student reasoning is necessary at test time to realize gains. (2) When rationales are appended in this way, they need not be coherent reasoning sequences to yield improvements; performance increases are robust to permutations of CoT tokens, for example. In fact, (3) a small number of key tokens are sufficient to achieve improvements equivalent to those observed when full rationales are used in model distillation.
6/21/2024