Improved Q-learning based Multi-hop Routing for UAV-Assisted Communication

0
Sign in to get full access
Overview
- Researchers propose an improved Q-learning based multi-hop routing algorithm for UAV-assisted communication networks.
- The algorithm aims to optimize data transmission by selecting the optimal path and reducing energy consumption.
- Experiments show the proposed method outperforms conventional routing algorithms in terms of throughput, end-to-end delay, and energy efficiency.
Plain English Explanation
The paper presents an improved routing algorithm for UAV-assisted communication networks. In these networks, unmanned aerial vehicles (UAVs) are used to extend the coverage and connectivity of wireless networks, especially in areas with limited infrastructure.
The researchers developed a Q-learning based multi-hop routing algorithm to optimize data transmission in these UAV networks. Q-learning is a type of reinforcement learning where the system learns to make optimal decisions by trial and error.
The key idea is to have the UAVs intelligently select the best path to route data between source and destination nodes. This helps maximize throughput, minimize end-to-end delay, and reduce energy consumption, which are all important performance metrics for communication networks.
The algorithm takes into account factors such as the locations of the UAVs, the quality of the wireless links, and the energy levels of the UAVs. By constantly learning and adapting based on this information, the algorithm can continuously optimize the routing decisions to achieve the best overall network performance.
Technical Explanation
The researchers propose an improved Q-learning based multi-hop routing algorithm for UAV-assisted communication networks. The algorithm uses Q-learning, a type of reinforcement learning, to dynamically select the optimal path for data transmission between source and destination nodes.
The key components of the algorithm include:
- State representation: The algorithm models the network state using factors such as UAV locations, link qualities, and UAV energy levels.
- Action selection: Based on the current state, the algorithm selects the next UAV hop that will lead to the optimal end-to-end path.
- Reward function: The reward function is designed to incentivize high throughput, low end-to-end delay, and energy efficiency.
- Q-value update: The Q-values, which represent the expected long-term reward for each action, are updated after each transmission to improve the algorithm's decision-making.
The researchers evaluate the proposed algorithm through extensive simulations and compare it to conventional routing algorithms. The results show that the Q-learning based approach outperforms the alternatives in terms of throughput, end-to-end delay, and energy efficiency.
Critical Analysis
The paper presents a promising Q-learning based routing algorithm for UAV-assisted communication networks. The adaptable and dynamic nature of the algorithm is a key strength, as it allows the system to continuously optimize routing decisions based on the evolving network conditions.
However, the paper does not address several important practical considerations. For example, it assumes perfect knowledge of the network state, which may not be realistic in real-world deployments. Additionally, the scalability of the algorithm as the number of UAVs and nodes increases is not thoroughly explored.
Furthermore, the **paper lacks a comprehensive analysis of the algorithm's robustness to factors such as node failures, link disruptions, and environmental changes. These aspects would be crucial for the algorithm's real-world applicability and reliability.
Future research could focus on addressing these limitations, such as by incorporating imperfect information, exploring distributed implementations, and analyzing the algorithm's performance under various network dynamics and disruptions.
Conclusion
This paper presents an improved Q-learning based multi-hop routing algorithm for UAV-assisted communication networks. The algorithm dynamically selects the optimal data transmission paths to maximize throughput, minimize end-to-end delay, and reduce energy consumption.
The proposed approach shows promising results compared to conventional routing algorithms in simulation-based experiments. However, the paper does not fully address practical considerations such as scalability, robustness, and real-world applicability.
Further research is needed to enhance the algorithm's real-world viability and **explore its potential for **improving the performance and reliability of UAV-assisted communication networks, which are increasingly important for applications like disaster response, surveillance, and infrastructure monitoring.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improved Q-learning based Multi-hop Routing for UAV-Assisted Communication
N P Sharvari, Dibakar Das, Jyotsna Bapat, Debabrata Das
Designing effective Unmanned Aerial Vehicle(UAV)-assisted routing protocols is challenging due to changing topology, limited battery capacity, and the dynamic nature of communication environments. Current protocols prioritize optimizing individual network parameters, overlooking the necessity for a nuanced approach in scenarios with intermittent connectivity, fluctuating signal strength, and varying network densities, ultimately failing to address aerial network requirements comprehensively. This paper proposes a novel, Improved Q-learning-based Multi-hop Routing (IQMR) algorithm for optimal UAV-assisted communication systems. Using Q(lambda) learning for routing decisions, IQMR substantially enhances energy efficiency and network data throughput. IQMR improves system resilience by prioritizing reliable connectivity and inter-UAV collision avoidance while integrating real-time network status information, all in the absence of predefined UAV path planning, thus ensuring dynamic adaptability to evolving network conditions. The results validate IQMR's adaptability to changing system conditions and superiority over the current techniques. IQMR showcases 36.35% and 32.05% improvements in energy efficiency and data throughput over the existing methods.
Read more8/20/2024

0
Optimizing Search and Rescue UAV Connectivity in Challenging Terrain through Multi Q-Learning
Mohammed M. H. Qazzaz, Syed A. R. Zaidi, Desmond C. McLernon, Abdelaziz Salama, Aubida A. Al-Hameed
Using Unmanned Aerial Vehicles (UAVs) in Search and rescue operations (SAR) to navigate challenging terrain while maintaining reliable communication with the cellular network is a promising approach. This paper suggests a novel technique employing a reinforcement learning multi Q-learning algorithm to optimize UAV connectivity in such scenarios. We introduce a Strategic Planning Agent for efficient path planning and collision awareness and a Real-time Adaptive Agent to maintain optimal connection with the cellular base station. The agents trained in a simulated environment using multi Q-learning, encouraging them to learn from experience and adjust their decision-making to diverse terrain complexities and communication scenarios. Evaluation results reveal the significance of the approach, highlighting successful navigation in environments with varying obstacle densities and the ability to perform optimal connectivity using different frequency bands. This work paves the way for enhanced UAV autonomy and enhanced communication reliability in search and rescue operations.
Read more5/17/2024

0
Multi-UAV Multi-RIS QoS-Aware Aerial Communication Systems using DRL and PSO
Marwan Dhuheir, Aiman Erbad, Ala Al-Fuqaha, Mohsen Guizani
Recently, Unmanned Aerial Vehicles (UAVs) have attracted the attention of researchers in academia and industry for providing wireless services to ground users in diverse scenarios like festivals, large sporting events, natural and man-made disasters due to their advantages in terms of versatility and maneuverability. However, the limited resources of UAVs (e.g., energy budget and different service requirements) can pose challenges for adopting UAVs for such applications. Our system model considers a UAV swarm that navigates an area, providing wireless communication to ground users with RIS support to improve the coverage of the UAVs. In this work, we introduce an optimization model with the aim of maximizing the throughput and UAVs coverage through optimal path planning of UAVs and multi-RIS phase configurations. The formulated optimization is challenging to solve using standard linear programming techniques, limiting its applicability in real-time decision-making. Therefore, we introduce a two-step solution using deep reinforcement learning and particle swarm optimization. We conduct extensive simulations and compare our approach to two competitive solutions presented in the recent literature. Our simulation results demonstrate that our adopted approach is 20 % better than the brute-force approach and 30% better than the baseline solution in terms of QoS.
Read more6/26/2024
0
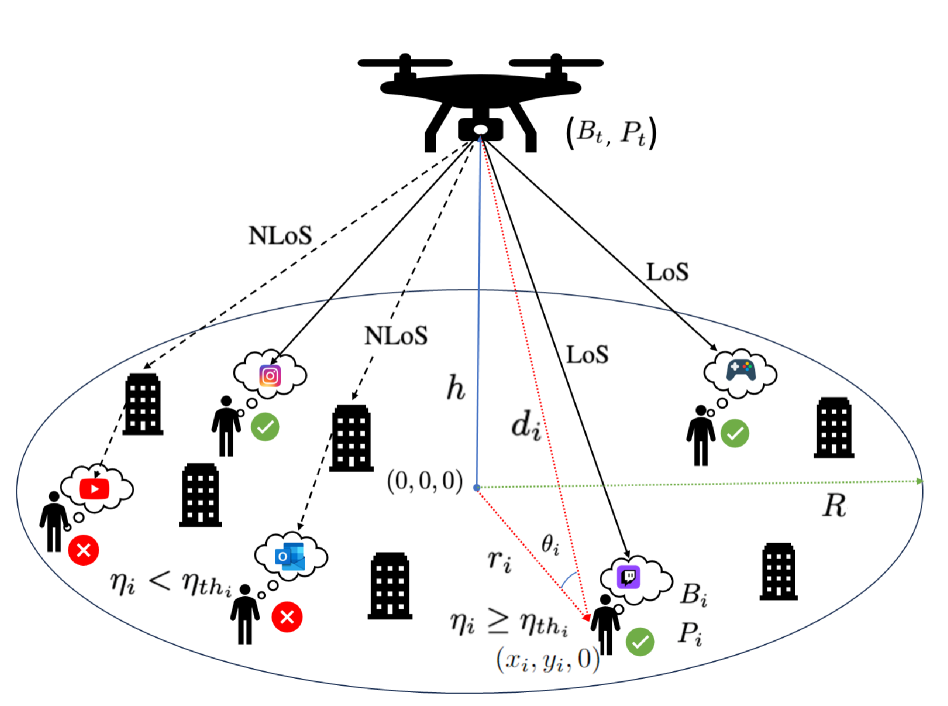
A Novel Joint DRL-Based Utility Optimization for UAV Data Services
Xuli Cai, Poonam Lohan, Burak Kantarci
In this paper, we propose a novel joint deep reinforcement learning (DRL)-based solution to optimize the utility of an uncrewed aerial vehicle (UAV)-assisted communication network. To maximize the number of users served within the constraints of the UAV's limited bandwidth and power resources, we employ deep Q-Networks (DQN) and deep deterministic policy gradient (DDPG) algorithms for optimal resource allocation to ground users with heterogeneous data rate demands. The DQN algorithm dynamically allocates multiple bandwidth resource blocks to different users based on current demand and available resource states. Simultaneously, the DDPG algorithm manages power allocation, continuously adjusting power levels to adapt to varying distances and fading conditions, including Rayleigh fading for non-line-of-sight (NLoS) links and Rician fading for line-of-sight (LoS) links. Our joint DRL-based solution demonstrates an increase of up to 41% in the number of users served compared to scenarios with equal bandwidth and power allocation.
Read more6/18/2024