Improving 2D Feature Representations by 3D-Aware Fine-Tuning

0
Sign in to get full access
Overview
- This paper explores how 3D-aware fine-tuning can improve 2D feature representations.
- The researchers propose a method called "Gaussian Splatting" to incorporate 3D information into 2D feature learning.
- Experiments show that 3D-aware fine-tuning leads to better performance on 2D image classification and segmentation tasks.
Plain English Explanation
When we look at 2D images, our brains naturally infer 3D information about the objects and scenes. For example, we can tell that a ball is spherical, or that a chair has depth and volume. This paper explores how we can teach AI systems to do the same thing.
The researchers developed a technique called "Gaussian Splatting" that allows AI models to learn 2D features while also incorporating 3D information. This is done by taking a 2D image, estimating the 3D structure of the scene, and then "splattering" that 3D information back onto the 2D features during the training process.
The results show that this 3D-aware fine-tuning leads to better performance on a variety of 2D tasks, like classifying objects in images or segmenting different elements of a scene. This suggests that teaching AI systems to reason about 3D information, even if the task is 2D, can lead to more powerful and robust computer vision capabilities.
Technical Explanation
The paper proposes a method called "Gaussian Splatting" to incorporate 3D information into 2D feature learning. The key idea is to estimate the 3D structure of a scene from a 2D image, and then "splatter" that 3D information back onto the 2D feature maps during the fine-tuning process.
Specifically, the researchers first train a 3D reconstruction model to predict the depth and surface normals of a scene from a 2D image. They then use this 3D information to compute a Gaussian distribution for each pixel, representing the uncertainty about the 3D position of that pixel. This Gaussian distribution is then "splattered" onto the 2D feature maps, effectively sharing the 3D cues with the 2D representation.
The researchers show that this 3D-aware fine-tuning leads to significant performance gains on a variety of 2D computer vision tasks, including image classification, object detection, and semantic segmentation. The intuition is that by learning to reason about the 3D structure of a scene, the model can build more powerful and generalizable 2D representations.
Critical Analysis
The paper presents a compelling approach for incorporating 3D information into 2D feature learning, and the experimental results are promising. However, there are a few potential limitations:
-
The method relies on having access to a pre-trained 3D reconstruction model, which may not always be available. It would be interesting to see if the 3D information could be learned directly as part of the 2D feature learning process.
-
The experiments are conducted on relatively simple datasets, like PASCAL VOC and COCO. It's unclear how well the method would scale to more complex, real-world scenarios.
-
The paper does not explore the potential limitations or failure cases of the Gaussian Splatting approach. It would be valuable to understand the conditions under which the method might not work well, and what kinds of improvements or extensions could be made.
Overall, the paper presents a promising direction for incorporating 3D awareness into 2D feature learning, but further research is needed to fully understand the capabilities and limitations of this approach.
Conclusion
This paper introduces a novel method called "Gaussian Splatting" that allows 2D feature representations to be improved by incorporating 3D information during the fine-tuning process. The key idea is to estimate the 3D structure of a scene from a 2D image and then use this 3D cue to enhance the 2D feature maps.
The experimental results demonstrate that this 3D-aware fine-tuning leads to significant performance gains on a variety of 2D computer vision tasks, suggesting that teaching AI systems to reason about 3D information can be a powerful way to build more robust and generalizable visual representations. While the paper presents a compelling approach, there are still some open questions and limitations that warrant further exploration.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving 2D Feature Representations by 3D-Aware Fine-Tuning
Yuanwen Yue, Anurag Das, Francis Engelmann, Siyu Tang, Jan Eric Lenssen
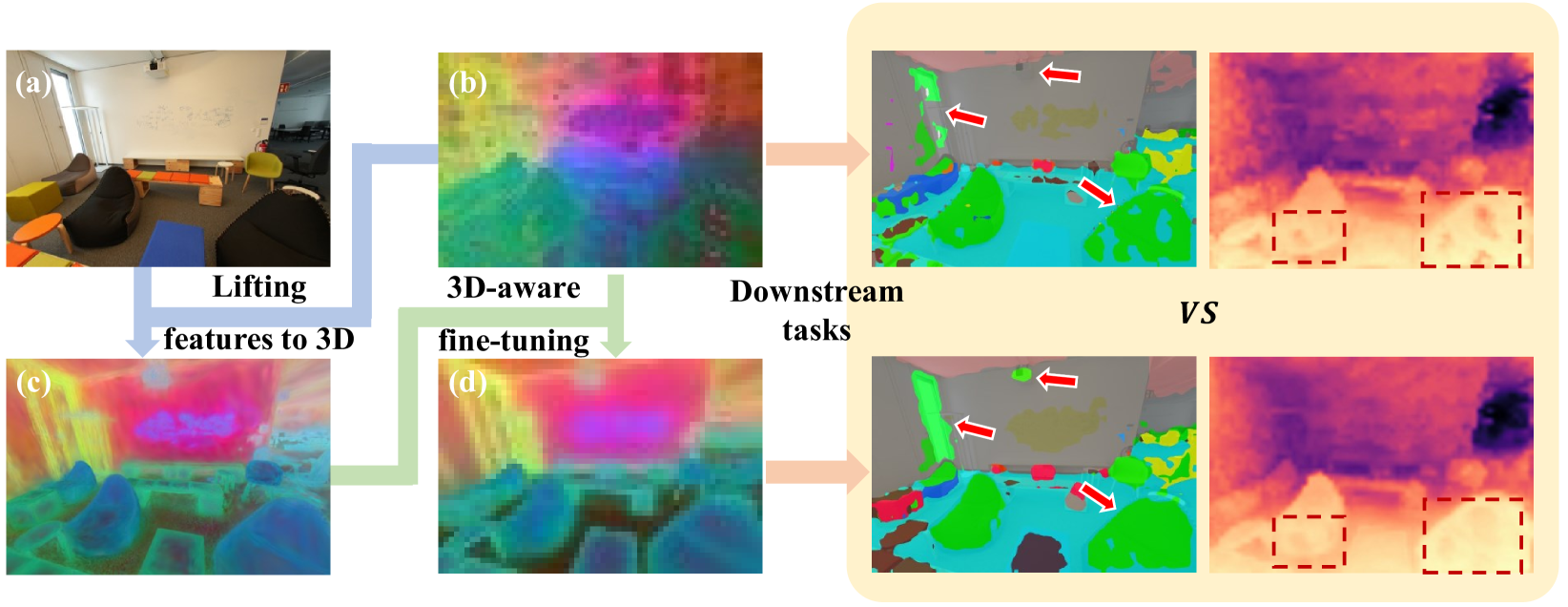
Current visual foundation models are trained purely on unstructured 2D data, limiting their understanding of 3D structure of objects and scenes. In this work, we show that fine-tuning on 3D-aware data improves the quality of emerging semantic features. We design a method to lift semantic 2D features into an efficient 3D Gaussian representation, which allows us to re-render them for arbitrary views. Using the rendered 3D-aware features, we design a fine-tuning strategy to transfer such 3D awareness into a 2D foundation model. We demonstrate that models fine-tuned in that way produce features that readily improve downstream task performance in semantic segmentation and depth estimation through simple linear probing. Notably, though fined-tuned on a single indoor dataset, the improvement is transferable to a variety of indoor datasets and out-of-domain datasets. We hope our study encourages the community to consider injecting 3D awareness when training 2D foundation models. Project page: https://ywyue.github.io/FiT3D.
Read more7/30/2024

0
Probing the 3D Awareness of Visual Foundation Models
Mohamed El Banani, Amit Raj, Kevis-Kokitsi Maninis, Abhishek Kar, Yuanzhen Li, Michael Rubinstein, Deqing Sun, Leonidas Guibas, Justin Johnson, Varun Jampani
Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.
Read more4/15/2024

0
The More You See in 2D, the More You Perceive in 3D
Xinyang Han, Zelin Gao, Angjoo Kanazawa, Shubham Goel, Yossi Gandelsman
Humans can infer 3D structure from 2D images of an object based on past experience and improve their 3D understanding as they see more images. Inspired by this behavior, we introduce SAP3D, a system for 3D reconstruction and novel view synthesis from an arbitrary number of unposed images. Given a few unposed images of an object, we adapt a pre-trained view-conditioned diffusion model together with the camera poses of the images via test-time fine-tuning. The adapted diffusion model and the obtained camera poses are then utilized as instance-specific priors for 3D reconstruction and novel view synthesis. We show that as the number of input images increases, the performance of our approach improves, bridging the gap between optimization-based prior-less 3D reconstruction methods and single-image-to-3D diffusion-based methods. We demonstrate our system on real images as well as standard synthetic benchmarks. Our ablation studies confirm that this adaption behavior is key for more accurate 3D understanding.
Read more4/5/2024

0
Enhancing 2D Representation Learning with a 3D Prior
Mehmet Aygun, Prithviraj Dhar, Zhicheng Yan, Oisin Mac Aodha, Rakesh Ranjan
Learning robust and effective representations of visual data is a fundamental task in computer vision. Traditionally, this is achieved by training models with labeled data which can be expensive to obtain. Self-supervised learning attempts to circumvent the requirement for labeled data by learning representations from raw unlabeled visual data alone. However, unlike humans who obtain rich 3D information from their binocular vision and through motion, the majority of current self-supervised methods are tasked with learning from monocular 2D image collections. This is noteworthy as it has been demonstrated that shape-centric visual processing is more robust compared to texture-biased automated methods. Inspired by this, we propose a new approach for strengthening existing self-supervised methods by explicitly enforcing a strong 3D structural prior directly into the model during training. Through experiments, across a range of datasets, we demonstrate that our 3D aware representations are more robust compared to conventional self-supervised baselines.
Read more6/5/2024