Probing the 3D Awareness of Visual Foundation Models
2404.08636
0
0

Abstract
Recent advances in large-scale pretraining have yielded visual foundation models with strong capabilities. Not only can recent models generalize to arbitrary images for their training task, their intermediate representations are useful for other visual tasks such as detection and segmentation. Given that such models can classify, delineate, and localize objects in 2D, we ask whether they also represent their 3D structure? In this work, we analyze the 3D awareness of visual foundation models. We posit that 3D awareness implies that representations (1) encode the 3D structure of the scene and (2) consistently represent the surface across views. We conduct a series of experiments using task-specific probes and zero-shot inference procedures on frozen features. Our experiments reveal several limitations of the current models. Our code and analysis can be found at https://github.com/mbanani/probe3d.
Create account to get full access
Overview
- This paper investigates the 3D awareness of visual foundation models, which are powerful AI systems trained on vast amounts of visual data to perform a variety of tasks.
- The authors probe the 3D understanding of these models using a suite of 3D-aware visual tasks, including depth estimation, 3D object detection, and 3D semantic segmentation.
- The goal is to understand the extent to which these foundation models can extract and leverage 3D information from 2D images, and how this 3D awareness can be further enhanced.
Plain English Explanation
Visual foundation models, such as CLIP and SUGAR, have shown remarkable capabilities in a wide range of visual tasks. However, it's not well understood how these models internally represent and reason about the 3D structure of the world.
This paper explores the "3D awareness" of these foundation models - their ability to extract and leverage 3D information from 2D images. The researchers use a set of specialized 3D-aware tasks, like estimating the depth of objects in a scene or detecting 3D objects, to probe the models' understanding of the 3D world.
By analyzing how well the models perform on these 3D-centric tasks, the researchers aim to gain insights into the extent of the models' 3D awareness. This could help guide efforts to further enhance the 3D capabilities of these powerful AI systems, which could be valuable for applications like robotics and seamless adaptation to new visual tasks.
Technical Explanation
The paper examines the 3D awareness of visual foundation models through a suite of 3D-aware visual tasks. These tasks include depth estimation, 3D object detection, and 3D semantic segmentation, which require the models to reason about the 3D structure of the visual world.
The researchers evaluate the performance of several prominent foundation models, such as CLIP and SUGAR, on these 3D-centric tasks. They analyze the models' ability to extract and leverage 3D information from 2D images, as well as how this 3D awareness varies across different architectural designs and pre-training strategies.
The experimental setup involves fine-tuning the foundation models on datasets specifically designed for 3D-aware visual tasks. The authors then measure the models' performance on these 3D-centric benchmarks and compare their results to baselines and state-of-the-art 3D-specific models.
The findings provide insights into the 3D understanding embedded within these powerful visual foundation models. The results suggest that while these models can to some extent capture and utilize 3D information, there is still room for improvement in their 3D awareness. The paper discusses various factors that may influence the models' 3D capabilities, such as architectural choices and pre-training data and objectives.
Critical Analysis
The paper presents a thorough investigation of the 3D awareness of visual foundation models, but it also acknowledges several limitations and areas for further research.
One key limitation is that the evaluation is primarily focused on a limited set of 3D-aware tasks, which may not capture the full breadth of 3D understanding required for real-world applications. Additionally, the benchmarks used in the study, while well-established, may not fully reflect the complexity and diversity of 3D visual perception in the natural world.
Moreover, the paper does not delve into the exact mechanisms by which the foundation models extract and represent 3D information. A more detailed analysis of the internal representations and reasoning processes of these models could provide valuable insights to guide future research and model development.
It would also be interesting to explore how the 3D awareness of these models can be further enhanced, perhaps through targeted fine-tuning, architectural modifications, or novel pre-training strategies. The paper touches on these possibilities, but does not provide a comprehensive exploration of the various approaches that could be pursued.
Conclusion
This paper offers a valuable contribution to the understanding of 3D awareness in visual foundation models. By probing the models' performance on a range of 3D-centric tasks, the researchers have gained insights into the extent to which these powerful AI systems can extract and leverage 3D information from 2D images.
The findings suggest that while the foundation models do exhibit some degree of 3D awareness, there is still significant room for improvement. Enhancing the 3D capabilities of these models could be crucial for a wide range of applications, from robotics and autonomous systems to augmented reality and virtual environments.
The paper provides a solid foundation for future research in this area, highlighting the need for further investigation into the internal representations and reasoning processes of these models, as well as the development of new strategies to boost their 3D awareness. As the field of computer vision continues to advance, a deeper understanding of 3D perception in AI systems will be crucial for unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

ImageNet3D: Towards General-Purpose Object-Level 3D Understanding
Wufei Ma, Guanning Zeng, Guofeng Zhang, Qihao Liu, Letian Zhang, Adam Kortylewski, Yaoyao Liu, Alan Yuille
0
0
A vision model with general-purpose object-level 3D understanding should be capable of inferring both 2D (e.g., class name and bounding box) and 3D information (e.g., 3D location and 3D viewpoint) for arbitrary rigid objects in natural images. This is a challenging task, as it involves inferring 3D information from 2D signals and most importantly, generalizing to rigid objects from unseen categories. However, existing datasets with object-level 3D annotations are often limited by the number of categories or the quality of annotations. Models developed on these datasets become specialists for certain categories or domains, and fail to generalize. In this work, we present ImageNet3D, a large dataset for general-purpose object-level 3D understanding. ImageNet3D augments 200 categories from the ImageNet dataset with 2D bounding box, 3D pose, 3D location annotations, and image captions interleaved with 3D information. With the new annotations available in ImageNet3D, we could (i) analyze the object-level 3D awareness of visual foundation models, and (ii) study and develop general-purpose models that infer both 2D and 3D information for arbitrary rigid objects in natural images, and (iii) integrate unified 3D models with large language models for 3D-related reasoning.. We consider two new tasks, probing of object-level 3D awareness and open vocabulary pose estimation, besides standard classification and pose estimation. Experimental results on ImageNet3D demonstrate the potential of our dataset in building vision models with stronger general-purpose object-level 3D understanding.
6/17/2024

Building a Strong Pre-Training Baseline for Universal 3D Large-Scale Perception
Haoming Chen, Zhizhong Zhang, Yanyun Qu, Ruixin Zhang, Xin Tan, Yuan Xie
0
0
An effective pre-training framework with universal 3D representations is extremely desired in perceiving large-scale dynamic scenes. However, establishing such an ideal framework that is both task-generic and label-efficient poses a challenge in unifying the representation of the same primitive across diverse scenes. The current contrastive 3D pre-training methods typically follow a frame-level consistency, which focuses on the 2D-3D relationships in each detached image. Such inconsiderate consistency greatly hampers the promising path of reaching an universal pre-training framework: (1) The cross-scene semantic self-conflict, i.e., the intense collision between primitive segments of the same semantics from different scenes; (2) Lacking a globally unified bond that pushes the cross-scene semantic consistency into 3D representation learning. To address above challenges, we propose a CSC framework that puts a scene-level semantic consistency in the heart, bridging the connection of the similar semantic segments across various scenes. To achieve this goal, we combine the coherent semantic cues provided by the vision foundation model and the knowledge-rich cross-scene prototypes derived from the complementary multi-modality information. These allow us to train a universal 3D pre-training model that facilitates various downstream tasks with less fine-tuning efforts. Empirically, we achieve consistent improvements over SOTA pre-training approaches in semantic segmentation (+1.4% mIoU), object detection (+1.0% mAP), and panoptic segmentation (+3.0% PQ) using their task-specific 3D network on nuScenes. Code is released at https://github.com/chenhaomingbob/CSC, hoping to inspire future research.
5/14/2024

Enhancing 2D Representation Learning with a 3D Prior
Mehmet Aygun, Prithviraj Dhar, Zhicheng Yan, Oisin Mac Aodha, Rakesh Ranjan
0
0
Learning robust and effective representations of visual data is a fundamental task in computer vision. Traditionally, this is achieved by training models with labeled data which can be expensive to obtain. Self-supervised learning attempts to circumvent the requirement for labeled data by learning representations from raw unlabeled visual data alone. However, unlike humans who obtain rich 3D information from their binocular vision and through motion, the majority of current self-supervised methods are tasked with learning from monocular 2D image collections. This is noteworthy as it has been demonstrated that shape-centric visual processing is more robust compared to texture-biased automated methods. Inspired by this, we propose a new approach for strengthening existing self-supervised methods by explicitly enforcing a strong 3D structural prior directly into the model during training. Through experiments, across a range of datasets, we demonstrate that our 3D aware representations are more robust compared to conventional self-supervised baselines.
6/5/2024
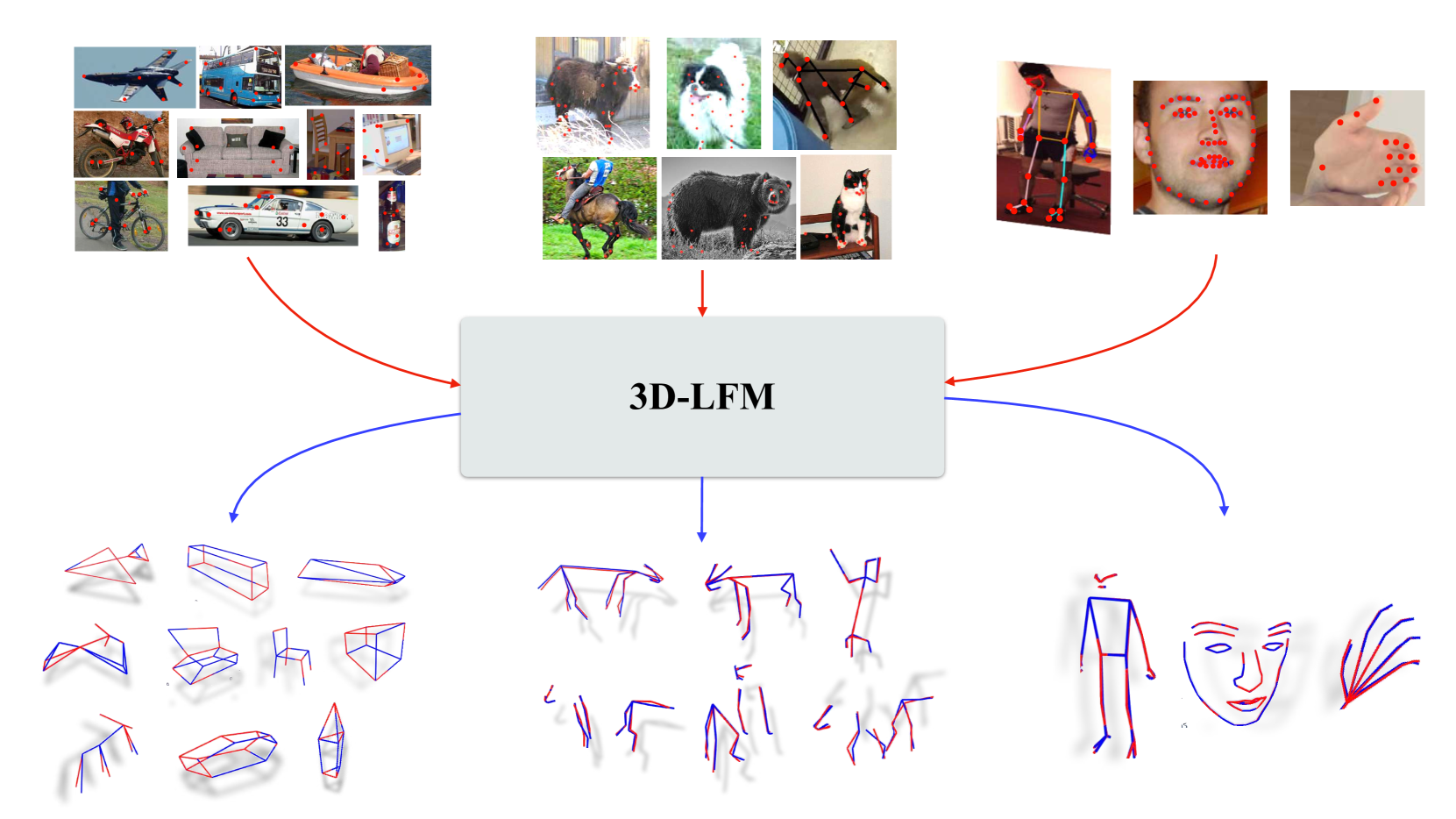
3D-LFM: Lifting Foundation Model
Mosam Dabhi, Laszlo A. Jeni, Simon Lucey
0
0
The lifting of 3D structure and camera from 2D landmarks is at the cornerstone of the entire discipline of computer vision. Traditional methods have been confined to specific rigid objects, such as those in Perspective-n-Point (PnP) problems, but deep learning has expanded our capability to reconstruct a wide range of object classes (e.g. C3DPO and PAUL) with resilience to noise, occlusions, and perspective distortions. All these techniques, however, have been limited by the fundamental need to establish correspondences across the 3D training data -- significantly limiting their utility to applications where one has an abundance of in-correspondence 3D data. Our approach harnesses the inherent permutation equivariance of transformers to manage varying number of points per 3D data instance, withstands occlusions, and generalizes to unseen categories. We demonstrate state of the art performance across 2D-3D lifting task benchmarks. Since our approach can be trained across such a broad class of structures we refer to it simply as a 3D Lifting Foundation Model (3D-LFM) -- the first of its kind.
4/29/2024