Improving 3D Semi-supervised Learning by Effectively Utilizing All Unlabelled Data

0
Sign in to get full access
Overview
- This research paper focuses on improving 3D semi-supervised learning, which aims to leverage both labeled and unlabeled data to enhance the performance of 3D models.
- The key idea is to effectively utilize all unlabeled data, including those that are far from the labeled data distribution, to improve the overall model performance.
- The authors propose a novel semi-supervised learning framework called "AllMatch" that can effectively leverage all unlabeled data points.
Plain English Explanation
In the field of 3D computer vision, researchers often face a challenge where labeled data, such as 3D point clouds with annotated objects, can be scarce and expensive to obtain. To address this, they have turned to semi-supervised learning, which aims to use both the limited labeled data and the more readily available unlabeled data to train better models.
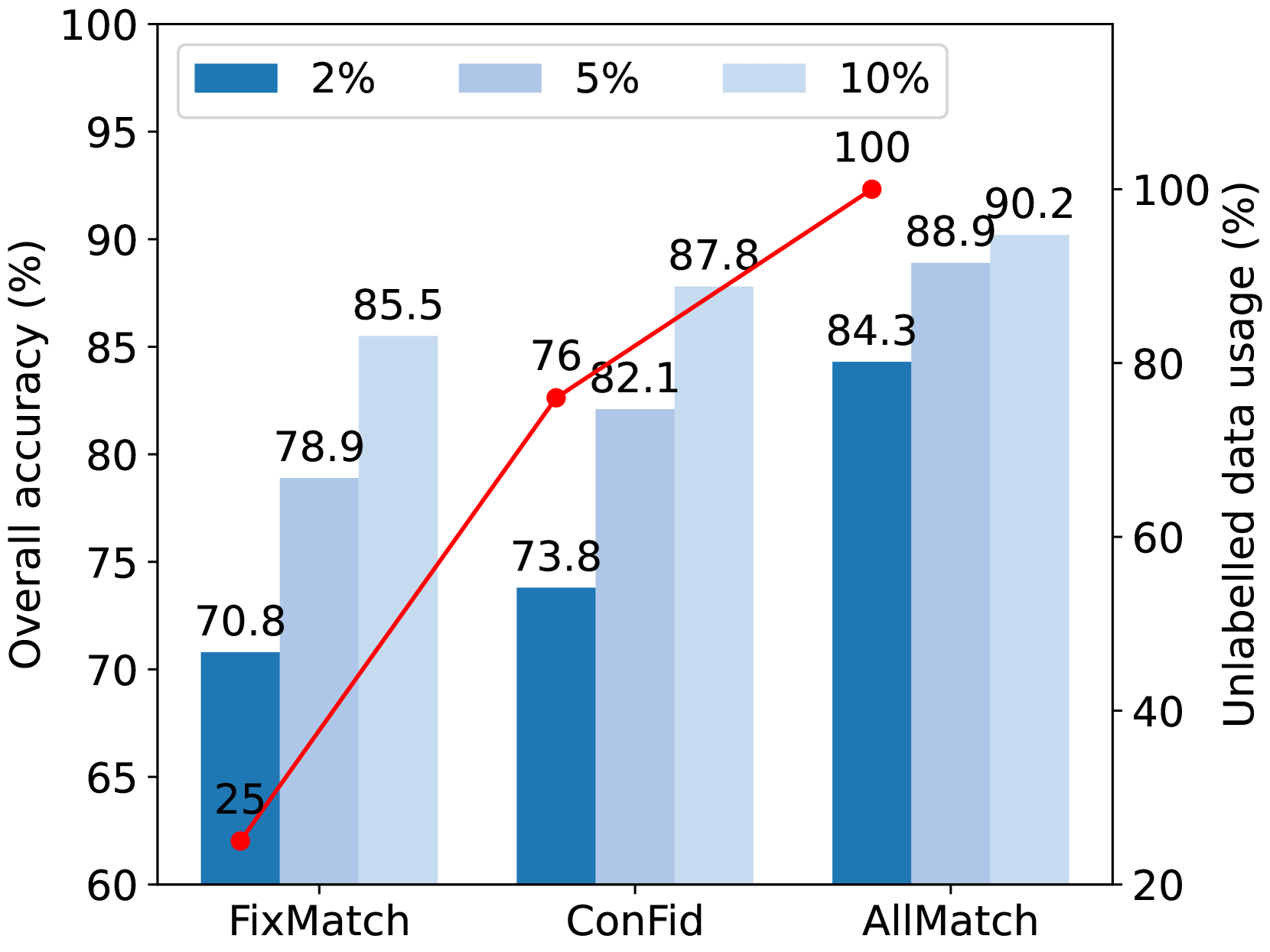
The paper introduces a new semi-supervised learning method called "AllMatch" that can effectively utilize all the unlabeled data, even those that are quite different from the labeled data. The key insight is that even if an unlabeled data point is very different from the labeled data, it can still provide useful information to the model during training.
For example, imagine you're trying to train a 3D model to recognize different types of furniture. You might have a small set of labeled data, such as 3D scans of chairs, tables, and beds. However, you also have a much larger set of unlabeled 3D scans of various objects, including some that are quite different from the labeled furniture, like lamps or vases.
The "AllMatch" method proposed in the paper can effectively leverage all of these unlabeled data points, even the ones that don't look like the labeled furniture, to improve the model's ability to recognize different types of 3D objects. By using this approach, the researchers were able to significantly improve the performance of their 3D semi-supervised learning models compared to previous methods.
Technical Explanation
The paper introduces a novel semi-supervised learning framework called "AllMatch" that can effectively leverage all unlabeled data points, including those that are far from the labeled data distribution, to improve the overall model performance.
The key components of the AllMatch framework are:
-
Feature Representation Learning: The model first learns a robust feature representation from the labeled and unlabeled data using a self-supervised pretraining task, such as contrastive learning or masked point cloud prediction.
-
Uncertainty-Aware Pseudo-Labeling: The model then generates pseudo-labels for the unlabeled data points based on their feature representations, while also estimating the uncertainty of these pseudo-labels. This allows the model to focus on unlabeled data points with higher confidence pseudo-labels during training.
-
Cross-Consistency Regularization: The model enforces cross-consistency between the predictions on the original unlabeled data and their augmented versions, encouraging the model to learn robust and consistent representations.
The authors evaluate the AllMatch framework on several 3D semi-supervised learning benchmarks, including point cloud classification and segmentation tasks. The results show that AllMatch can outperform previous state-of-the-art semi-supervised learning methods by a significant margin, demonstrating the effectiveness of leveraging all unlabeled data, even those that are far from the labeled data distribution.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed AllMatch framework, exploring its performance on various 3D semi-supervised learning tasks and comparing it to several baselines. The authors also discuss potential limitations and future research directions.
One potential limitation is the reliance on effective self-supervised pretraining to learn the initial feature representations. The performance of the AllMatch framework may depend on the quality of these learned representations, and the authors acknowledge that further research is needed to understand the impact of different self-supervised learning methods on the overall performance.
Additionally, while the paper demonstrates the benefits of leveraging all unlabeled data, including those far from the labeled data distribution, it would be interesting to explore the tradeoffs and potential challenges in handling highly diverse or noisy unlabeled data. The authors briefly mention the importance of uncertainty estimation, but a more detailed investigation of this aspect could provide additional insights.
Overall, the paper presents a promising approach to 3D semi-supervised learning and highlights the potential of effectively utilizing all available unlabeled data to improve model performance. The research community may find the AllMatch framework and its underlying principles valuable for further advancements in this area.
Conclusion
This research paper introduces a novel semi-supervised learning framework called "AllMatch" that can effectively leverage all unlabeled data, including those that are far from the labeled data distribution, to improve the performance of 3D models. By combining feature representation learning, uncertainty-aware pseudo-labeling, and cross-consistency regularization, the AllMatch framework demonstrates significant improvements over previous state-of-the-art semi-supervised learning methods on various 3D tasks.
The key contribution of this work is the insight that even unlabeled data points that are quite different from the labeled data can still provide useful information to the model during training. This highlights the importance of developing semi-supervised learning methods that can fully utilize the vast amounts of unlabeled data available in many real-world applications, particularly in the field of 3D computer vision. The findings of this paper can inspire further research and development in this direction, potentially leading to more efficient and robust 3D models that can be trained with limited labeled data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving 3D Semi-supervised Learning by Effectively Utilizing All Unlabelled Data
Sneha Paul, Zachary Patterson, Nizar Bouguila
Semi-supervised learning (SSL) has shown its effectiveness in learning effective 3D representation from a small amount of labelled data while utilizing large unlabelled data. Traditional semi-supervised approaches rely on the fundamental concept of predicting pseudo-labels for unlabelled data and incorporating them into the learning process. However, we identify that the existing methods do not fully utilize all the unlabelled samples and consequently limit their potential performance. To address this issue, we propose AllMatch, a novel SSL-based 3D classification framework that effectively utilizes all the unlabelled samples. AllMatch comprises three modules: (1) an adaptive hard augmentation module that applies relatively hard augmentations to the high-confident unlabelled samples with lower loss values, thereby enhancing the contribution of such samples, (2) an inverse learning module that further improves the utilization of unlabelled data by learning what not to learn, and (3) a contrastive learning module that ensures learning from all the samples in both supervised and unsupervised settings. Comprehensive experiments on two popular 3D datasets demonstrate a performance improvement of up to 11.2% with 1% labelled data, surpassing the SOTA by a significant margin. Furthermore, AllMatch exhibits its efficiency in effectively leveraging all the unlabelled data, demonstrated by the fact that only 10% of labelled data reaches nearly the same performance as fully-supervised learning with all labelled data. The code of our work is available at: https://github.com/snehaputul/AllMatch.
Read more9/24/2024
0
AllMatch: Exploiting All Unlabeled Data for Semi-Supervised Learning
Zhiyu Wu, Jinshi Cui
Existing semi-supervised learning algorithms adopt pseudo-labeling and consistency regulation techniques to introduce supervision signals for unlabeled samples. To overcome the inherent limitation of threshold-based pseudo-labeling, prior studies have attempted to align the confidence threshold with the evolving learning status of the model, which is estimated through the predictions made on the unlabeled data. In this paper, we further reveal that classifier weights can reflect the differentiated learning status across categories and consequently propose a class-specific adaptive threshold mechanism. Additionally, considering that even the optimal threshold scheme cannot resolve the problem of discarding unlabeled samples, a binary classification consistency regulation approach is designed to distinguish candidate classes from negative options for all unlabeled samples. By combining the above strategies, we present a novel SSL algorithm named AllMatch, which achieves improved pseudo-label accuracy and a 100% utilization ratio for the unlabeled data. We extensively evaluate our approach on multiple benchmarks, encompassing both balanced and imbalanced settings. The results demonstrate that AllMatch consistently outperforms existing state-of-the-art methods.
Read more7/10/2024

0
From Obstacle to Opportunity: Enhancing Semi-supervised Learning with Synthetic Data
Zerun Wang, Jiafeng Mao, Liuyu Xiang, Toshihiko Yamasaki
Semi-supervised learning (SSL) can utilize unlabeled data to enhance model performance. In recent years, with increasingly powerful generative models becoming available, a large number of synthetic images have been uploaded to public image sets. Therefore, when collecting unlabeled data from these sources, the inclusion of synthetic images is inevitable. This prompts us to consider the impact of unlabeled data mixed with real and synthetic images on SSL. In this paper, we set up a new task, Real and Synthetic hybrid SSL (RS-SSL), to investigate this problem. We discover that current SSL methods are unable to fully utilize synthetic data and are sometimes negatively affected. Then, by analyzing the issues caused by synthetic images, we propose a new SSL method, RSMatch, to tackle the RS-SSL problem. Extensive experimental results show that RSMatch can better utilize the synthetic data in unlabeled images to improve the SSL performance. The effectiveness is further verified through ablation studies and visualization.
Read more5/28/2024

0
Leveraging Task-Specific Knowledge from LLM for Semi-Supervised 3D Medical Image Segmentation
Suruchi Kumari, Aryan Das, Swalpa Kumar Roy, Indu Joshi, Pravendra Singh
Traditional supervised 3D medical image segmentation models need voxel-level annotations, which require huge human effort, time, and cost. Semi-supervised learning (SSL) addresses this limitation of supervised learning by facilitating learning with a limited annotated and larger amount of unannotated training samples. However, state-of-the-art SSL models still struggle to fully exploit the potential of learning from unannotated samples. To facilitate effective learning from unannotated data, we introduce LLM-SegNet, which exploits a large language model (LLM) to integrate task-specific knowledge into our co-training framework. This knowledge aids the model in comprehensively understanding the features of the region of interest (ROI), ultimately leading to more efficient segmentation. Additionally, to further reduce erroneous segmentation, we propose a Unified Segmentation loss function. This loss function reduces erroneous segmentation by not only prioritizing regions where the model is confident in predicting between foreground or background pixels but also effectively addressing areas where the model lacks high confidence in predictions. Experiments on publicly available Left Atrium, Pancreas-CT, and Brats-19 datasets demonstrate the superior performance of LLM-SegNet compared to the state-of-the-art. Furthermore, we conducted several ablation studies to demonstrate the effectiveness of various modules and loss functions leveraged by LLM-SegNet.
Read more7/9/2024