AllMatch: Exploiting All Unlabeled Data for Semi-Supervised Learning

0
Sign in to get full access
Overview
- This paper introduces a novel semi-supervised learning technique called "AllMatch" that leverages all unlabeled data to improve model performance.
- The key idea is to generate pseudo-labels for all unlabeled data, not just a subset, and use them to train the model.
- The authors show that this approach outperforms existing semi-supervised learning methods on a variety of benchmarks.
Plain English Explanation
Semi-supervised learning is a machine learning technique that uses both labeled and unlabeled data to train models. The LayerMatch and MaskMatch papers have explored different ways to leverage unlabeled data, while the Self-Training Survey provides a comprehensive overview of self-training methods.
The core insight of the "AllMatch" approach is that we should use all of the unlabeled data, not just a subset, to generate pseudo-labels and train the model. The authors argue that this allows the model to learn more effectively from the unlabeled examples. By Enhancing Semi-Supervised Learning, the model can achieve better performance on the overall task.
The authors demonstrate that AllMatch outperforms other semi-supervised learning techniques on several benchmark datasets. This suggests that leveraging all unlabeled data, rather than just a subset, can be a powerful way to improve model performance in real-world applications.
Technical Explanation
The key contribution of the AllMatch paper is a novel semi-supervised learning algorithm that generates pseudo-labels for all unlabeled data, not just a subset, and uses them to train the model.
The authors first train a base model on the labeled data. They then use this model to generate pseudo-labels for all of the unlabeled data, effectively treating the unlabeled data as additional labeled examples. The model is then retrained on the combined labeled and pseudo-labeled data.
The authors show that this approach, which they call "AllMatch", outperforms existing semi-supervised learning methods like Smooth Pseudo-Labeling on a variety of benchmark tasks. They attribute this to the model's ability to learn more effectively from the larger set of pseudo-labeled examples.
The authors conduct extensive experiments to validate their approach, including ablation studies to understand the impact of different components of the algorithm. They also provide theoretical analysis to explain the benefits of their method.
Critical Analysis
The AllMatch paper presents a compelling approach to semi-supervised learning, but there are a few potential limitations and areas for further research:
-
The authors focus on image classification tasks, and it's unclear how well the method would generalize to other domains like natural language processing or time series data.
-
The paper does not address the potential issue of noisy or inaccurate pseudo-labels, which can be a problem in semi-supervised learning. Techniques like MaskMatch have explored ways to mitigate this.
-
The computational complexity of generating pseudo-labels for all unlabeled data may be a practical concern, especially for large-scale datasets. The authors do not provide detailed analysis of the training time or resource requirements.
-
While the authors demonstrate state-of-the-art performance on the benchmarks, it would be valuable to see how the method performs in real-world applications with more diverse and challenging data.
Overall, the AllMatch paper makes a significant contribution to the field of semi-supervised learning, but further research and validation is needed to fully understand the method's strengths, weaknesses, and practical applicability.
Conclusion
The AllMatch paper presents a novel semi-supervised learning technique that generates pseudo-labels for all unlabeled data and uses them to train the model. The authors show that this approach outperforms existing methods on several benchmark tasks, suggesting that leveraging all available unlabeled data can be a powerful way to improve model performance.
While the paper makes an important contribution to the field, there are still some open questions and limitations that warrant further investigation. Nonetheless, the insights and techniques developed in this work could have significant implications for a wide range of real-world applications that rely on semi-supervised learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
AllMatch: Exploiting All Unlabeled Data for Semi-Supervised Learning
Zhiyu Wu, Jinshi Cui
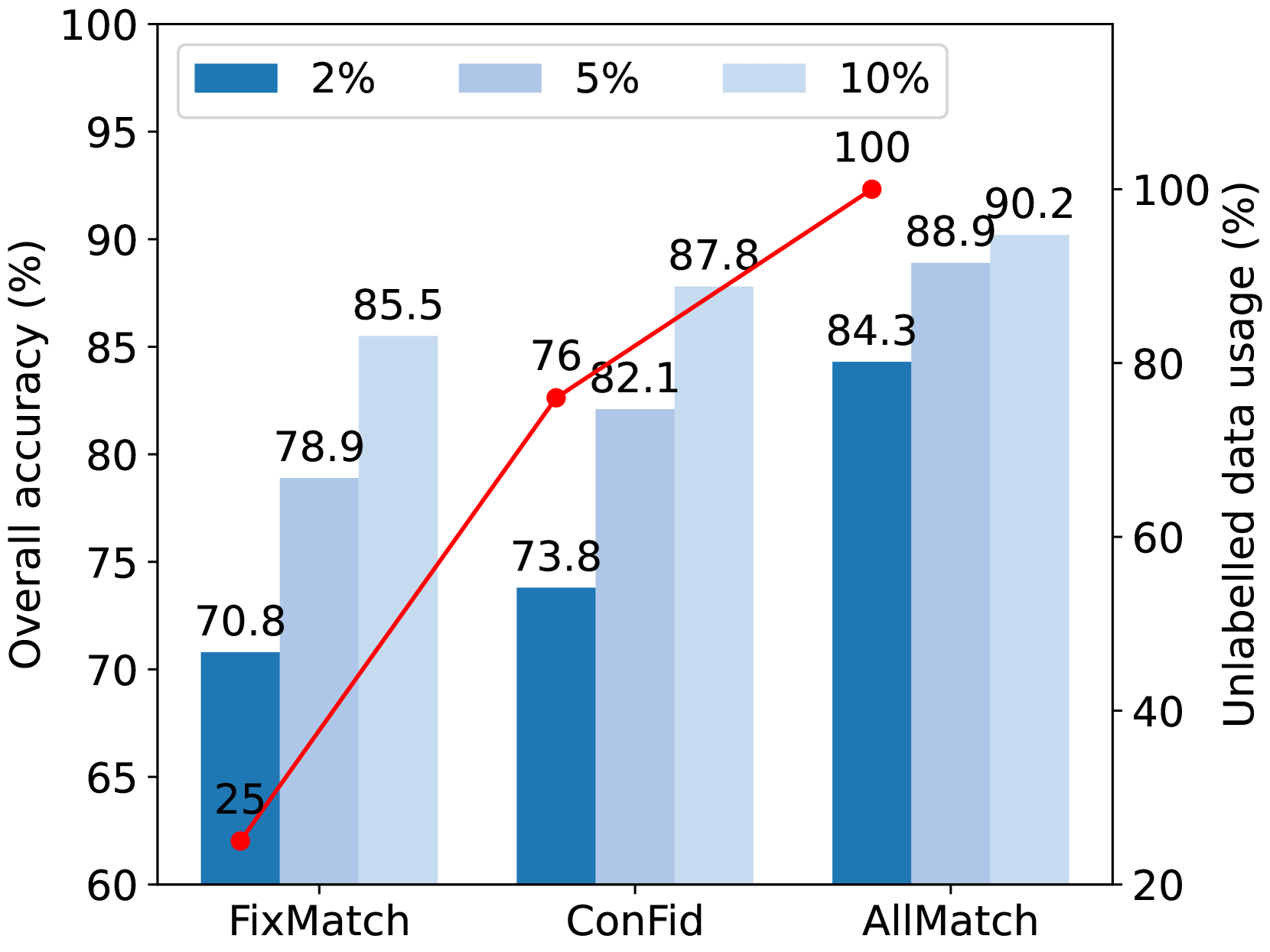
Existing semi-supervised learning algorithms adopt pseudo-labeling and consistency regulation techniques to introduce supervision signals for unlabeled samples. To overcome the inherent limitation of threshold-based pseudo-labeling, prior studies have attempted to align the confidence threshold with the evolving learning status of the model, which is estimated through the predictions made on the unlabeled data. In this paper, we further reveal that classifier weights can reflect the differentiated learning status across categories and consequently propose a class-specific adaptive threshold mechanism. Additionally, considering that even the optimal threshold scheme cannot resolve the problem of discarding unlabeled samples, a binary classification consistency regulation approach is designed to distinguish candidate classes from negative options for all unlabeled samples. By combining the above strategies, we present a novel SSL algorithm named AllMatch, which achieves improved pseudo-label accuracy and a 100% utilization ratio for the unlabeled data. We extensively evaluate our approach on multiple benchmarks, encompassing both balanced and imbalanced settings. The results demonstrate that AllMatch consistently outperforms existing state-of-the-art methods.
Read more7/10/2024
0
Improving 3D Semi-supervised Learning by Effectively Utilizing All Unlabelled Data
Sneha Paul, Zachary Patterson, Nizar Bouguila
Semi-supervised learning (SSL) has shown its effectiveness in learning effective 3D representation from a small amount of labelled data while utilizing large unlabelled data. Traditional semi-supervised approaches rely on the fundamental concept of predicting pseudo-labels for unlabelled data and incorporating them into the learning process. However, we identify that the existing methods do not fully utilize all the unlabelled samples and consequently limit their potential performance. To address this issue, we propose AllMatch, a novel SSL-based 3D classification framework that effectively utilizes all the unlabelled samples. AllMatch comprises three modules: (1) an adaptive hard augmentation module that applies relatively hard augmentations to the high-confident unlabelled samples with lower loss values, thereby enhancing the contribution of such samples, (2) an inverse learning module that further improves the utilization of unlabelled data by learning what not to learn, and (3) a contrastive learning module that ensures learning from all the samples in both supervised and unsupervised settings. Comprehensive experiments on two popular 3D datasets demonstrate a performance improvement of up to 11.2% with 1% labelled data, surpassing the SOTA by a significant margin. Furthermore, AllMatch exhibits its efficiency in effectively leveraging all the unlabelled data, demonstrated by the fact that only 10% of labelled data reaches nearly the same performance as fully-supervised learning with all labelled data. The code of our work is available at: https://github.com/snehaputul/AllMatch.
Read more9/24/2024

0
Self Adaptive Threshold Pseudo-labeling and Unreliable Sample Contrastive Loss for Semi-supervised Image Classification
Xuerong Zhang, Li Huang, Jing Lv, Ming Yang
Semi-supervised learning is attracting blooming attention, due to its success in combining unlabeled data. However, pseudo-labeling-based semi-supervised approaches suffer from two problems in image classification: (1) Existing methods might fail to adopt suitable thresholds since they either use a pre-defined/fixed threshold or an ad-hoc threshold adjusting scheme, resulting in inferior performance and slow convergence. (2) Discarding unlabeled data with confidence below the thresholds results in the loss of discriminating information. To solve these issues, we develop an effective method to make sufficient use of unlabeled data. Specifically, we design a self adaptive threshold pseudo-labeling strategy, which thresholds for each class can be dynamically adjusted to increase the number of reliable samples. Meanwhile, in order to effectively utilise unlabeled data with confidence below the thresholds, we propose an unreliable sample contrastive loss to mine the discriminative information in low-confidence samples by learning the similarities and differences between sample features. We evaluate our method on several classification benchmarks under partially labeled settings and demonstrate its superiority over the other approaches.
Read more7/8/2024

0
LayerMatch: Do Pseudo-labels Benefit All Layers?
Chaoqi Liang, Guanglei Yang, Lifeng Qiao, Zitong Huang, Hongliang Yan, Yunchao Wei, Wangmeng Zuo
Deep neural networks have achieved remarkable performance across various tasks when supplied with large-scale labeled data. However, the collection of labeled data can be time-consuming and labor-intensive. Semi-supervised learning (SSL), particularly through pseudo-labeling algorithms that iteratively assign pseudo-labels for self-training, offers a promising solution to mitigate the dependency of labeled data. Previous research generally applies a uniform pseudo-labeling strategy across all model layers, assuming that pseudo-labels exert uniform influence throughout. Contrasting this, our theoretical analysis and empirical experiment demonstrate feature extraction layer and linear classification layer have distinct learning behaviors in response to pseudo-labels. Based on these insights, we develop two layer-specific pseudo-label strategies, termed Grad-ReLU and Avg-Clustering. Grad-ReLU mitigates the impact of noisy pseudo-labels by removing the gradient detrimental effects of pseudo-labels in the linear classification layer. Avg-Clustering accelerates the convergence of feature extraction layer towards stable clustering centers by integrating consistent outputs. Our approach, LayerMatch, which integrates these two strategies, can avoid the severe interference of noisy pseudo-labels in the linear classification layer while accelerating the clustering capability of the feature extraction layer. Through extensive experimentation, our approach consistently demonstrates exceptional performance on standard semi-supervised learning benchmarks, achieving a significant improvement of 10.38% over baseline method and a 2.44% increase compared to state-of-the-art methods.
Read more6/28/2024