Improving the Accuracy-Robustness Trade-Off of Classifiers via Adaptive Smoothing
2301.12554
0
0
🖼️
Abstract
While prior research has proposed a plethora of methods that build neural classifiers robust against adversarial robustness, practitioners are still reluctant to adopt them due to their unacceptably severe clean accuracy penalties. This paper significantly alleviates this accuracy-robustness trade-off by mixing the output probabilities of a standard classifier and a robust classifier, where the standard network is optimized for clean accuracy and is not robust in general. We show that the robust base classifier's confidence difference for correct and incorrect examples is the key to this improvement. In addition to providing intuitions and empirical evidence, we theoretically certify the robustness of the mixed classifier under realistic assumptions. Furthermore, we adapt an adversarial input detector into a mixing network that adaptively adjusts the mixture of the two base models, further reducing the accuracy penalty of achieving robustness. The proposed flexible method, termed adaptive smoothing, can work in conjunction with existing or even future methods that improve clean accuracy, robustness, or adversary detection. Our empirical evaluation considers strong attack methods, including AutoAttack and adaptive attack. On the CIFAR-100 dataset, our method achieves an 85.21% clean accuracy while maintaining a 38.72% $ell_infty$-AutoAttacked ($epsilon = 8/255$) accuracy, becoming the second most robust method on the RobustBench CIFAR-100 benchmark as of submission, while improving the clean accuracy by ten percentage points compared with all listed models. The code that implements our method is available at https://github.com/Bai-YT/AdaptiveSmoothing.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposed a method to significantly improve the trade-off between clean accuracy and adversarial robustness in neural classifiers
- Mixing output probabilities of a standard (high clean accuracy) and robust classifier, leveraging the robust classifier's confidence difference for correct and incorrect examples
- Theoretically certified the robustness of the mixed classifier under realistic assumptions
- Adapted an adversarial input detector to create a mixing network that adjusts the mixture adaptively, further reducing the accuracy penalty
- Empirically evaluated on CIFAR-100, achieving high clean accuracy while maintaining strong robustness against strong attacks like AutoAttack
Plain English Explanation
Neural networks, the powerful AI models behind many of today's intelligent systems, can be easily fooled by carefully crafted "adversarial" inputs that look normal to humans but cause the model to make mistakes. Researchers have proposed various methods to make these models more robust against such attacks, but in the process, the models often suffer significant drops in their regular, "clean" accuracy - the accuracy on normal, non-adversarial inputs.
This paper presents a clever approach to significantly alleviate this accuracy-robustness trade-off. The key idea is to combine the output of two neural networks: one optimized for clean accuracy (but not robust) and one optimized for robustness (but with lower clean accuracy). By carefully mixing the outputs of these two models, the researchers were able to achieve high clean accuracy while maintaining strong robustness.
The method works because the robust model is particularly confident in its correct predictions but much less confident in its incorrect predictions. By leveraging this property, the researchers can selectively trust the robust model's outputs when it is highly confident, while relying more on the standard model's outputs in other cases.
The researchers also adapt an adversarial input detector to create a "mixing network" that can dynamically adjust the mixture of the two models based on the input, further reducing the accuracy penalty.
Technical Explanation
The paper proposes a method called "Adaptive Smoothing" to address the accuracy-robustness trade-off in neural classifiers. The key idea is to mix the output probabilities of a standard classifier (optimized for clean accuracy) and a robust classifier (optimized for adversarial robustness).
The researchers first show that the robust classifier's confidence difference for correct and incorrect examples is the key to this improvement. Specifically, the robust classifier is highly confident in its correct predictions but much less confident in its incorrect predictions. By leveraging this property, the method can selectively trust the robust model's outputs when it is highly confident, while relying more on the standard model's outputs in other cases.
The paper then theoretically certifies the robustness of the mixed classifier under realistic assumptions. Furthermore, the researchers adapt an adversarial input detector to create a "mixing network" that can dynamically adjust the mixture of the two models based on the input, further reducing the accuracy penalty.
The empirical evaluation on the CIFAR-100 dataset shows that the proposed method can achieve an 85.21% clean accuracy while maintaining a 38.72% $ell_infty$-AutoAttacked ($epsilon = 8/255$) accuracy, becoming the second most robust method on the RobustBench CIFAR-100 benchmark as of submission, while improving the clean accuracy by ten percentage points compared with all listed models.
Critical Analysis
The paper addresses an important and practical challenge in the field of adversarial robustness - the trade-off between clean accuracy and robustness. The proposed Adaptive Smoothing method is a clever and effective approach that leverages the strengths of both a standard and a robust classifier.
One potential limitation is that the method relies on the availability of a robust classifier, which may not always be easy to obtain. The researchers acknowledge this and suggest that their approach can work in conjunction with existing or even future methods that improve clean accuracy, robustness, or adversary detection.
Additionally, the theoretical certification of robustness is based on certain assumptions, and it would be valuable to explore the sensitivity of the method to violations of these assumptions. Further research could also investigate the performance of Adaptive Smoothing on a wider range of datasets and attack scenarios.
Conclusion
This paper presents a significant advancement in addressing the accuracy-robustness trade-off in neural classifiers. By mixing the outputs of a standard and a robust classifier, leveraging the robust classifier's confidence difference, and adaptively adjusting the mixture, the researchers were able to achieve high clean accuracy while maintaining strong robustness against powerful adversarial attacks.
The Adaptive Smoothing method has the potential to be widely adopted, as it can be used in conjunction with existing and future techniques for improving clean accuracy and robustness. This represents an important step forward in making neural networks more reliable and trustworthy in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
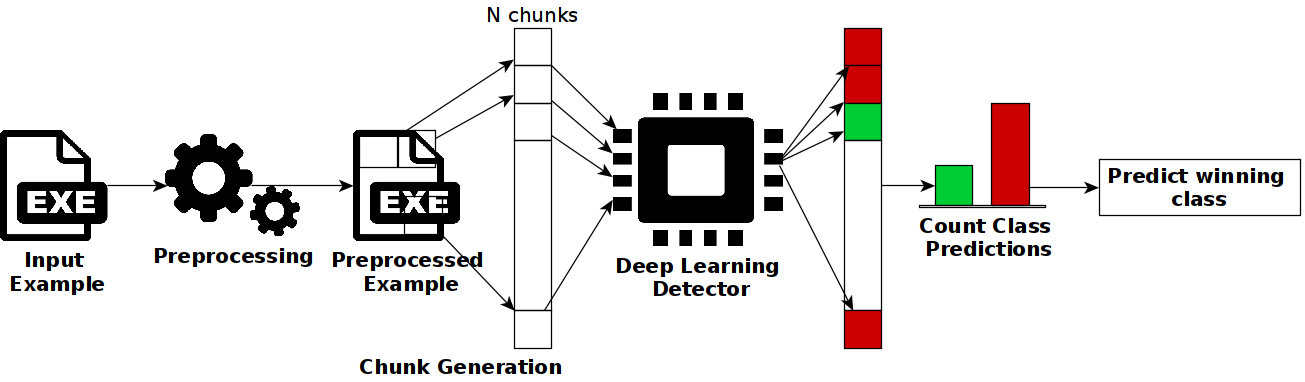
Certified Adversarial Robustness of Machine Learning-based Malware Detectors via (De)Randomized Smoothing
Daniel Gibert, Luca Demetrio, Giulio Zizzo, Quan Le, Jordi Planes, Battista Biggio
0
0
Deep learning-based malware detection systems are vulnerable to adversarial EXEmples - carefully-crafted malicious programs that evade detection with minimal perturbation. As such, the community is dedicating effort to develop mechanisms to defend against adversarial EXEmples. However, current randomized smoothing-based defenses are still vulnerable to attacks that inject blocks of adversarial content. In this paper, we introduce a certifiable defense against patch attacks that guarantees, for a given executable and an adversarial patch size, no adversarial EXEmple exist. Our method is inspired by (de)randomized smoothing which provides deterministic robustness certificates. During training, a base classifier is trained using subsets of continguous bytes. At inference time, our defense splits the executable into non-overlapping chunks, classifies each chunk independently, and computes the final prediction through majority voting to minimize the influence of injected content. Furthermore, we introduce a preprocessing step that fixes the size of the sections and headers to a multiple of the chunk size. As a consequence, the injected content is confined to an integer number of chunks without tampering the other chunks containing the real bytes of the input examples, allowing us to extend our certified robustness guarantees to content insertion attacks. We perform an extensive ablation study, by comparing our defense with randomized smoothing-based defenses against a plethora of content manipulation attacks and neural network architectures. Results show that our method exhibits unmatched robustness against strong content-insertion attacks, outperforming randomized smoothing-based defenses in the literature.
5/2/2024
🔍
MixedNUTS: Training-Free Accuracy-Robustness Balance via Nonlinearly Mixed Classifiers
Yatong Bai, Mo Zhou, Vishal M. Patel, Somayeh Sojoudi
0
0
Adversarial robustness often comes at the cost of degraded accuracy, impeding the real-life application of robust classification models. Training-based solutions for better trade-offs are limited by incompatibilities with already-trained high-performance large models, necessitating the exploration of training-free ensemble approaches. Observing that robust models are more confident in correct predictions than in incorrect ones on clean and adversarial data alike, we speculate amplifying this benign confidence property can reconcile accuracy and robustness in an ensemble setting. To achieve so, we propose MixedNUTS, a training-free method where the output logits of a robust classifier and a standard non-robust classifier are processed by nonlinear transformations with only three parameters, which are optimized through an efficient algorithm. MixedNUTS then converts the transformed logits into probabilities and mixes them as the overall output. On CIFAR-10, CIFAR-100, and ImageNet datasets, experimental results with custom strong adaptive attacks demonstrate MixedNUTS's vastly improved accuracy and near-SOTA robustness -- it boosts CIFAR-100 clean accuracy by 7.86 points, sacrificing merely 0.87 points in robust accuracy.
4/16/2024
❗
Incremental Randomized Smoothing Certification
Shubham Ugare, Tarun Suresh, Debangshu Banerjee, Gagandeep Singh, Sasa Misailovic
0
0
Randomized smoothing-based certification is an effective approach for obtaining robustness certificates of deep neural networks (DNNs) against adversarial attacks. This method constructs a smoothed DNN model and certifies its robustness through statistical sampling, but it is computationally expensive, especially when certifying with a large number of samples. Furthermore, when the smoothed model is modified (e.g., quantized or pruned), certification guarantees may not hold for the modified DNN, and recertifying from scratch can be prohibitively expensive. We present the first approach for incremental robustness certification for randomized smoothing, IRS. We show how to reuse the certification guarantees for the original smoothed model to certify an approximated model with very few samples. IRS significantly reduces the computational cost of certifying modified DNNs while maintaining strong robustness guarantees. We experimentally demonstrate the effectiveness of our approach, showing up to 3x certification speedup over the certification that applies randomized smoothing of the approximate model from scratch.
4/12/2024

Certified PEFTSmoothing: Parameter-Efficient Fine-Tuning with Randomized Smoothing
Chengyan Fu, Wenjie Wang
0
0
Randomized smoothing is the primary certified robustness method for accessing the robustness of deep learning models to adversarial perturbations in the l2-norm, by adding isotropic Gaussian noise to the input image and returning the majority votes over the base classifier. Theoretically, it provides a certified norm bound, ensuring predictions of adversarial examples are stable within this bound. A notable constraint limiting widespread adoption is the necessity to retrain base models entirely from scratch to attain a robust version. This is because the base model fails to learn the noise-augmented data distribution to give an accurate vote. One intuitive way to overcome this challenge is to involve a custom-trained denoiser to eliminate the noise. However, this approach is inefficient and sub-optimal. Inspired by recent large model training procedures, we explore an alternative way named PEFTSmoothing to adapt the base model to learn the Gaussian noise-augmented data with Parameter-Efficient Fine-Tuning (PEFT) methods in both white-box and black-box settings. Extensive results demonstrate the effectiveness and efficiency of PEFTSmoothing, which allow us to certify over 98% accuracy for ViT on CIFAR-10, 20% higher than SoTA denoised smoothing, and over 61% accuracy on ImageNet which is 30% higher than CNN-based denoiser and comparable to the Diffusion-based denoiser.
4/9/2024