Reliable Feature Selection for Adversarially Robust Cyber-Attack Detection
2404.04188
0
0
✨
Abstract
The growing cybersecurity threats make it essential to use high-quality data to train Machine Learning (ML) models for network traffic analysis, without noisy or missing data. By selecting the most relevant features for cyber-attack detection, it is possible to improve both the robustness and computational efficiency of the models used in a cybersecurity system. This work presents a feature selection and consensus process that combines multiple methods and applies them to several network datasets. Two different feature sets were selected and were used to train multiple ML models with regular and adversarial training. Finally, an adversarial evasion robustness benchmark was performed to analyze the reliability of the different feature sets and their impact on the susceptibility of the models to adversarial examples. By using an improved dataset with more data diversity, selecting the best time-related features and a more specific feature set, and performing adversarial training, the ML models were able to achieve a better adversarially robust generalization. The robustness of the models was significantly improved without their generalization to regular traffic flows being affected, without increases of false alarms, and without requiring too many computational resources, which enables a reliable detection of suspicious activity and perturbed traffic flows in enterprise computer networks.
Create account to get full access
Overview
- The paper focuses on using high-quality data to train machine learning (ML) models for network traffic analysis, to improve the robustness and computational efficiency of cybersecurity systems.
- It presents a feature selection and consensus process that combines multiple methods and applies them to several network datasets.
- The goal is to select the most relevant features for cyber-attack detection, and to use those features to train ML models that are both robust and efficient.
Plain English Explanation
The paper is about using machine learning to analyze network traffic and detect cyber attacks. The researchers wanted to make sure the machine learning models were using the most relevant and reliable data, without any noise or missing information. This is important because cybersecurity threats are constantly growing, and having high-quality data is essential for training effective machine learning models.
To do this, the researchers used a process to select the most important features (or characteristics) of the network traffic data. They combined multiple feature selection methods and tested them on several different network datasets. This helped them identify the best set of features to use for detecting cyber attacks.
They then used these selected features to train multiple machine learning models, including models that were trained to be more robust against adversarial attacks - attacks where the data is intentionally modified to trick the model. By using an improved dataset, selecting the best time-related features, and performing adversarial training, the researchers were able to create machine learning models that were better at detecting suspicious activity and perturbed traffic flows in computer networks, without increasing false alarms or requiring too many computational resources.
Technical Explanation
The paper presents a feature selection and consensus process that combines multiple methods, including correlation-based selection, recursive feature elimination, and permutation-based feature importance. These methods are applied to several network traffic datasets, including the UNSW-NB15, CICIDS2017, and NSL-KDD datasets.
The researchers then used the selected feature sets to train multiple machine learning models, including decision trees, random forests, and multi-layer perceptrons. They trained some of the models using regular training, and others using adversarial training, which helps make the models more robust to adversarial attacks.
Finally, the researchers performed an adversarial evasion robustness benchmark to analyze the reliability of the different feature sets and their impact on the susceptibility of the models to adversarial examples. The results show that by using an improved dataset, selecting the best time-related features, and performing adversarial training, the machine learning models were able to achieve better adversarial robustness without compromising their performance on regular traffic flows.
Critical Analysis
The paper presents a thorough and well-designed approach to feature selection and model training for network traffic analysis. The researchers' use of multiple feature selection methods and their testing on several different datasets helps to ensure the robustness and generalizability of their findings.
However, the paper does not address the potential limitations of the machine learning models in terms of their ability to generalize to new, unseen types of cyber attacks. Additionally, the paper does not discuss the computational overhead or the real-world deployment challenges associated with implementing such a system in a production environment.
Further research could explore the performance of the proposed approach on larger and more diverse network traffic datasets, as well as its ability to adapt to emerging cyber threats over time. Additionally, a more in-depth analysis of the feature importance and the model interpretability could provide valuable insights into the underlying patterns and characteristics of network traffic that are indicative of cyber attacks.
Conclusion
This research demonstrates the importance of using high-quality data and feature engineering in the development of robust and efficient machine learning models for cybersecurity applications. By combining multiple feature selection methods and applying adversarial training, the researchers were able to create machine learning models that were better at detecting suspicious activity and perturbed traffic flows, without increasing false alarms or requiring excessive computational resources. This work contributes to the ongoing efforts to improve the reliability and effectiveness of machine learning-based cybersecurity systems in the face of growing threats.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌐
Efficient Network Traffic Feature Sets for IoT Intrusion Detection
Miguel Silva, Jo~ao Vitorino, Eva Maia, Isabel Prac{c}a
0
0
The use of Machine Learning (ML) models in cybersecurity solutions requires high-quality data that is stripped of redundant, missing, and noisy information. By selecting the most relevant features, data integrity and model efficiency can be significantly improved. This work evaluates the feature sets provided by a combination of different feature selection methods, namely Information Gain, Chi-Squared Test, Recursive Feature Elimination, Mean Absolute Deviation, and Dispersion Ratio, in multiple IoT network datasets. The influence of the smaller feature sets on both the classification performance and the training time of ML models is compared, with the aim of increasing the computational efficiency of IoT intrusion detection. Overall, the most impactful features of each dataset were identified, and the ML models obtained higher computational efficiency while preserving a good generalization, showing little to no difference between the sets.
6/13/2024
🌐
An Adversarial Approach to Evaluating the Robustness of Event Identification Models
Obai Bahwal, Oliver Kosut, Lalitha Sankar
0
0
Intelligent machine learning approaches are finding active use for event detection and identification that allow real-time situational awareness. Yet, such machine learning algorithms have been shown to be susceptible to adversarial attacks on the incoming telemetry data. This paper considers a physics-based modal decomposition method to extract features for event classification and focuses on interpretable classifiers including logistic regression and gradient boosting to distinguish two types of events: load loss and generation loss. The resulting classifiers are then tested against an adversarial algorithm to evaluate their robustness. The adversarial attack is tested in two settings: the white box setting, wherein the attacker knows exactly the classification model; and the gray box setting, wherein the attacker has access to historical data from the same network as was used to train the classifier, but does not know the classification model. Thorough experiments on the synthetic South Carolina 500-bus system highlight that a relatively simpler model such as logistic regression is more susceptible to adversarial attacks than gradient boosting.
4/23/2024
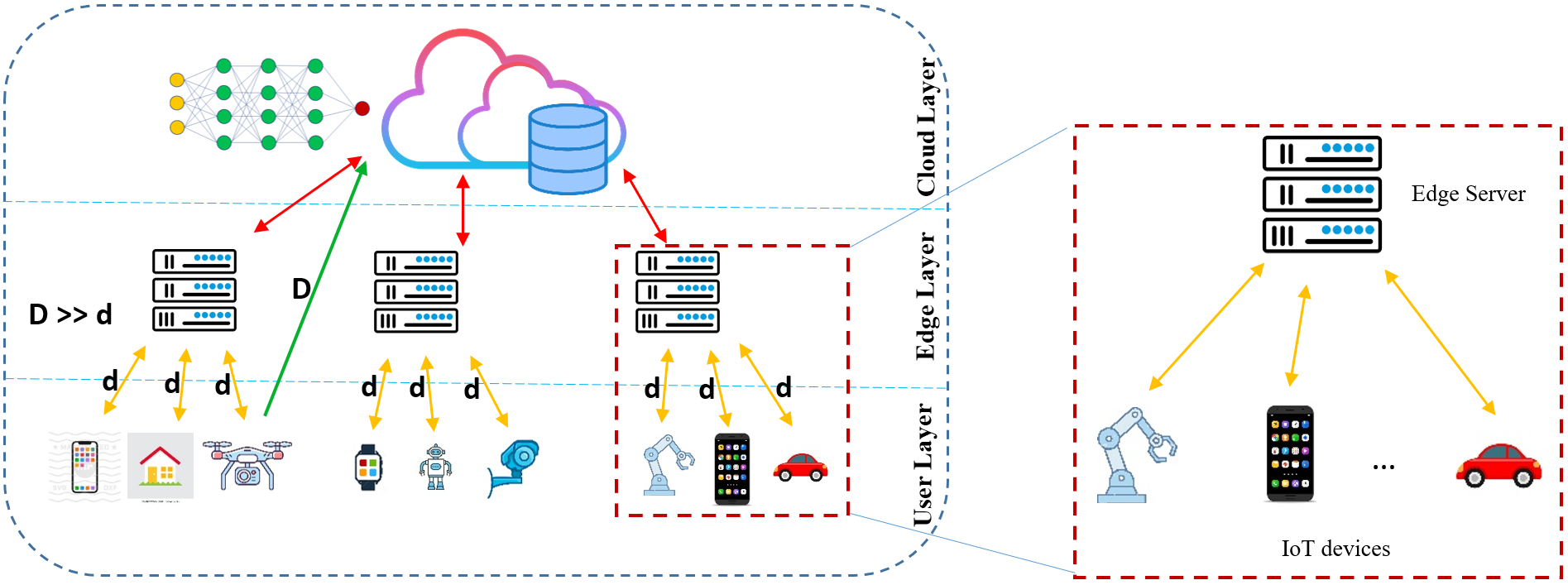
Enhancing IoT Security: A Novel Feature Engineering Approach for ML-Based Intrusion Detection Systems
Afsaneh Mahanipour, Hana Khamfroush
0
0
The integration of Internet of Things (IoT) applications in our daily lives has led to a surge in data traffic, posing significant security challenges. IoT applications using cloud and edge computing are at higher risk of cyberattacks because of the expanded attack surface from distributed edge and cloud services, the vulnerability of IoT devices, and challenges in managing security across interconnected systems leading to oversights. This led to the rise of ML-based solutions for intrusion detection systems (IDSs), which have proven effective in enhancing network security and defending against diverse threats. However, ML-based IDS in IoT systems encounters challenges, particularly from noisy, redundant, and irrelevant features in varied IoT datasets, potentially impacting its performance. Therefore, reducing such features becomes crucial to enhance system performance and minimize computational costs. This paper focuses on improving the effectiveness of ML-based IDS at the edge level by introducing a novel method to find a balanced trade-off between cost and accuracy through the creation of informative features in a two-tier edge-user IoT environment. A hybrid Binary Quantum-inspired Artificial Bee Colony and Genetic Programming algorithm is utilized for this purpose. Three IoT intrusion detection datasets, namely NSL-KDD, UNSW-NB15, and BoT-IoT, are used for the evaluation of the proposed approach.
5/1/2024
✅
Adversarial Examples Are Not Real Features
Ang Li, Yifei Wang, Yiwen Guo, Yisen Wang
0
0
The existence of adversarial examples has been a mystery for years and attracted much interest. A well-known theory by citet{ilyas2019adversarial} explains adversarial vulnerability from a data perspective by showing that one can extract non-robust features from adversarial examples and these features alone are useful for classification. However, the explanation remains quite counter-intuitive since non-robust features are mostly noise features to humans. In this paper, we re-examine the theory from a larger context by incorporating multiple learning paradigms. Notably, we find that contrary to their good usefulness under supervised learning, non-robust features attain poor usefulness when transferred to other self-supervised learning paradigms, such as contrastive learning, masked image modeling, and diffusion models. It reveals that non-robust features are not really as useful as robust or natural features that enjoy good transferability between these paradigms. Meanwhile, for robustness, we also show that naturally trained encoders from robust features are largely non-robust under AutoAttack. Our cross-paradigm examination suggests that the non-robust features are not really useful but more like paradigm-wise shortcuts, and robust features alone might be insufficient to attain reliable model robustness. Code is available at url{https://github.com/PKU-ML/AdvNotRealFeatures}.
5/7/2024