Improving the Adversarial Robustness for Speaker Verification by Self-Supervised Learning
2106.00273
0
0
🐍
Abstract
Previous works have shown that automatic speaker verification (ASV) is seriously vulnerable to malicious spoofing attacks, such as replay, synthetic speech, and recently emerged adversarial attacks. Great efforts have been dedicated to defending ASV against replay and synthetic speech; however, only a few approaches have been explored to deal with adversarial attacks. All the existing approaches to tackle adversarial attacks for ASV require the knowledge for adversarial samples generation, but it is impractical for defenders to know the exact attack algorithms that are applied by the in-the-wild attackers. This work is among the first to perform adversarial defense for ASV without knowing the specific attack algorithms. Inspired by self-supervised learning models (SSLMs) that possess the merits of alleviating the superficial noise in the inputs and reconstructing clean samples from the interrupted ones, this work regards adversarial perturbations as one kind of noise and conducts adversarial defense for ASV by SSLMs. Specifically, we propose to perform adversarial defense from two perspectives: 1) adversarial perturbation purification and 2) adversarial perturbation detection. Experimental results show that our detection module effectively shields the ASV by detecting adversarial samples with an accuracy of around 80%. Moreover, since there is no common metric for evaluating the adversarial defense performance for ASV, this work also formalizes evaluation metrics for adversarial defense considering both purification and detection based approaches into account. We sincerely encourage future works to benchmark their approaches based on the proposed evaluation framework.
Create account to get full access
Overview
- This paper discusses the vulnerability of automatic speaker verification (ASV) systems to malicious spoofing attacks, such as replay, synthetic speech, and adversarial attacks.
- The researchers propose a novel approach to defend ASV systems against adversarial attacks without requiring knowledge of the specific attack algorithms used.
- Their approach involves using self-supervised learning models (SSLMs) to perform adversarial perturbation purification and detection.
Plain English Explanation
Automatic speaker verification (ASV) systems are used to verify a person's identity by their voice. However, these systems have been shown to be vulnerable to different types of attacks, where someone tries to trick the system into thinking they are someone else.
One type of attack is called an "adversarial attack," where the attacker makes small, imperceptible changes to the audio to fool the ASV system. Towards Supervised Performance of Speaker Verification Using Self-Supervised and Certification of Speaker Recognition Models to Additive Perturbations have explored this problem.
The researchers in this paper wanted to find a way to defend ASV systems against these adversarial attacks without needing to know the exact attack algorithms being used. They were inspired by self-supervised learning models (SSLMs), which can remove noise and reconstruct clean samples from corrupted ones.
The researchers proposed two main ways to defend against adversarial attacks:
- Adversarial perturbation purification: Removing the adversarial perturbations from the audio so the ASV system can correctly identify the speaker.
- Adversarial perturbation detection: Detecting when the audio has been maliciously altered so the ASV system can reject it.
Their experiments showed that their detection module was able to accurately identify adversarial samples about 80% of the time. This helps protect the ASV system from being fooled by these attacks.
The researchers also developed a new framework for evaluating adversarial defenses for ASV systems, which they hope will be used by other researchers in the future.
Technical Explanation
The researchers started by acknowledging that while a lot of work has been done to defend ASV systems against replay and synthetic speech attacks, there has been less focus on defending against adversarial attacks. SpeechGuard: Exploring Adversarial Robustness of Multimodal Large Language Models and A Systematic Evaluation of Adversarial Attacks Against Speech Emotion Recognition have explored adversarial attacks on related speech tasks.
The key insight behind their approach is to treat adversarial perturbations as a type of noise that can be removed or detected using self-supervised learning models (SSLMs). SSLMs have shown promise in alleviating superficial noise and reconstructing clean samples from corrupted ones.
Their proposed defense framework has two main components:
- Adversarial perturbation purification: An SSLM is used to remove the adversarial perturbations from the audio, allowing the ASV system to correctly identify the speaker.
- Adversarial perturbation detection: Another SSLM is used to detect when the audio has been maliciously altered, so the ASV system can reject it.
The researchers conducted experiments to evaluate the effectiveness of their approach. They found that the detection module was able to identify adversarial samples with an accuracy of around 80%.
Additionally, the researchers recognized that there was no common metric for evaluating adversarial defenses in ASV systems. To address this, they proposed a new evaluation framework that considers both the purification and detection aspects of their approach.
Critical Analysis
The researchers have presented a novel and promising approach to defending ASV systems against adversarial attacks without requiring knowledge of the specific attack algorithms. By leveraging self-supervised learning models, they have demonstrated the ability to effectively purify and detect adversarial perturbations.
One potential limitation of their approach is that it may not be as effective against more sophisticated adversarial attacks that are specifically designed to bypass or circumvent the purification and detection mechanisms. The researchers acknowledge this in the paper and suggest that further research is needed to address this challenge.
Additionally, the researchers' proposed evaluation framework is a valuable contribution to the field, as it provides a standardized way to assess the performance of adversarial defenses for ASV systems. However, it remains to be seen how widely adopted this framework will be, and whether it will evolve to keep pace with the ongoing developments in adversarial attack and defense techniques.
Overall, the researchers have made a significant step forward in addressing the critical issue of adversarial attacks on ASV systems. Their work showcases the potential of self-supervised learning models in SelfVC: Voice Conversion via Iterative Refinement Using Self and represents an important contribution to the field of speaker verification security.
Conclusion
This paper presents a novel approach to defending automatic speaker verification (ASV) systems against adversarial attacks, without requiring knowledge of the specific attack algorithms. The researchers leverage self-supervised learning models (SSLMs) to perform adversarial perturbation purification and detection, effectively shielding the ASV system from being fooled by these malicious attacks.
The researchers' experimental results demonstrate the effectiveness of their detection module, which can identify adversarial samples with an accuracy of around 80%. Additionally, the researchers have proposed a new evaluation framework for assessing adversarial defenses in ASV systems, which they hope will be widely adopted by the research community.
Overall, this work represents an important step forward in addressing the critical issue of adversarial attacks on ASV systems, and the researchers' approach has the potential to significantly improve the security and reliability of these important biometric authentication systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
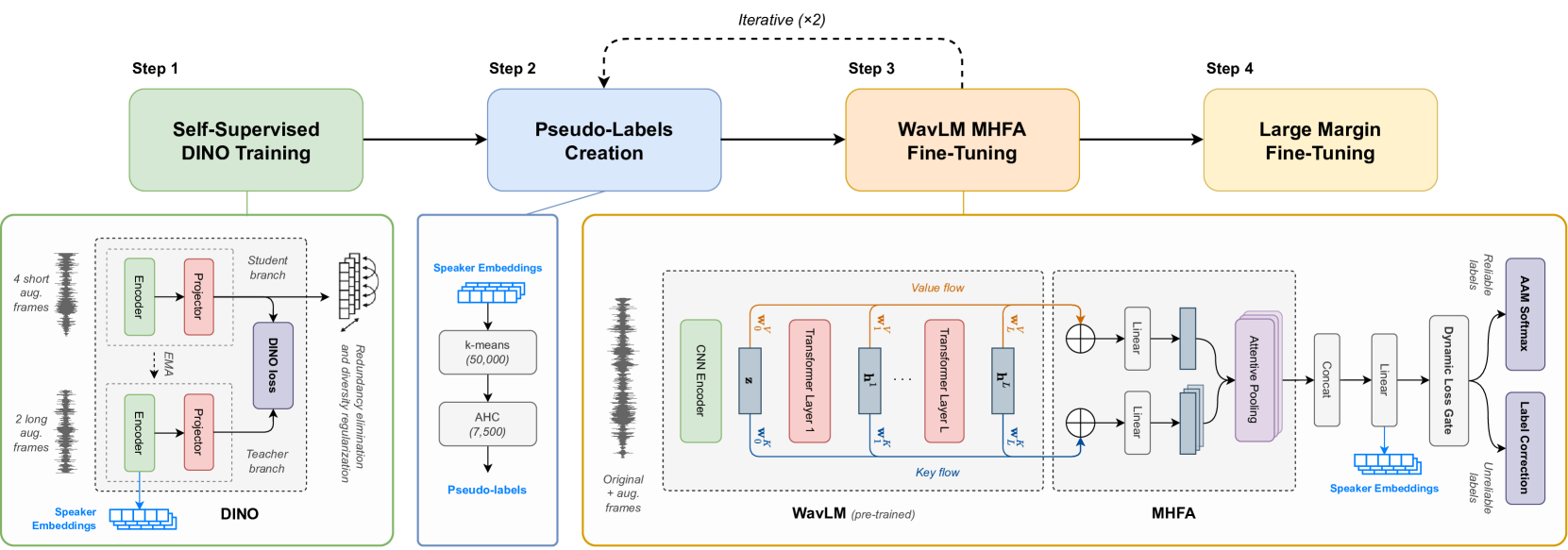
Towards Supervised Performance on Speaker Verification with Self-Supervised Learning by Leveraging Large-Scale ASR Models
Victor Miara, Theo Lepage, Reda Dehak
0
0
Recent advancements in Self-Supervised Learning (SSL) have shown promising results in Speaker Verification (SV). However, narrowing the performance gap with supervised systems remains an ongoing challenge. Several studies have observed that speech representations from large-scale ASR models contain valuable speaker information. This work explores the limitations of fine-tuning these models for SV using an SSL contrastive objective in an end-to-end approach. Then, we propose a framework to learn speaker representations in an SSL context by fine-tuning a pre-trained WavLM with a supervised loss using pseudo-labels. Initial pseudo-labels are derived from an SSL DINO-based model and are iteratively refined by clustering the model embeddings. Our method achieves 0.99% EER on VoxCeleb1-O, establishing the new state-of-the-art on self-supervised SV. As this performance is close to our supervised baseline of 0.94% EER, this contribution is a step towards supervised performance on SV with SSL.
6/5/2024

To what extent can ASV systems naturally defend against spoofing attacks?
Jee-weon Jung, Xin Wang, Nicholas Evans, Shinji Watanabe, Hye-jin Shim, Hemlata Tak, Sidhhant Arora, Junichi Yamagishi, Joon Son Chung
0
0
The current automatic speaker verification (ASV) task involves making binary decisions on two types of trials: target and non-target. However, emerging advancements in speech generation technology pose significant threats to the reliability of ASV systems. This study investigates whether ASV effortlessly acquires robustness against spoofing attacks (i.e., zero-shot capability) by systematically exploring diverse ASV systems and spoofing attacks, ranging from traditional to cutting-edge techniques. Through extensive analyses conducted on eight distinct ASV systems and 29 spoofing attack systems, we demonstrate that the evolution of ASV inherently incorporates defense mechanisms against spoofing attacks. Nevertheless, our findings also underscore that the advancement of spoofing attacks far outpaces that of ASV systems, hence necessitating further research on spoofing-robust ASV methodologies.
6/17/2024
🧠
Neural Codec-based Adversarial Sample Detection for Speaker Verification
Xuanjun Chen, Jiawei Du, Haibin Wu, Jyh-Shing Roger Jang, Hung-yi Lee
0
0
Automatic Speaker Verification (ASV), increasingly used in security-critical applications, faces vulnerabilities from rising adversarial attacks, with few effective defenses available. In this paper, we propose a neural codec-based adversarial sample detection method for ASV. The approach leverages the codec's ability to discard redundant perturbations and retain essential information. Specifically, we distinguish between genuine and adversarial samples by comparing ASV score differences between original and re-synthesized audio (by codec models). This comprehensive study explores all open-source neural codecs and their variant models for experiments. The Descript-audio-codec model stands out by delivering the highest detection rate among 15 neural codecs and surpassing seven prior state-of-the-art (SOTA) detection methods. Note that, our single-model method even outperforms a SOTA ensemble method by a large margin.
6/10/2024

Asynchronous Voice Anonymization Using Adversarial Perturbation On Speaker Embedding
Rui Wang, Liping Chen, Kong AiK Lee, Zhen-Hua Ling
0
0
Voice anonymization has been developed as a technique for preserving privacy by replacing the speaker's voice in a speech signal with that of a pseudo-speaker, thereby obscuring the original voice attributes from machine recognition and human perception. In this paper, we focus on altering the voice attributes against machine recognition while retaining human perception. We referred to this as the asynchronous voice anonymization. To this end, a speech generation framework incorporating a speaker disentanglement mechanism is employed to generate the anonymized speech. The speaker attributes are altered through adversarial perturbation applied on the speaker embedding, while human perception is preserved by controlling the intensity of perturbation. Experiments conducted on the LibriSpeech dataset showed that the speaker attributes were obscured with their human perception preserved for 60.71% of the processed utterances.
6/14/2024