Asynchronous Voice Anonymization Using Adversarial Perturbation On Speaker Embedding

0

Sign in to get full access
Overview
• This paper proposes a method for anonymizing voices in an asynchronous setting using adversarial perturbation on speaker embeddings.
• The key idea is to generate an adversarial perturbation that can be added to a speaker's voice to make it sound different, thereby anonymizing the speaker's identity while preserving the original speech content.
• This approach allows for voice anonymization without needing to re-record the audio, making it practical for real-world applications where voice data may be recorded asynchronously.
Plain English Explanation
The paper presents a technique to anonymize a person's voice without having them re-record the audio. The method works by creating a small, hidden change to the voice recording that makes it sound different, effectively hiding the speaker's identity. This is done by generating what's called an "adversarial perturbation" - a subtle alteration to the underlying speaker embedding (a mathematical representation of the speaker's voice characteristics) that alters the perceived voice without changing the actual speech content.
The advantage of this approach is that it can be applied asynchronously, meaning the anonymization can happen after the audio has already been recorded, rather than requiring the speaker to re-record everything. This makes the technique more practical for real-world scenarios where voice data may be captured independently of when it needs to be anonymized.
Technical Explanation
The paper proposes an "asynchronous voice anonymization" method that uses adversarial perturbation on speaker embeddings to alter a speaker's voice without changing the speech content.
The key steps are:
- Extract a speaker embedding - a numerical representation of the speaker's voice characteristics - from the original audio.
- Generate an adversarial perturbation to add to the speaker embedding. This perturbation is designed to make the voice sound different, anonymizing the speaker while preserving the speech content.
- Apply the adversarial perturbation to the original audio, resulting in an anonymized version of the voice recording.
This allows for voice anonymization without re-recording the audio, making it practical for real-world scenarios where voice data may be captured independently of when it needs to be anonymized.
Critical Analysis
The paper presents a novel approach to voice anonymization that addresses some of the limitations of prior work. By operating on the speaker embedding rather than the raw audio, it can perform the anonymization asynchronously, which is a valuable practical advantage.
However, the paper does not provide a thorough analysis of the perceptual quality of the anonymized voices. It would be important to understand how natural and intelligible the modified voices sound to ensure the approach is usable in real-world applications where preserving speech quality is crucial.
Additionally, the paper does not discuss the robustness of the adversarial perturbation to potential attacks or countermeasures. In a security-sensitive context, it would be important to evaluate the resilience of the anonymization technique to adversarial attempts to re-identify the speaker.
Conclusion
This paper presents a novel approach to asynchronous voice anonymization using adversarial perturbation on speaker embeddings. The key innovation is the ability to modify a speaker's voice without requiring them to re-record the audio, which enhances the practical applicability of voice anonymization techniques.
While the paper demonstrates the technical feasibility of the approach, further research is needed to assess the perceptual quality and robustness of the anonymized voices. Nonetheless, this work represents an important step towards developing more practical and secure voice anonymization solutions that can be deployed in real-world scenarios.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Asynchronous Voice Anonymization Using Adversarial Perturbation On Speaker Embedding
Rui Wang, Liping Chen, Kong AiK Lee, Zhen-Hua Ling
Voice anonymization has been developed as a technique for preserving privacy by replacing the speaker's voice in a speech signal with that of a pseudo-speaker, thereby obscuring the original voice attributes from machine recognition and human perception. In this paper, we focus on altering the voice attributes against machine recognition while retaining human perception. We referred to this as the asynchronous voice anonymization. To this end, a speech generation framework incorporating a speaker disentanglement mechanism is employed to generate the anonymized speech. The speaker attributes are altered through adversarial perturbation applied on the speaker embedding, while human perception is preserved by controlling the intensity of perturbation. Experiments conducted on the LibriSpeech dataset showed that the speaker attributes were obscured with their human perception preserved for 60.71% of the processed utterances.
Read more6/14/2024

0
Voice Conversion-based Privacy through Adversarial Information Hiding
Jacob J Webber, Oliver Watts, Gustav Eje Henter, Jennifer Williams, Simon King
Privacy-preserving voice conversion aims to remove only the attributes of speech audio that convey identity information, keeping other speech characteristics intact. This paper presents a mechanism for privacy-preserving voice conversion that allows controlling the leakage of identity-bearing information using adversarial information hiding. This enables a deliberate trade-off between maintaining source-speech characteristics and modification of speaker identity. As such, the approach improves on voice-conversion techniques like CycleGAN and StarGAN, which were not designed for privacy, meaning that converted speech may leak personal information in unpredictable ways. Our approach is also more flexible than ASR-TTS voice conversion pipelines, which by design discard all prosodic information linked to textual content. Evaluations show that the proposed system successfully modifies perceived speaker identity whilst well maintaining source lexical content.
Read more9/24/2024
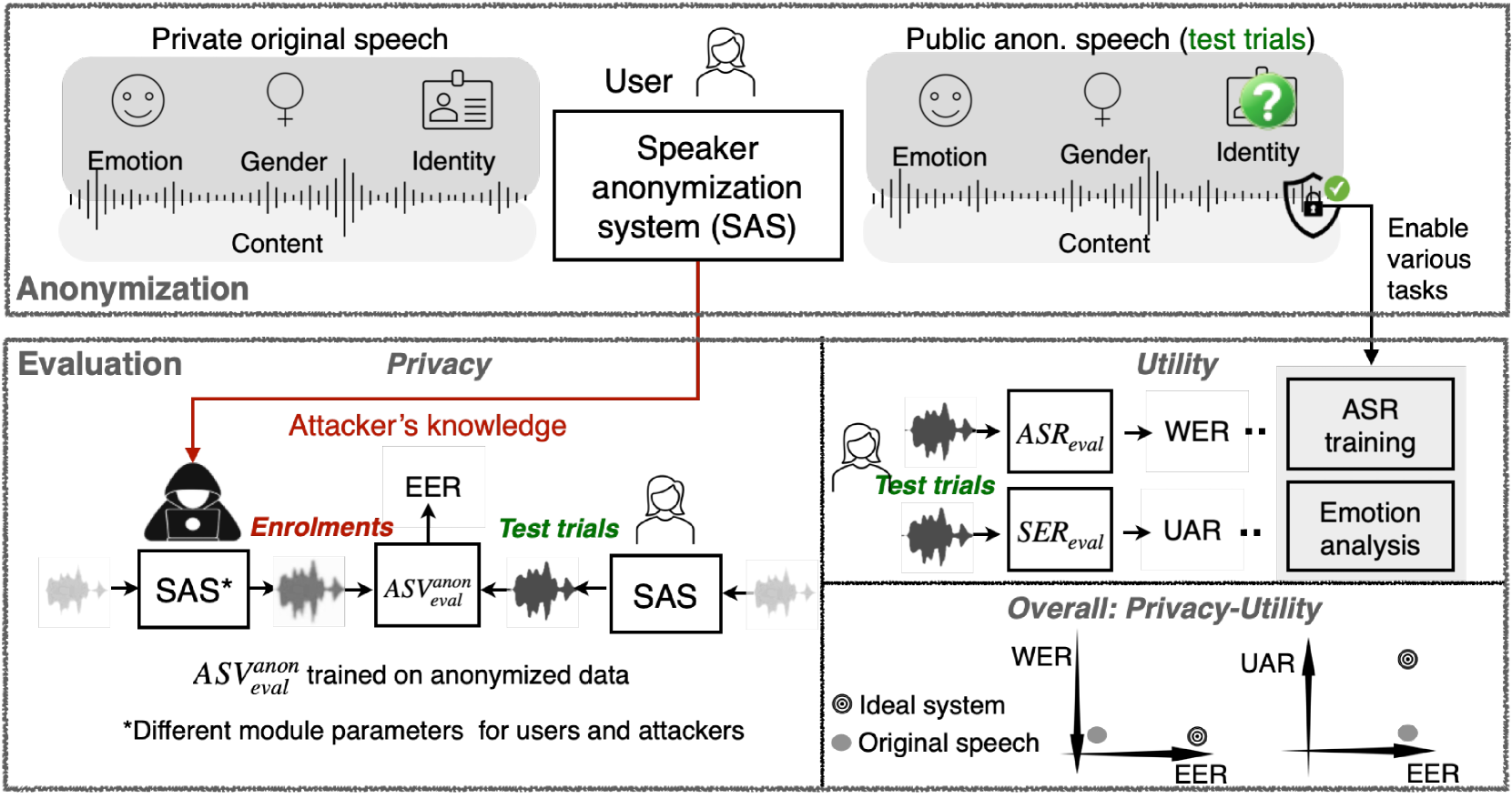
0
Adapting General Disentanglement-Based Speaker Anonymization for Enhanced Emotion Preservation
Xiaoxiao Miao, Yuxiang Zhang, Xin Wang, Natalia Tomashenko, Donny Cheng Lock Soh, Ian Mcloughlin
A general disentanglement-based speaker anonymization system typically separates speech into content, speaker, and prosody features using individual encoders. This paper explores how to adapt such a system when a new speech attribute, for example, emotion, needs to be preserved to a greater extent. While existing systems are good at anonymizing speaker embeddings, they are not designed to preserve emotion. Two strategies for this are examined. First, we show that integrating emotion embeddings from a pre-trained emotion encoder can help preserve emotional cues, even though this approach slightly compromises privacy protection. Alternatively, we propose an emotion compensation strategy as a post-processing step applied to anonymized speaker embeddings. This conceals the original speaker's identity and reintroduces the emotional traits lost during speaker embedding anonymization. Specifically, we model the emotion attribute using support vector machines to learn separate boundaries for each emotion. During inference, the original speaker embedding is processed in two ways: one, by an emotion indicator to predict emotion and select the emotion-matched SVM accurately; and two, by a speaker anonymizer to conceal speaker characteristics. The anonymized speaker embedding is then modified along the corresponding SVM boundary towards an enhanced emotional direction to save the emotional cues. The proposed strategies are also expected to be useful for adapting a general disentanglement-based speaker anonymization system to preserve other target paralinguistic attributes, with potential for a range of downstream tasks.
Read more8/13/2024

0
A Benchmark for Multi-speaker Anonymization
Xiaoxiao Miao, Ruijie Tao, Chang Zeng, Xin Wang
Privacy-preserving voice protection approaches primarily suppress privacy-related information derived from paralinguistic attributes while preserving the linguistic content. Existing solutions focus on single-speaker scenarios. However, they lack practicality for real-world applications, i.e., multi-speaker scenarios. In this paper, we present an initial attempt to provide a multi-speaker anonymization benchmark by defining the task and evaluation protocol, proposing benchmarking solutions, and discussing the privacy leakage of overlapping conversations. Specifically, ideal multi-speaker anonymization should preserve the number of speakers and the turn-taking structure of the conversation, ensuring accurate context conveyance while maintaining privacy. To achieve that, a cascaded system uses speaker diarization to aggregate the speech of each speaker and speaker anonymization to conceal speaker privacy and preserve speech content. Additionally, we propose two conversation-level speaker vector anonymization methods to improve the utility further. Both methods aim to make the original and corresponding pseudo-speaker identities of each speaker unlinkable while preserving or even improving the distinguishability among pseudo-speakers in a conversation. The first method minimizes the differential similarity across speaker pairs in the original and anonymized conversations to maintain original speaker relationships in the anonymized version. The other method minimizes the aggregated similarity across anonymized speakers to achieve better differentiation between speakers. Experiments conducted on both non-overlap simulated and real-world datasets demonstrate the effectiveness of the multi-speaker anonymization system with the proposed speaker anonymizers. Additionally, we analyzed overlapping speech regarding privacy leakage and provide potential solutions.
Read more7/9/2024