Improving Bird's Eye View Semantic Segmentation by Task Decomposition
2404.01925
0
0

Abstract
Semantic segmentation in bird's eye view (BEV) plays a crucial role in autonomous driving. Previous methods usually follow an end-to-end pipeline, directly predicting the BEV segmentation map from monocular RGB inputs. However, the challenge arises when the RGB inputs and BEV targets from distinct perspectives, making the direct point-to-point predicting hard to optimize. In this paper, we decompose the original BEV segmentation task into two stages, namely BEV map reconstruction and RGB-BEV feature alignment. In the first stage, we train a BEV autoencoder to reconstruct the BEV segmentation maps given corrupted noisy latent representation, which urges the decoder to learn fundamental knowledge of typical BEV patterns. The second stage involves mapping RGB input images into the BEV latent space of the first stage, directly optimizing the correlations between the two views at the feature level. Our approach simplifies the complexity of combining perception and generation into distinct steps, equipping the model to handle intricate and challenging scenes effectively. Besides, we propose to transform the BEV segmentation map from the Cartesian to the polar coordinate system to establish the column-wise correspondence between RGB images and BEV maps. Moreover, our method requires neither multi-scale features nor camera intrinsic parameters for depth estimation and saves computational overhead. Extensive experiments on nuScenes and Argoverse show the effectiveness and efficiency of our method. Code is available at https://github.com/happytianhao/TaDe.
Create account to get full access
Overview
- The paper proposes a novel approach to improve the performance of bird's eye view (BEV) semantic segmentation, which is important for autonomous driving and robotics.
- The key idea is to decompose the overall BEV segmentation task into multiple subtasks, each focusing on a specific aspect such as object detection, instance segmentation, and semantic segmentation.
- The authors demonstrate that this task decomposition leads to significant performance gains compared to a standard end-to-end BEV segmentation model.
Plain English Explanation
Imagine you need to assemble a complex piece of furniture, like a bookshelf. Instead of trying to do the whole thing at once, it's often easier to break it down into smaller, more manageable steps - like first putting together the frame, then adding the shelves, and finally attaching any decorative elements.
This paper takes a similar approach to a computer vision problem called bird's eye view (BEV) semantic segmentation. BEV segmentation is important for autonomous vehicles and robots, as it allows them to understand the 3D layout of their surroundings from a top-down perspective.
Rather than trying to tackle the entire BEV segmentation task at once, the researchers decompose it into several sub-tasks, each focusing on a specific aspect. For example, one sub-task might be detecting the presence and location of objects, another might be segmenting individual object instances, and a third might be classifying the semantic category of each pixel (like road, car, pedestrian, etc.).
By breaking down the overall problem in this way, the researchers show that they can significantly improve the performance of the BEV segmentation model, compared to trying to solve the entire task at once. It's like the difference between assembling the whole bookshelf at once versus focusing on one piece at a time.
Technical Explanation
The paper proposes a task decomposition approach for bird's eye view (BEV) semantic segmentation. The overall BEV segmentation task is decomposed into three sub-tasks: object detection, instance segmentation, and semantic segmentation.
The authors design a multi-task network architecture that jointly optimizes these three sub-tasks. The shared backbone encoder extracts visual features, which are then fed into task-specific decoder heads. The object detection head predicts 3D bounding boxes, the instance segmentation head generates instance segmentation masks, and the semantic segmentation head produces the final BEV semantic segmentation.
The key innovation is the use of a task decomposition strategy, where each sub-task focuses on a specific aspect of the overall problem. This allows the model to learn more effectively compared to a standard end-to-end BEV segmentation approach. The authors show significant performance improvements on several BEV segmentation benchmarks.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed task decomposition approach for BEV semantic segmentation. The authors acknowledge that their method relies on accurate 3D object detection and instance segmentation, which could be limitations if those sub-tasks are not performed well.
Additionally, the paper does not explore the trade-offs between the complexity of the task decomposition and the overall model performance. It's possible that a simpler decomposition or a different set of sub-tasks could lead to similar or even better results, and this could be an area for further research.
Another potential issue is the computational overhead of the multi-task architecture, which may not be suitable for real-time applications. The paper does not provide a detailed analysis of the model's inference speed or resource requirements.
Despite these potential limitations, the core idea of task decomposition is a compelling approach that could be applicable to other complex computer vision problems beyond BEV segmentation. The paper makes a valuable contribution to the field and encourages further research in this direction.
Conclusion
This paper presents a novel task decomposition approach to improve the performance of bird's eye view (BEV) semantic segmentation, a crucial task for autonomous driving and robotics. By breaking down the overall BEV segmentation problem into sub-tasks like object detection, instance segmentation, and semantic segmentation, the authors demonstrate significant gains in segmentation accuracy compared to a standard end-to-end approach.
The task decomposition strategy allows the model to learn each sub-task more effectively, leading to better overall performance. While the approach has some potential limitations, such as increased complexity and computational overhead, the core idea is a valuable contribution to the field of computer vision. Further research exploring the trade-offs and applicability of task decomposition to other domains could yield additional insights and advances.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LetsMap: Unsupervised Representation Learning for Semantic BEV Mapping
Nikhil Gosala, Kursat Petek, B Ravi Kiran, Senthil Yogamani, Paulo Drews-Jr, Wolfram Burgard, Abhinav Valada
0
0
Semantic Bird's Eye View (BEV) maps offer a rich representation with strong occlusion reasoning for various decision making tasks in autonomous driving. However, most BEV mapping approaches employ a fully supervised learning paradigm that relies on large amounts of human-annotated BEV ground truth data. In this work, we address this limitation by proposing the first unsupervised representation learning approach to generate semantic BEV maps from a monocular frontal view (FV) image in a label-efficient manner. Our approach pretrains the network to independently reason about scene geometry and scene semantics using two disjoint neural pathways in an unsupervised manner and then finetunes it for the task of semantic BEV mapping using only a small fraction of labels in the BEV. We achieve label-free pretraining by exploiting spatial and temporal consistency of FV images to learn scene geometry while relying on a novel temporal masked autoencoder formulation to encode the scene representation. Extensive evaluations on the KITTI-360 and nuScenes datasets demonstrate that our approach performs on par with the existing state-of-the-art approaches while using only 1% of BEV labels and no additional labeled data.
5/30/2024

Benchmarking and Improving Bird's Eye View Perception Robustness in Autonomous Driving
Shaoyuan Xie, Lingdong Kong, Wenwei Zhang, Jiawei Ren, Liang Pan, Kai Chen, Ziwei Liu
0
0
Recent advancements in bird's eye view (BEV) representations have shown remarkable promise for in-vehicle 3D perception. However, while these methods have achieved impressive results on standard benchmarks, their robustness in varied conditions remains insufficiently assessed. In this study, we present RoboBEV, an extensive benchmark suite designed to evaluate the resilience of BEV algorithms. This suite incorporates a diverse set of camera corruption types, each examined over three severity levels. Our benchmarks also consider the impact of complete sensor failures that occur when using multi-modal models. Through RoboBEV, we assess 33 state-of-the-art BEV-based perception models spanning tasks like detection, map segmentation, depth estimation, and occupancy prediction. Our analyses reveal a noticeable correlation between the model's performance on in-distribution datasets and its resilience to out-of-distribution challenges. Our experimental results also underline the efficacy of strategies like pre-training and depth-free BEV transformations in enhancing robustness against out-of-distribution data. Furthermore, we observe that leveraging extensive temporal information significantly improves the model's robustness. Based on our observations, we design an effective robustness enhancement strategy based on the CLIP model. The insights from this study pave the way for the development of future BEV models that seamlessly combine accuracy with real-world robustness.
5/28/2024

SG-BEV: Satellite-Guided BEV Fusion for Cross-View Semantic Segmentation
Junyan Ye, Qiyan Luo, Jinhua Yu, Huaping Zhong, Zhimeng Zheng, Conghui He, Weijia Li
0
0
This paper aims at achieving fine-grained building attribute segmentation in a cross-view scenario, i.e., using satellite and street-view image pairs. The main challenge lies in overcoming the significant perspective differences between street views and satellite views. In this work, we introduce SG-BEV, a novel approach for satellite-guided BEV fusion for cross-view semantic segmentation. To overcome the limitations of existing cross-view projection methods in capturing the complete building facade features, we innovatively incorporate Bird's Eye View (BEV) method to establish a spatially explicit mapping of street-view features. Moreover, we fully leverage the advantages of multiple perspectives by introducing a novel satellite-guided reprojection module, optimizing the uneven feature distribution issues associated with traditional BEV methods. Our method demonstrates significant improvements on four cross-view datasets collected from multiple cities, including New York, San Francisco, and Boston. On average across these datasets, our method achieves an increase in mIOU by 10.13% and 5.21% compared with the state-of-the-art satellite-based and cross-view methods. The code and datasets of this work will be released at https://github.com/yejy53/SG-BEV.
4/4/2024
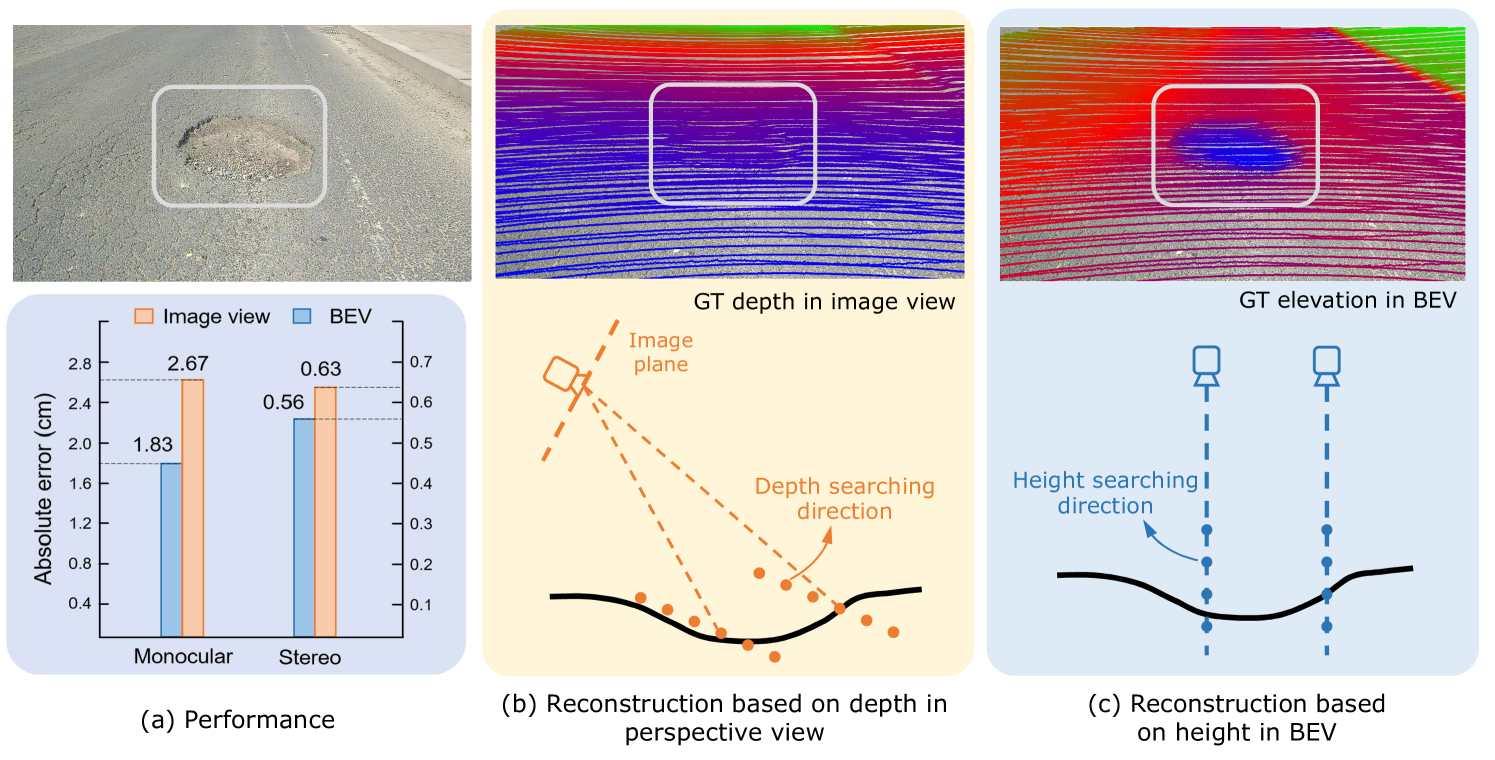
RoadBEV: Road Surface Reconstruction in Bird's Eye View
Tong Zhao, Lei Yang, Yichen Xie, Mingyu Ding, Masayoshi Tomizuka, Yintao Wei
0
0
Road surface conditions, especially geometry profiles, enormously affect driving performance of autonomous vehicles. Vision-based online road reconstruction promisingly captures road information in advance. Existing solutions like monocular depth estimation and stereo matching suffer from modest performance. The recent technique of Bird's-Eye-View (BEV) perception provides immense potential to more reliable and accurate reconstruction. This paper uniformly proposes two simple yet effective models for road elevation reconstruction in BEV named RoadBEV-mono and RoadBEV-stereo, which estimate road elevation with monocular and stereo images, respectively. The former directly fits elevation values based on voxel features queried from image view, while the latter efficiently recognizes road elevation patterns based on BEV volume representing discrepancy between left and right voxel features. Insightful analyses reveal their consistence and difference with perspective view. Experiments on real-world dataset verify the models' effectiveness and superiority. Elevation errors of RoadBEV-mono and RoadBEV-stereo achieve 1.83cm and 0.50cm, respectively. The estimation performance improves by 50% in BEV based on monocular image. Our models are promising for practical applications, providing valuable references for vision-based BEV perception in autonomous driving. The code is released at https://github.com/ztsrxh/RoadBEV.
4/24/2024