Improving face generation quality and prompt following with synthetic captions
2405.10864
0
0
Abstract
Recent advancements in text-to-image generation using diffusion models have significantly improved the quality of generated images and expanded the ability to depict a wide range of objects. However, ensuring that these models adhere closely to the text prompts remains a considerable challenge. This issue is particularly pronounced when trying to generate photorealistic images of humans. Without significant prompt engineering efforts models often produce unrealistic images and typically fail to incorporate the full extent of the prompt information. This limitation can be largely attributed to the nature of captions accompanying the images used in training large scale diffusion models, which typically prioritize contextual information over details related to the person's appearance. In this paper we address this issue by introducing a training-free pipeline designed to generate accurate appearance descriptions from images of people. We apply this method to create approximately 250,000 captions for publicly available face datasets. We then use these synthetic captions to fine-tune a text-to-image diffusion model. Our results demonstrate that this approach significantly improves the model's ability to generate high-quality, realistic human faces and enhances adherence to the given prompts, compared to the baseline model. We share our synthetic captions, pretrained checkpoints and training code.
Create account to get full access
Introduction
This research paper explores a novel approach to improving the quality of face generation and the ability of language models to follow prompts when generating images. The key idea is to use synthetic captions - automatically generated text descriptions of human faces - to enhance the training process of these AI systems.
Synthetic Captions for Human Faces
Overview
- The researchers developed a system to generate synthetic captions for human face images
- These captions were then used to improve the training of text-to-image and image-to-text models
- The goal was to enhance the realism and prompt-following ability of the generated faces
Plain English Explanation
The researchers realized that existing text-to-image and image-to-text models, while powerful, sometimes struggled to generate realistic human faces or accurately follow text prompts when creating face images. To address this, they created a system that could automatically generate detailed textual descriptions, or "captions," for human face images.
These synthetic captions were then used to augment the training data for the AI models. By exposing the models to both the face images and the corresponding captions during training, the researchers found that the models were able to better understand the relationship between faces and language. This, in turn, led to improvements in the realism and prompt-following ability of the generated face images.
The key insight was that providing the models with this additional "synthetic" training data, in the form of the automated captions, helped them learn more nuanced representations of human faces. This allowed the models to better capture the subtle details and characteristics that are important for generating realistic and prompt-aligned face images.
Technical Explanation
The researchers first developed a captioning model that could generate detailed textual descriptions for human face images. This was done by fine-tuning a pre-trained language model on a large dataset of face images paired with human-written captions.
Once the captioning model was trained, it was used to generate synthetic captions for a separate dataset of face images. These synthetic captions were then combined with the original face images to create an augmented training dataset for text-to-image and image-to-text models.
The researchers evaluated the performance of these models on benchmarks for face generation quality and prompt-following ability. They found that the models trained on the augmented dataset, which included the synthetic captions, significantly outperformed those trained on the original data alone.
Critical Analysis
The researchers acknowledged that their approach relies on the quality of the synthetic captions, and that any biases or inaccuracies in the captions could potentially be reflected in the generated face images. Additionally, the paper did not explore the limits of how much synthetic data can be effectively used to improve model performance.
While the results are promising, further research is needed to fully understand the trade-offs and potential pitfalls of this approach. Careful evaluation of the generated faces, as well as investigation into the generalization capabilities of the models, would be valuable next steps.
Conclusion
This research presents an innovative approach to enhancing the quality and prompt-following ability of face generation models by leveraging automatically generated synthetic captions. The findings suggest that incorporating such textual information can lead to significant improvements in the realism and controllability of the generated faces.
The implications of this work extend beyond face generation, as the principles of using synthetic data to augment and improve AI models could potentially be applied to other domains as well. As AI systems become more advanced and integrated into our daily lives, techniques like this that enhance their capabilities while maintaining quality and safety will be increasingly important.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Improving Text Generation on Images with Synthetic Captions
Jun Young Koh, Sang Hyun Park, Joy Song
0
0
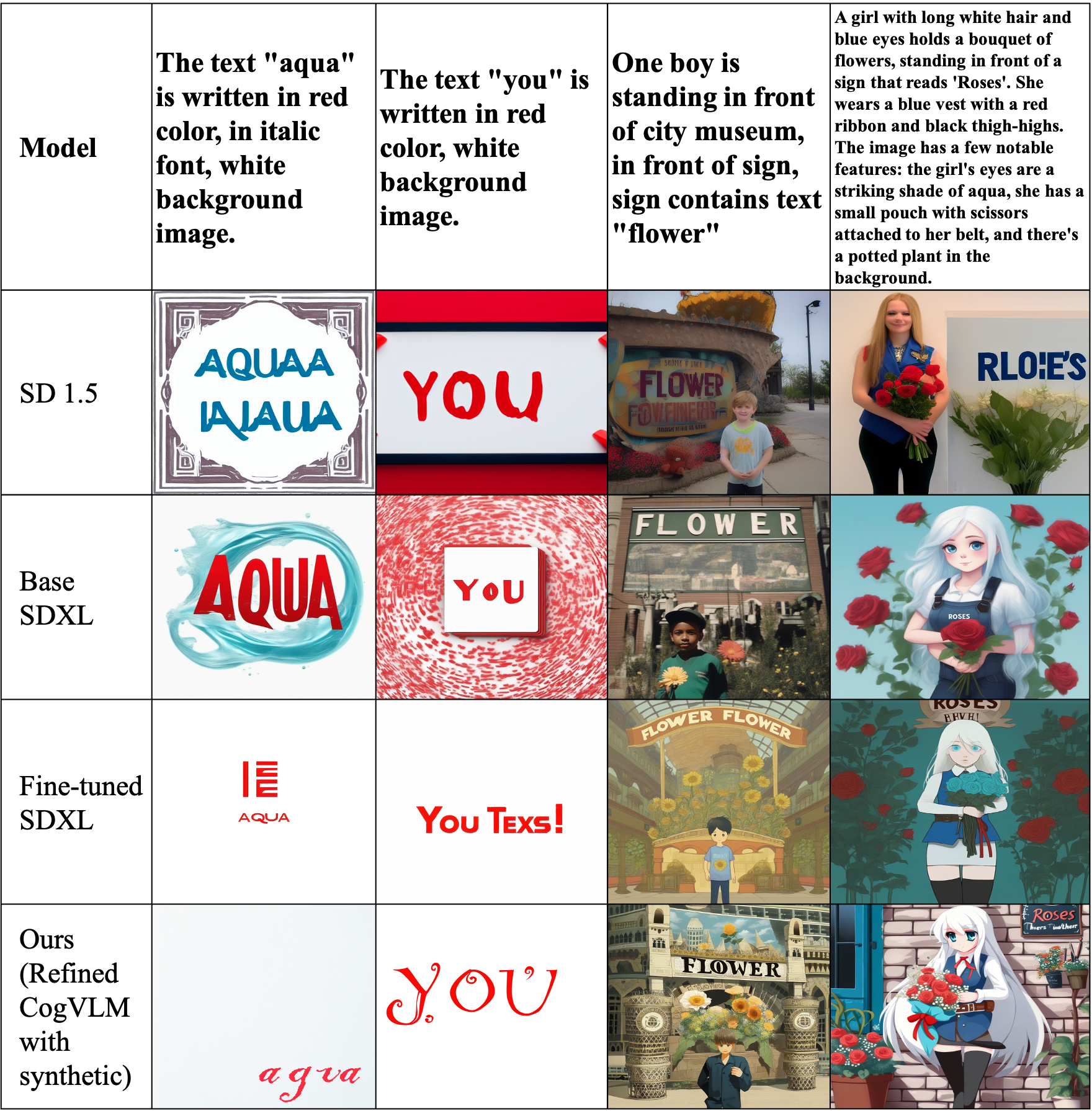
The recent emergence of latent diffusion models such as SDXL and SD 1.5 has shown significant capability in generating highly detailed and realistic images. Despite their remarkable ability to produce images, generating accurate text within images still remains a challenging task. In this paper, we examine the validity of fine-tuning approaches in generating legible text within the image. We propose a low-cost approach by leveraging SDXL without any time-consuming training on large-scale datasets. The proposed strategy employs a fine-tuning technique that examines the effects of data refinement levels and synthetic captions. Moreover, our results demonstrate how our small scale fine-tuning approach can improve the accuracy of text generation in different scenarios without the need of additional multimodal encoders. Our experiments show that with the addition of random letters to our raw dataset, our model's performance improves in producing well-formed visual text.
6/4/2024
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
0
0
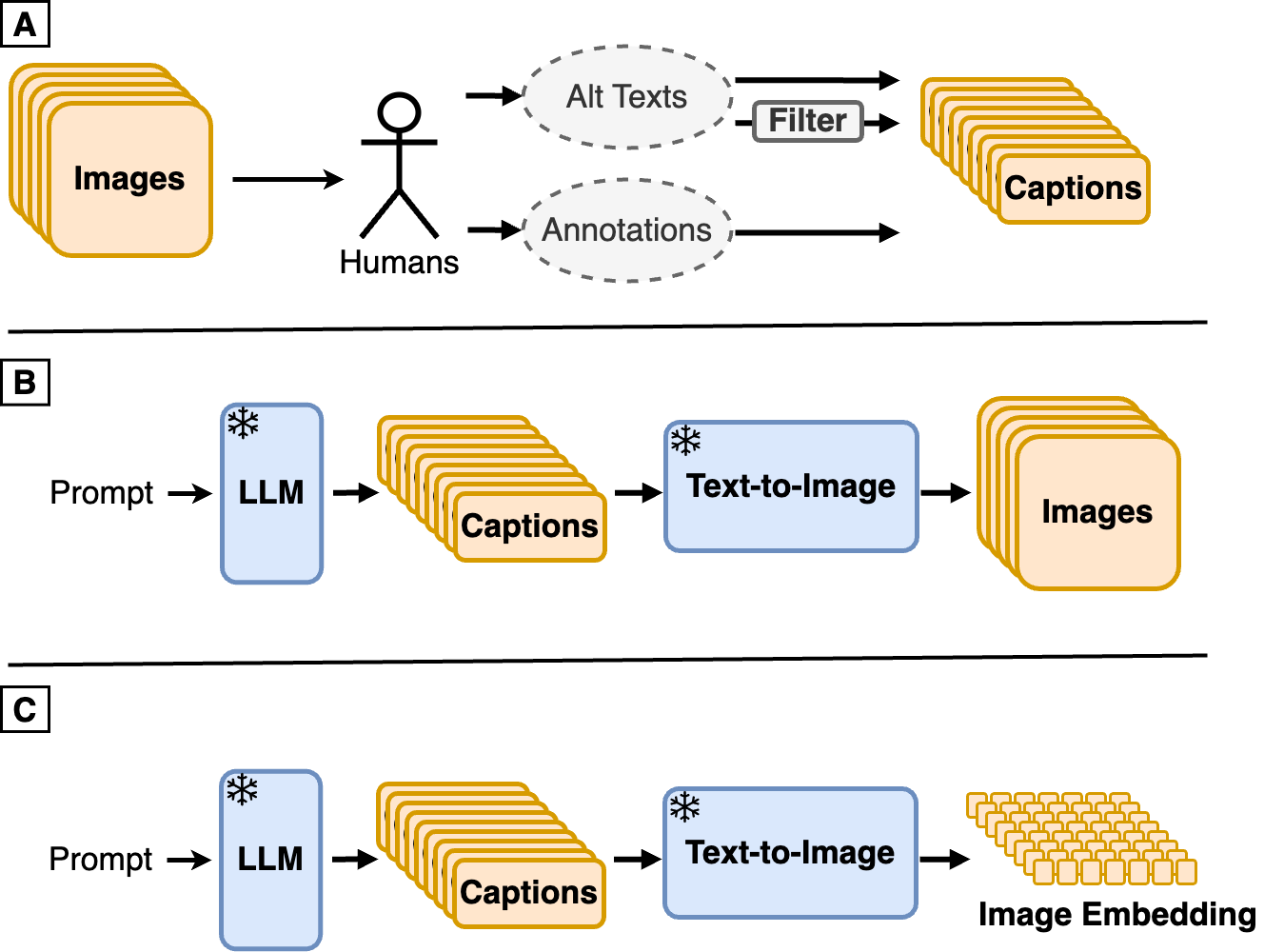
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
6/10/2024
🛸
Tailored Visions: Enhancing Text-to-Image Generation with Personalized Prompt Rewriting
Zijie Chen, Lichao Zhang, Fangsheng Weng, Lili Pan, Zhenzhong Lan
0
0
Despite significant progress in the field, it is still challenging to create personalized visual representations that align closely with the desires and preferences of individual users. This process requires users to articulate their ideas in words that are both comprehensible to the models and accurately capture their vision, posing difficulties for many users. In this paper, we tackle this challenge by leveraging historical user interactions with the system to enhance user prompts. We propose a novel approach that involves rewriting user prompts based on a newly collected large-scale text-to-image dataset with over 300k prompts from 3115 users. Our rewriting model enhances the expressiveness and alignment of user prompts with their intended visual outputs. Experimental results demonstrate the superiority of our methods over baseline approaches, as evidenced in our new offline evaluation method and online tests. Our code and dataset are available at https://github.com/zzjchen/Tailored-Visions.
4/9/2024
🧠
CapHuman: Capture Your Moments in Parallel Universes
Chao Liang, Fan Ma, Linchao Zhu, Yingying Deng, Yi Yang
0
0
We concentrate on a novel human-centric image synthesis task, that is, given only one reference facial photograph, it is expected to generate specific individual images with diverse head positions, poses, facial expressions, and illuminations in different contexts. To accomplish this goal, we argue that our generative model should be capable of the following favorable characteristics: (1) a strong visual and semantic understanding of our world and human society for basic object and human image generation. (2) generalizable identity preservation ability. (3) flexible and fine-grained head control. Recently, large pre-trained text-to-image diffusion models have shown remarkable results, serving as a powerful generative foundation. As a basis, we aim to unleash the above two capabilities of the pre-trained model. In this work, we present a new framework named CapHuman. We embrace the encode then learn to align paradigm, which enables generalizable identity preservation for new individuals without cumbersome tuning at inference. CapHuman encodes identity features and then learns to align them into the latent space. Moreover, we introduce the 3D facial prior to equip our model with control over the human head in a flexible and 3D-consistent manner. Extensive qualitative and quantitative analyses demonstrate our CapHuman can produce well-identity-preserved, photo-realistic, and high-fidelity portraits with content-rich representations and various head renditions, superior to established baselines. Code and checkpoint will be released at https://github.com/VamosC/CapHuman.
5/20/2024