Improving Text Generation on Images with Synthetic Captions
2406.00505
0
0
Abstract
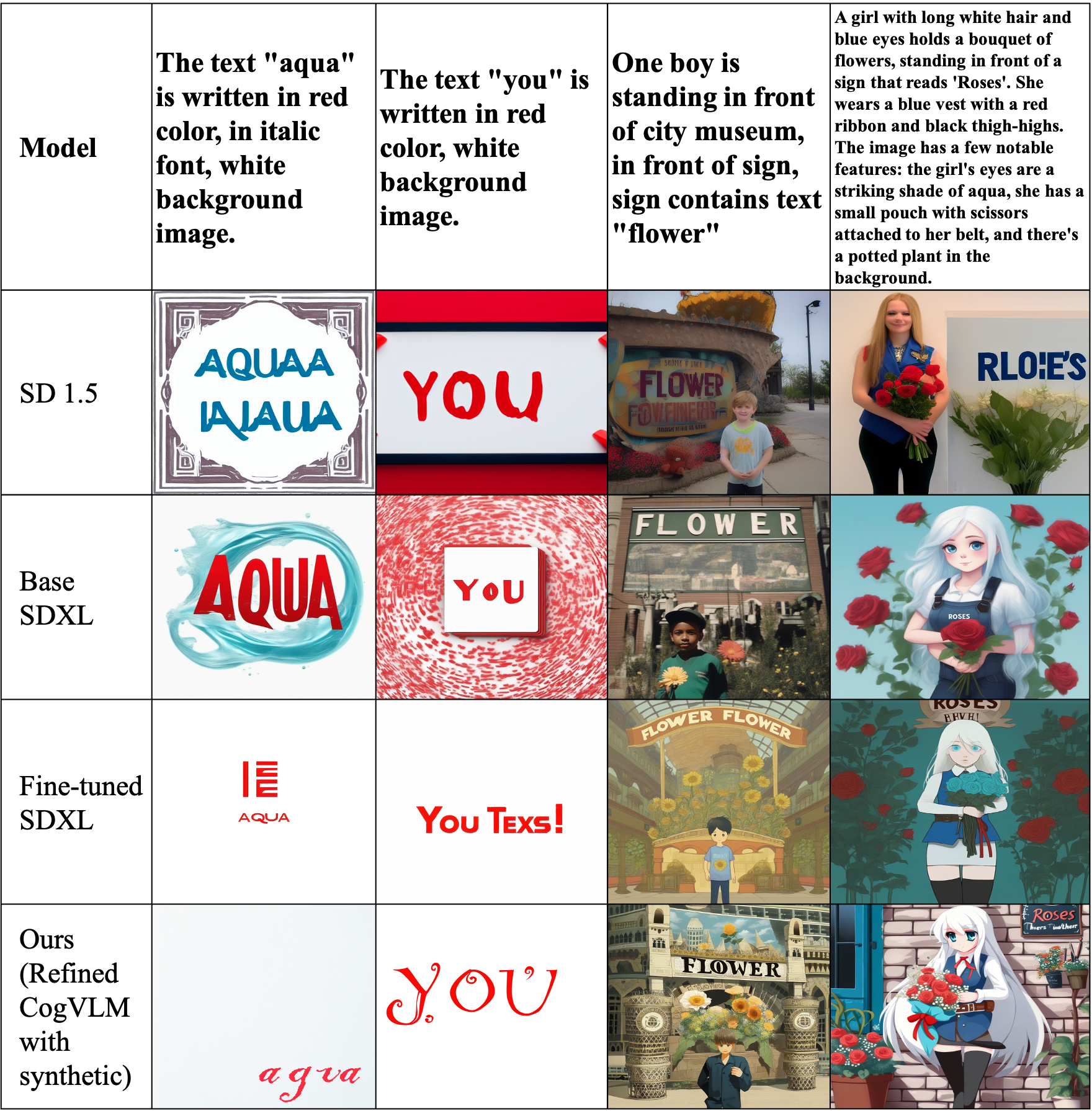
The recent emergence of latent diffusion models such as SDXL and SD 1.5 has shown significant capability in generating highly detailed and realistic images. Despite their remarkable ability to produce images, generating accurate text within images still remains a challenging task. In this paper, we examine the validity of fine-tuning approaches in generating legible text within the image. We propose a low-cost approach by leveraging SDXL without any time-consuming training on large-scale datasets. The proposed strategy employs a fine-tuning technique that examines the effects of data refinement levels and synthetic captions. Moreover, our results demonstrate how our small scale fine-tuning approach can improve the accuracy of text generation in different scenarios without the need of additional multimodal encoders. Our experiments show that with the addition of random letters to our raw dataset, our model's performance improves in producing well-formed visual text.
Create account to get full access
Overview
- This paper explores improving text generation on images using synthetic captions.
- The researchers investigate how to leverage synthetic captions generated by diffusion models to enhance the performance of text generation on images.
- They propose a novel training approach that incorporates the synthetic captions to improve the text generation capabilities of multimodal models.
Plain English Explanation
The paper focuses on enhancing the ability of AI systems to generate relevant and descriptive text for images. Traditionally, these systems are trained on real image-caption pairs, which can be time-consuming and expensive to obtain. To address this, the researchers explore using synthetic captions generated by diffusion models - a type of generative AI that can create new images or text from scratch.
The key idea is to incorporate these synthetic captions into the training process for text generation models. By exposing the models to a larger and more diverse set of image-text pairs, including the synthetic ones, the researchers hypothesize that the models will learn to generate more accurate and informative text for a given image.
This approach offers several potential benefits. First, it can help overcome the limited availability of real image-caption datasets, which often constrain the performance of text generation models. Additionally, the synthetic captions can introduce more creative and varied language, potentially leading to more engaging and diverse text output.
Technical Explanation
The researchers propose a novel training approach that leverages synthetic captions generated by diffusion models to improve text generation on images. They first train a diffusion model to generate high-quality synthetic captions for a given image. They then incorporate these synthetic captions into the training process for a multimodal text generation model, alongside the real image-caption pairs.
Specifically, the researchers use a conditional diffusion model to generate the synthetic captions. This model takes an input image and produces a corresponding caption, learning to capture the relationship between visual and textual information. The researchers then fine-tune a language model (e.g., GPT) on the combined dataset of real and synthetic image-caption pairs, enabling the model to generate more accurate and informative text for new images.
The key insight is that exposing the text generation model to a larger and more diverse set of training data, including the synthetic captions, can help it learn better representations and generate more relevant text. The researchers hypothesize that the synthetic captions introduce additional linguistic variability and creative expressions that can complement the real captions, leading to improved text generation performance.
Critical Analysis
The researchers acknowledge several limitations and areas for future work in their paper. One key concern is the potential for the synthetic captions to introduce bias or inaccuracies, which could then be propagated to the text generation model. The researchers suggest exploring approaches to filter or curate the synthetic captions to mitigate this issue.
Additionally, the paper does not provide a comprehensive evaluation of the generated text in terms of its fluency, coherence, and semantic relevance to the images. Further research could investigate these aspects more deeply, as well as the impact of the synthetic captions on the diversity and creativity of the generated text.
Another potential concern is the computational and resource requirements of training the diffusion model for synthetic caption generation, as well as the fine-tuning of the text generation model. The researchers could explore ways to optimize these processes or investigate more efficient architectures to make the approach more scalable.
Overall, the paper presents a promising approach to leveraging synthetic data to enhance text generation on images. However, additional research is needed to fully understand the limitations, potential biases, and broader implications of this technique.
Conclusion
This paper explores a novel approach to improving text generation on images by incorporating synthetic captions generated by diffusion models. The key idea is to expose text generation models to a larger and more diverse set of image-text pairs, including the synthetic captions, to enhance their performance.
The researchers demonstrate that this approach can lead to improved text generation capabilities, potentially overcoming the limitations of real-world image-caption datasets. However, the paper also highlights several areas for further research, such as addressing potential biases in the synthetic captions and more comprehensive evaluations of the generated text.
Overall, this work represents an important step forward in leveraging synthetic data to enhance multimodal AI systems, with potential implications for a wide range of applications involving image-text understanding and generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Improving face generation quality and prompt following with synthetic captions
Michail Tarasiou, Stylianos Moschoglou, Jiankang Deng, Stefanos Zafeiriou
0
0
Recent advancements in text-to-image generation using diffusion models have significantly improved the quality of generated images and expanded the ability to depict a wide range of objects. However, ensuring that these models adhere closely to the text prompts remains a considerable challenge. This issue is particularly pronounced when trying to generate photorealistic images of humans. Without significant prompt engineering efforts models often produce unrealistic images and typically fail to incorporate the full extent of the prompt information. This limitation can be largely attributed to the nature of captions accompanying the images used in training large scale diffusion models, which typically prioritize contextual information over details related to the person's appearance. In this paper we address this issue by introducing a training-free pipeline designed to generate accurate appearance descriptions from images of people. We apply this method to create approximately 250,000 captions for publicly available face datasets. We then use these synthetic captions to fine-tune a text-to-image diffusion model. Our results demonstrate that this approach significantly improves the model's ability to generate high-quality, realistic human faces and enhances adherence to the given prompts, compared to the baseline model. We share our synthetic captions, pretrained checkpoints and training code.
5/20/2024
Synth$^2$: Boosting Visual-Language Models with Synthetic Captions and Image Embeddings
Sahand Sharifzadeh, Christos Kaplanis, Shreya Pathak, Dharshan Kumaran, Anastasija Ilic, Jovana Mitrovic, Charles Blundell, Andrea Banino
0
0
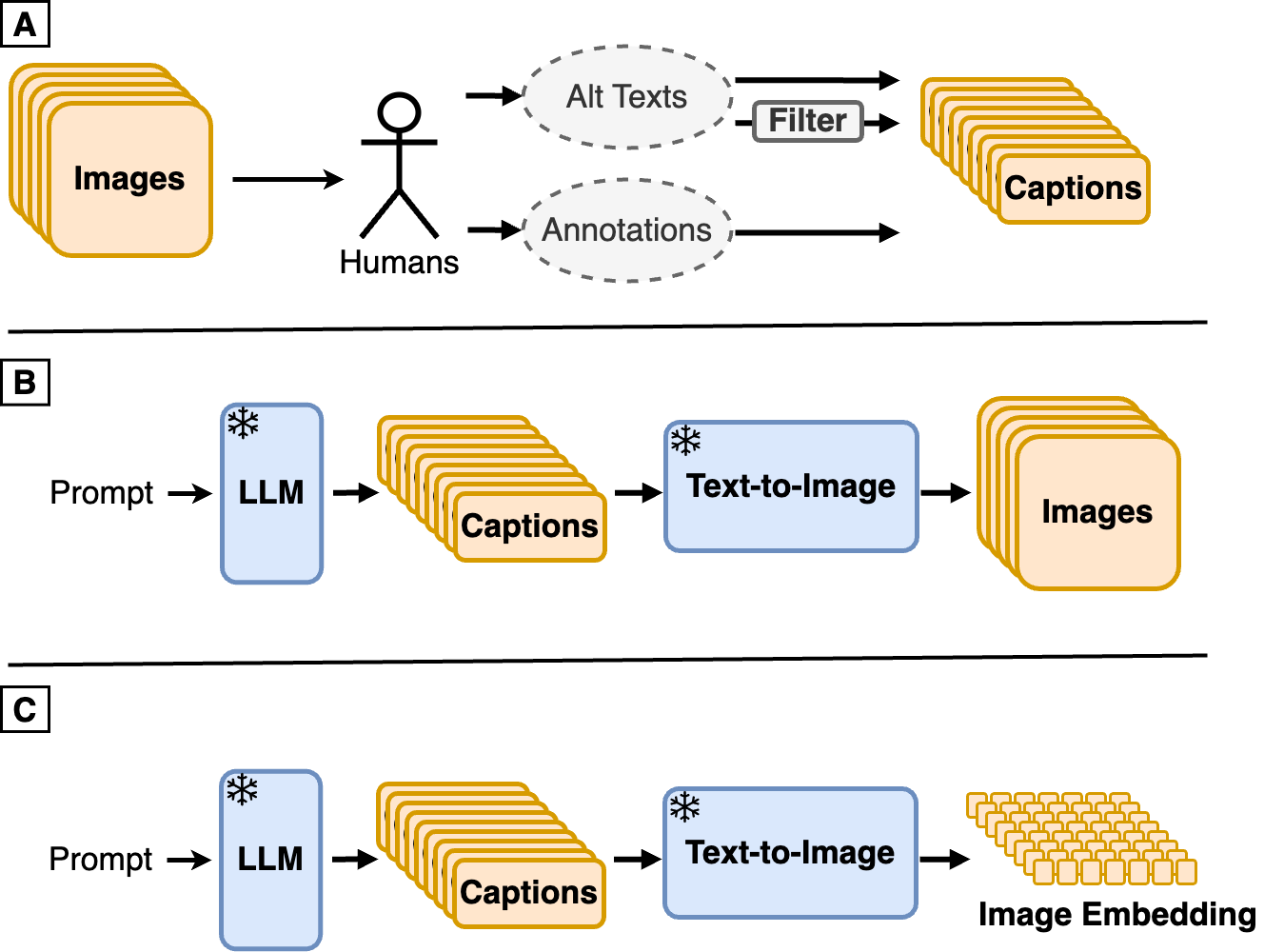
The creation of high-quality human-labeled image-caption datasets presents a significant bottleneck in the development of Visual-Language Models (VLMs). In this work, we investigate an approach that leverages the strengths of Large Language Models (LLMs) and image generation models to create synthetic image-text pairs for efficient and effective VLM training. Our method employs a pretrained text-to-image model to synthesize image embeddings from captions generated by an LLM. Despite the text-to-image model and VLM initially being trained on the same data, our approach leverages the image generator's ability to create novel compositions, resulting in synthetic image embeddings that expand beyond the limitations of the original dataset. Extensive experiments demonstrate that our VLM, finetuned on synthetic data achieves comparable performance to models trained solely on human-annotated data, while requiring significantly less data. Furthermore, we perform a set of analyses on captions which reveals that semantic diversity and balance are key aspects for better downstream performance. Finally, we show that synthesizing images in the image embedding space is 25% faster than in the pixel space. We believe our work not only addresses a significant challenge in VLM training but also opens up promising avenues for the development of self-improving multi-modal models.
6/10/2024
📊
CapsFusion: Rethinking Image-Text Data at Scale
Qiying Yu, Quan Sun, Xiaosong Zhang, Yufeng Cui, Fan Zhang, Yue Cao, Xinlong Wang, Jingjing Liu
0
0
Large multimodal models demonstrate remarkable generalist ability to perform diverse multimodal tasks in a zero-shot manner. Large-scale web-based image-text pairs contribute fundamentally to this success, but suffer from excessive noise. Recent studies use alternative captions synthesized by captioning models and have achieved notable benchmark performance. However, our experiments reveal significant Scalability Deficiency and World Knowledge Loss issues in models trained with synthetic captions, which have been largely obscured by their initial benchmark success. Upon closer examination, we identify the root cause as the overly-simplified language structure and lack of knowledge details in existing synthetic captions. To provide higher-quality and more scalable multimodal pretraining data, we propose CapsFusion, an advanced framework that leverages large language models to consolidate and refine information from both web-based image-text pairs and synthetic captions. Extensive experiments show that CapsFusion captions exhibit remarkable all-round superiority over existing captions in terms of model performance (e.g., 18.8 and 18.3 improvements in CIDEr score on COCO and NoCaps), sample efficiency (requiring 11-16 times less computation than baselines), world knowledge depth, and scalability. These effectiveness, efficiency and scalability advantages position CapsFusion as a promising candidate for future scaling of LMM training.
4/8/2024
🤯
Improving Text-To-Audio Models with Synthetic Captions
Zhifeng Kong, Sang-gil Lee, Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Rafael Valle, Soujanya Poria, Bryan Catanzaro
0
0
It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new textit{state-of-the-art}.
6/26/2024