Improving Pretraining Data Using Perplexity Correlations

0

Sign in to get full access
Overview
- This paper explores a method to improve the pretraining data used for large language models.
- The key idea is to use perplexity, a metric that measures how well a language model can predict the next word in a sequence, to identify high-quality training data.
- The authors show that filtering the pretraining data based on perplexity correlations can lead to better model performance on downstream tasks.
Plain English Explanation
Pretraining large language models like GPT-3 or BERT on massive amounts of text data is a critical step in enabling their impressive capabilities. However, not all data is equally useful for pretraining. Some text may be irrelevant, low-quality, or redundant, and including it could actually hurt the model's performance.
The key insight in this paper is that we can use a metric called perplexity to identify high-quality pretraining data. Perplexity measures how well a language model can predict the next word in a sequence of text. Texts that have lower perplexity, meaning the model can predict the words more accurately, are likely to be higher quality and more relevant for pretraining.
The researchers show that by filtering the pretraining dataset to include only the text with the lowest perplexity, they can improve the model's performance on a variety of downstream tasks, like question answering or sentiment analysis. This suggests that being selective about the pretraining data, rather than just using all available data, can lead to better language models.
The main benefit of this approach is that it provides a principled way to curate the pretraining data, rather than relying on heuristics or manual curation, which can be time-consuming and subjective. By automating the data selection process using perplexity, the researchers were able to consistently improve model performance across multiple benchmarks.
Technical Explanation
The paper proposes a method to improve the pretraining data for large language models using perplexity correlations. Perplexity is a metric that measures how well a language model can predict the next word in a sequence of text. Texts with lower perplexity are generally considered to be of higher quality and more relevant for pretraining.
The key steps in the method are:
-
Pretraining a base language model: The researchers first pretrain a base language model on a large, unfiltered dataset.
-
Computing perplexity: They then use this base model to compute the perplexity of each text in the pretraining dataset.
-
Filtering based on perplexity: Finally, they filter the pretraining dataset to include only the texts with the lowest perplexity, and retrain the language model on this filtered dataset.
The authors show that this perplexity-based filtering leads to significant improvements in the language model's performance on a variety of downstream tasks, including question answering, natural language inference, and text classification. The gains were consistent across different model architectures and pretraining dataset sizes.
The intuition is that by selectively including only the most predictable and coherent text, the language model is able to learn more effectively, capturing the essential patterns and structures of high-quality language. This is in contrast to simply training on all available data, which can include irrelevant or low-quality text that could potentially confuse or mislead the model during pretraining.
Critical Analysis
The paper makes a compelling case for the effectiveness of using perplexity to filter pretraining data for language models. However, there are a few important caveats to consider:
-
Reliance on a base model: The method requires pretraining an initial base model, which can be computationally expensive. In some cases, it may not be practical to retrain a base model from scratch.
-
Potential overfitting: By selecting only the lowest perplexity data, the model may end up overfitting to the specific patterns in that filtered dataset, limiting its ability to generalize to more diverse text.
-
Task-specific considerations: The optimal perplexity threshold for filtering may depend on the downstream task and model architecture. The authors did not explore how to dynamically adjust the filtering based on the target application.
-
Lack of interpretability: While perplexity provides a quantitative metric for data quality, it does not offer much interpretability into the specific characteristics of the selected data. This makes it difficult to understand why certain texts are considered higher quality.
Future work could explore ways to address these limitations, such as developing more efficient methods for computing perplexity, investigating hybrid approaches that combine perplexity-based filtering with other data curation techniques, and providing more transparency into the data selection process.
Conclusion
This paper presents a promising approach to improving the pretraining data for large language models using perplexity correlations. By selectively including only the most predictable and coherent text, the researchers were able to consistently boost the model's performance on a variety of downstream tasks.
The key takeaway is that the quality and relevance of the pretraining data can have a significant impact on the final model capabilities. While pretraining on massive datasets is common practice, this work shows that it is important to carefully curate the data to ensure it contains the most useful information for the target applications.
The perplexity-based filtering method provides a principled and automated way to achieve this data curation, potentially saving time and resources compared to manual approaches. As language models continue to grow in size and complexity, techniques like this will become increasingly important for extracting the maximum value from the available pretraining data.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Pretraining Data Using Perplexity Correlations
Tristan Thrush, Christopher Potts, Tatsunori Hashimoto
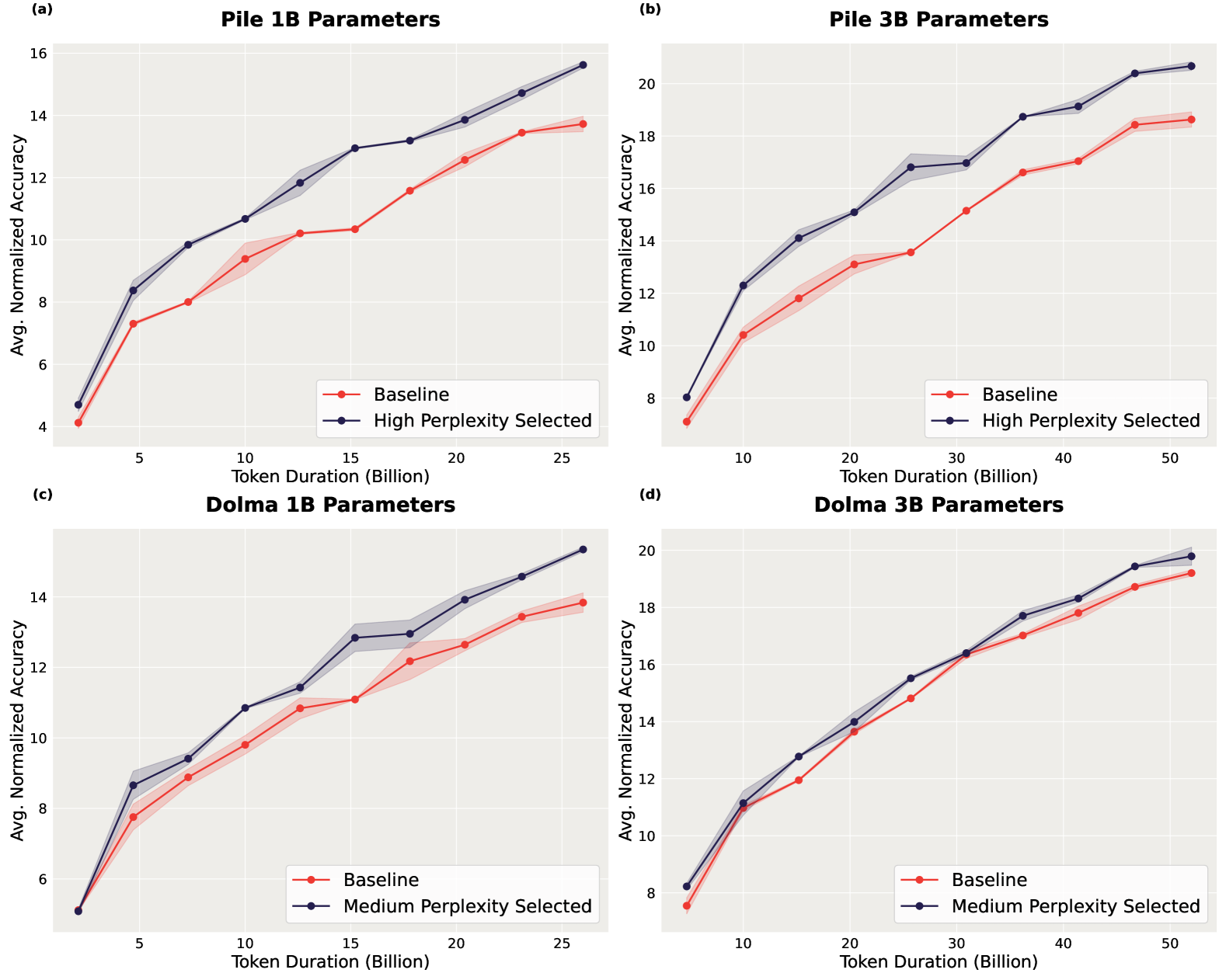
Quality pretraining data is often seen as the key to high-performance language models. However, progress in understanding pretraining data has been slow due to the costly pretraining runs required for data selection experiments. We present a framework that avoids these costs and selects high-quality pretraining data without any LLM training of our own. Our work is based on a simple observation: LLM losses on many pretraining texts are correlated with downstream benchmark performance, and selecting high-correlation documents is an effective pretraining data selection method. We build a new statistical framework for data selection centered around estimates of perplexity-benchmark correlations and perform data selection using a sample of 90 LLMs taken from the Open LLM Leaderboard on texts from tens of thousands of web domains. In controlled pretraining experiments at the 160M parameter scale on 8 benchmarks, our approach outperforms DSIR on every benchmark, while matching the best data selector found in DataComp-LM, a hand-engineered bigram classifier.
Read more9/10/2024
📊
0
Deciphering the Impact of Pretraining Data on Large Language Models through Machine Unlearning
Yang Zhao, Li Du, Xiao Ding, Kai Xiong, Zhouhao Sun, Jun Shi, Ting Liu, Bing Qin
Through pretraining on a corpus with various sources, Large Language Models (LLMs) have gained impressive performance. However, the impact of each component of the pretraining corpus remains opaque. As a result, the organization of the pretraining corpus is still empirical and may deviate from the optimal. To address this issue, we systematically analyze the impact of 48 datasets from 5 major categories of pretraining data of LLMs and measure their impacts on LLMs using benchmarks about nine major categories of model capabilities. Our analyses provide empirical results about the contribution of multiple corpora on the performances of LLMs, along with their joint impact patterns, including complementary, orthogonal, and correlational relationships. We also identify a set of ``high-impact data'' such as Books that is significantly related to a set of model capabilities. These findings provide insights into the organization of data to support more efficient pretraining of LLMs.
Read more8/29/2024
0
Perplexed by Perplexity: Perplexity-Based Data Pruning With Small Reference Models
Zachary Ankner, Cody Blakeney, Kartik Sreenivasan, Max Marion, Matthew L. Leavitt, Mansheej Paul
In this work, we investigate whether small language models can determine high-quality subsets of large-scale text datasets that improve the performance of larger language models. While existing work has shown that pruning based on the perplexity of a larger model can yield high-quality data, we investigate whether smaller models can be used for perplexity-based pruning and how pruning is affected by the domain composition of the data being pruned. We demonstrate that for multiple dataset compositions, perplexity-based pruning of pretraining data can emph{significantly} improve downstream task performance: pruning based on perplexities computed with a 125 million parameter model improves the average performance on downstream tasks of a 3 billion parameter model by up to 2.04 and achieves up to a $1.45times$ reduction in pretraining steps to reach commensurate baseline performance. Furthermore, we demonstrate that such perplexity-based data pruning also yields downstream performance gains in the over-trained and data-constrained regimes.
Read more6/3/2024

0
TextGram: Towards a better domain-adaptive pretraining
Sharayu Hiwarkhedkar, Saloni Mittal, Vidula Magdum, Omkar Dhekane, Raviraj Joshi, Geetanjali Kale, Arnav Ladkat
For green AI, it is crucial to measure and reduce the carbon footprint emitted during the training of large language models. In NLP, performing pre-training on Transformer models requires significant computational resources. This pre-training involves using a large amount of text data to gain prior knowledge for performing downstream tasks. Thus, it is important that we select the correct data in the form of domain-specific data from this vast corpus to achieve optimum results aligned with our domain-specific tasks. While training on large unsupervised data is expensive, it can be optimized by performing a data selection step before pretraining. Selecting important data reduces the space overhead and the substantial amount of time required to pre-train the model while maintaining constant accuracy. We investigate the existing selection strategies and propose our own domain-adaptive data selection method - TextGram - that effectively selects essential data from large corpora. We compare and evaluate the results of finetuned models for text classification task with and without data selection. We show that the proposed strategy works better compared to other selection methods.
Read more4/30/2024