Deciphering the Impact of Pretraining Data on Large Language Models through Machine Unlearning

0
📊
Sign in to get full access
Overview
- Large Language Models (LLMs) have achieved impressive performance through pretraining on diverse data corpora.
- However, the specific impact of each component of the pretraining corpus remains unclear.
- The organization of the pretraining corpus is still largely empirical and may not be optimal.
Plain English Explanation
The researchers aimed to systematically analyze the impact of different datasets used to train Large Language Models. These models have become very capable by being trained on a wide variety of online data. However, it's not well understood which specific parts of this training data are most important for developing different capabilities in the models.
The researchers looked at 48 different datasets across 5 major categories of pretraining data. They measured how each dataset and category of data impacted the models' performance on 9 key benchmarks, covering things like language understanding, reasoning, and other important capabilities.
This analysis provided insights into which data sources are most valuable for training LLMs, including identifying a set of "high-impact data" like books that are strongly linked to multiple model capabilities. The researchers hope these findings can help guide the organization of training data to support more efficient pretraining of these powerful language models in the future.
Technical Explanation
The researchers conducted a systematic analysis to understand the contribution of different pretraining datasets on the performance of Large Language Models. They examined 48 datasets across 5 major categories: web pages, books, dialogs, code, and academic papers.
To measure the impact of these datasets, the researchers evaluated the models on 9 different benchmarks covering key capabilities like language understanding, reasoning, and generation. By analyzing the performance deltas on these benchmarks, they were able to identify the most informative datasets and categories for developing specific model capabilities.
The analysis revealed several key patterns, including:
- Complementary relationships: Certain datasets complemented each other, with the combination leading to greater performance than either dataset alone.
- Orthogonal relationships: Some datasets appeared to provide independent, non-overlapping information that collectively improved performance.
- Correlational relationships: There were also datasets that were strongly correlated with particular model capabilities, like books being highly relevant for many capabilities.
Based on these findings, the researchers were able to identify a set of "high-impact data" sources that are most valuable for training capable Large Language Models. This provides guidance on how to organize and prioritize pretraining data to support efficient model development.
Critical Analysis
The researchers provide a thorough and systematic analysis of the impact of different pretraining datasets on Large Language Model capabilities. This is a valuable contribution, as the internal workings of these complex models are often opaque, making it difficult to understand how different components of the training data influence their performance.
However, the study is limited to a fixed set of 48 datasets and 9 benchmarks. There may be other important datasets or capabilities that were not explored. Additionally, the analysis is correlational in nature, so it cannot definitively establish causal relationships between specific datasets and model capabilities.
Further research could examine a wider range of datasets and benchmarks, or use interventional techniques to more directly probe the causal influences between data sources and model development. Exploring the generalizability of these findings to other types of language models would also be an important next step.
Overall, this work represents an important step towards understanding the "black box" of Large Language Models and provides useful guidance for optimizing their pretraining data. But additional research is needed to fully elucidate the complex relationships between training data and model capabilities.
Conclusion
This study systematically analyzed the impact of 48 pretraining datasets across 5 major categories on the capabilities of Large Language Models. The findings provide valuable insights into the most informative data sources for developing specific model capabilities, including the identification of "high-impact data" like books that are strongly linked to multiple key abilities.
These results can help guide the organization and prioritization of pretraining data to support more efficient development of capable Large Language Models in the future. By understanding the complex relationships between training data and model performance, researchers and practitioners can work towards optimizing these powerful language models for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
Deciphering the Impact of Pretraining Data on Large Language Models through Machine Unlearning
Yang Zhao, Li Du, Xiao Ding, Kai Xiong, Zhouhao Sun, Jun Shi, Ting Liu, Bing Qin
Through pretraining on a corpus with various sources, Large Language Models (LLMs) have gained impressive performance. However, the impact of each component of the pretraining corpus remains opaque. As a result, the organization of the pretraining corpus is still empirical and may deviate from the optimal. To address this issue, we systematically analyze the impact of 48 datasets from 5 major categories of pretraining data of LLMs and measure their impacts on LLMs using benchmarks about nine major categories of model capabilities. Our analyses provide empirical results about the contribution of multiple corpora on the performances of LLMs, along with their joint impact patterns, including complementary, orthogonal, and correlational relationships. We also identify a set of ``high-impact data'' such as Books that is significantly related to a set of model capabilities. These findings provide insights into the organization of data to support more efficient pretraining of LLMs.
Read more8/29/2024

0
Improving Pretraining Data Using Perplexity Correlations
Tristan Thrush, Christopher Potts, Tatsunori Hashimoto
Quality pretraining data is often seen as the key to high-performance language models. However, progress in understanding pretraining data has been slow due to the costly pretraining runs required for data selection experiments. We present a framework that avoids these costs and selects high-quality pretraining data without any LLM training of our own. Our work is based on a simple observation: LLM losses on many pretraining texts are correlated with downstream benchmark performance, and selecting high-correlation documents is an effective pretraining data selection method. We build a new statistical framework for data selection centered around estimates of perplexity-benchmark correlations and perform data selection using a sample of 90 LLMs taken from the Open LLM Leaderboard on texts from tens of thousands of web domains. In controlled pretraining experiments at the 160M parameter scale on 8 benchmarks, our approach outperforms DSIR on every benchmark, while matching the best data selector found in DataComp-LM, a hand-engineered bigram classifier.
Read more9/10/2024

0
From Pre-training Corpora to Large Language Models: What Factors Influence LLM Performance in Causal Discovery Tasks?
Tao Feng, Lizhen Qu, Niket Tandon, Zhuang Li, Xiaoxi Kang, Gholamreza Haffari
Recent advances in artificial intelligence have seen Large Language Models (LLMs) demonstrate notable proficiency in causal discovery tasks. This study explores the factors influencing the performance of LLMs in causal discovery tasks. Utilizing open-source LLMs, we examine how the frequency of causal relations within their pre-training corpora affects their ability to accurately respond to causal discovery queries. Our findings reveal that a higher frequency of causal mentions correlates with better model performance, suggesting that extensive exposure to causal information during training enhances the models' causal discovery capabilities. Additionally, we investigate the impact of context on the validity of causal relations. Our results indicate that LLMs might exhibit divergent predictions for identical causal relations when presented in different contexts. This paper provides the first comprehensive analysis of how different factors contribute to LLM performance in causal discovery tasks.
Read more7/30/2024
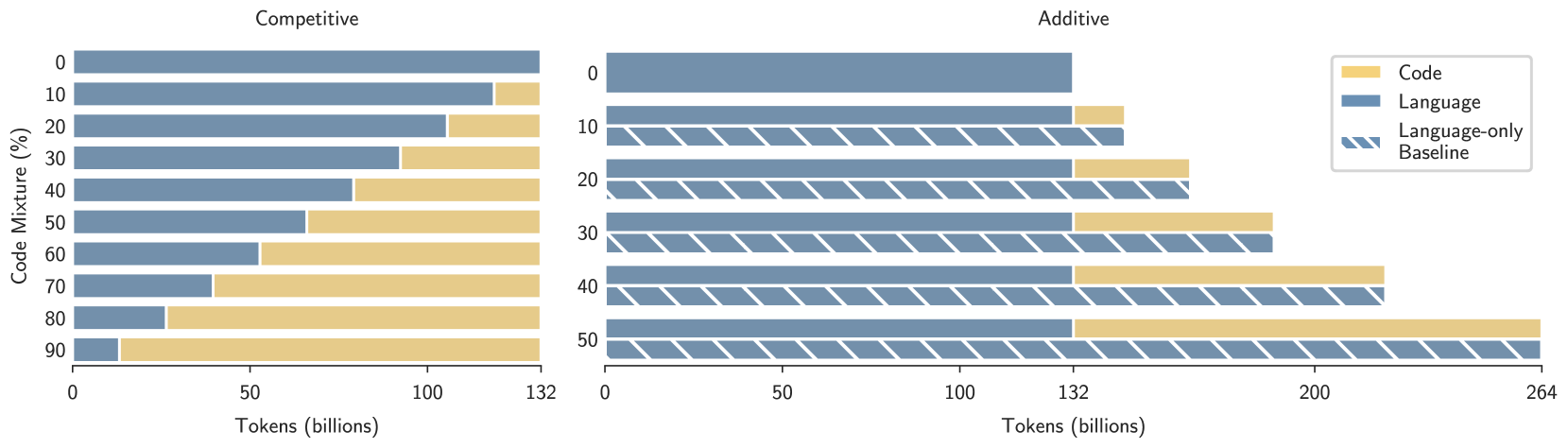
0
How Does Code Pretraining Affect Language Model Task Performance?
Jackson Petty, Sjoerd van Steenkiste, Tal Linzen
Large language models are increasingly trained on corpora containing both natural language and non-linguistic data like source code. Aside from aiding programming-related tasks, anecdotal evidence suggests that including code in pretraining corpora may improve performance on other, unrelated tasks, yet to date no work has been able to establish a causal connection by controlling between language and code data. Here we do just this. We pretrain language models on datasets which interleave natural language and code in two different settings: additive, in which the total volume of data seen during pretraining is held constant; and competitive, in which the volume of language data is held constant. We study how the pretraining mixture affects performance on (a) a diverse collection of tasks included in the BigBench benchmark, and (b) compositionality, measured by generalization accuracy on semantic parsing and syntactic transformations. We find that pretraining on higher proportions of code improves performance on compositional tasks involving structured output (like semantic parsing), and mathematics. Conversely, increase code mixture can harm performance on other tasks, including on tasks that requires sensitivity to linguistic structure such as syntax or morphology, and tasks measuring real-world knowledge.
Read more9/10/2024