Improving Retrieval Augmented Open-Domain Question-Answering with Vectorized Contexts
2404.02022
0
0
Abstract
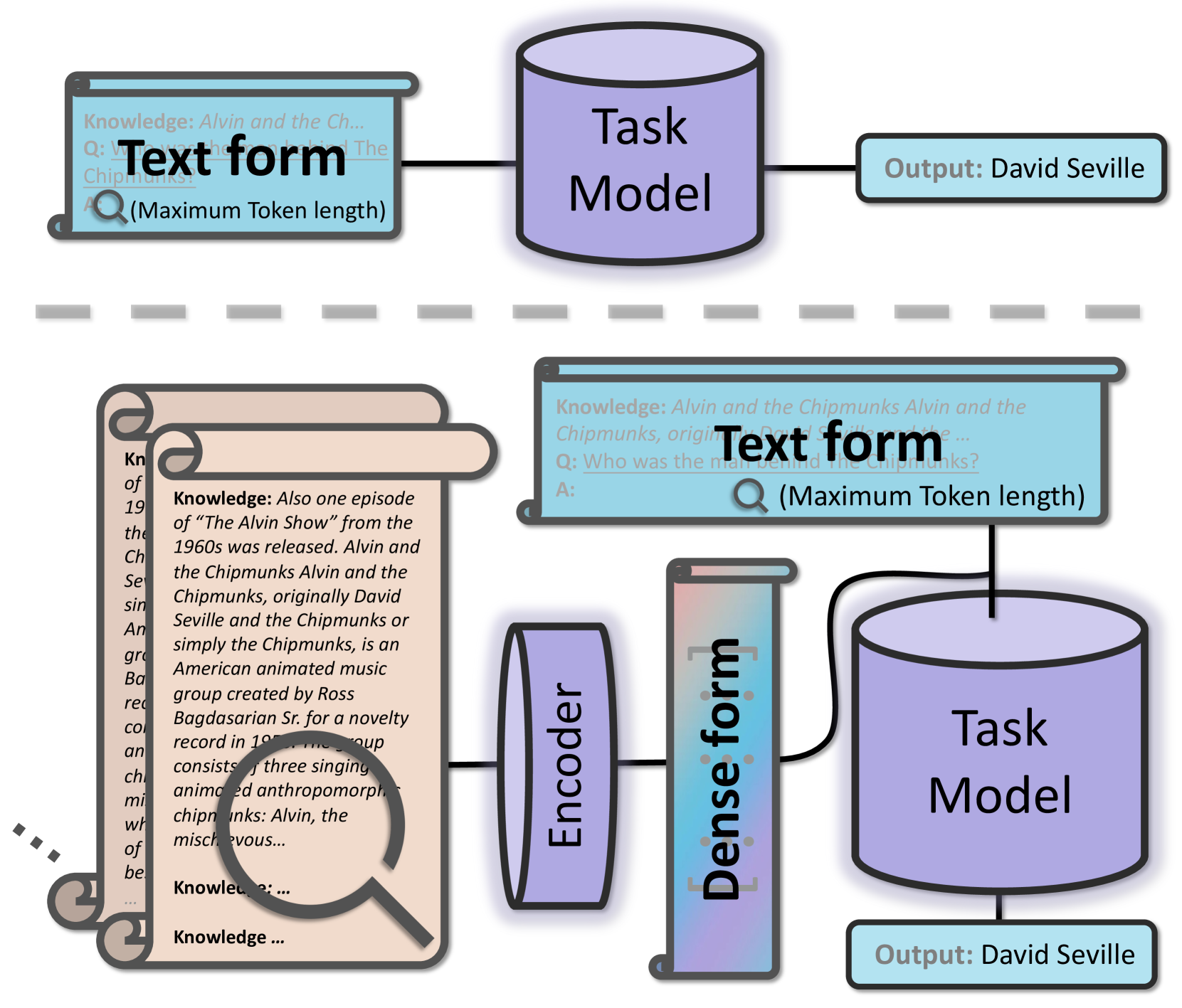
In the era of large language models, applying techniques such as Retrieval Augmented Generation can better address Open-Domain Question-Answering problems. Due to constraints including model sizes and computing resources, the length of context is often limited, and it becomes challenging to empower the model to cover overlong contexts while answering questions from open domains. This paper proposes a general and convenient method to covering longer contexts in Open-Domain Question-Answering tasks. It leverages a small encoder language model that effectively encodes contexts, and the encoding applies cross-attention with origin inputs. With our method, the origin language models can cover several times longer contexts while keeping the computing requirements close to the baseline. Our experiments demonstrate that after fine-tuning, there is improved performance across two held-in datasets, four held-out datasets, and also in two In Context Learning settings.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes an approach to improve the performance of retrieval-augmented open-domain question-answering systems.
- Key ideas include using vectorized contexts to better capture the semantics of retrieved passages and incorporating passage-level feedback to fine-tune the retriever.
- The authors evaluate their method on standard benchmarks and report improvements over existing retrieval-based QA models.
Plain English Explanation
Open-domain question answering is the task of finding accurate answers to questions using a large collection of documents, without any prior knowledge about the question topic. This is a challenging problem because the system needs to quickly and effectively search through vast amounts of information to find the most relevant passages that can answer the given question.
The authors of this paper introduce a new technique to enhance the performance of these retrieval-augmented question-answering systems. The key idea is to use "vectorized contexts" - representing the retrieved passages as dense numeric vectors that capture the semantic meaning, rather than just looking at the literal text. This allows the system to better understand the content and relevance of each passage, rather than just keyword matching.
Additionally, the authors incorporate feedback on the quality of the retrieved passages to fine-tune the retrieval model. This helps the system learn what types of passages are most useful for answering different questions, further improving its ability to find the right information.
The researchers evaluate their approach on standard benchmark datasets for open-domain question answering, and show that it outperforms existing retrieval-based methods. This suggests that the techniques of using vectorized contexts and passage-level feedback can significantly boost the performance of retrieval-augmented question-answering systems.
Technical Explanation
The paper proposes a Retrieval Augmented Question Answering (RAQA) framework that incorporates two key innovations:
-
Vectorized Contexts: Instead of representing retrieved passages as raw text, the system encodes them into dense vector representations using a pre-trained language model. This allows the downstream question-answering model to better understand the semantic meaning and relevance of each passage, rather than just relying on lexical matching.
-
Passage-level Feedback: The authors introduce a fine-tuning procedure where the retrieval model is updated based on feedback about the quality of the retrieved passages. This passage-level supervision signal helps the retriever learn to find more relevant information to answer the given questions.
The end-to-end RAQA system first retrieves a set of relevant passages using a dense retriever, then encodes those passages into vectors. The question-answering model takes the question and the vectorized passages as input, and outputs the final answer.
The authors evaluate their approach on multiple open-domain QA benchmarks, including Natural Questions, TriviaQA, and WebQuestions. They report consistent improvements over strong baseline retrieval-augmented QA models, demonstrating the effectiveness of using vectorized contexts and passage-level feedback.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed RAQA framework. The authors carefully ablate the contributions of the two key innovations - vectorized contexts and passage-level feedback - to validate their importance.
However, one potential limitation is that the experiments are conducted on a relatively limited set of datasets. It would be valuable to see how the method generalizes to a wider range of open-domain QA tasks, including those with different characteristics (e.g., different question types, varying passage lengths, multilingual datasets).
Additionally, the paper does not provide much insight into the failure cases or limitations of the approach. It would be helpful to understand the types of questions or situations where the RAQA system still struggles, and to discuss potential future research directions to address these challenges.
That said, the overall technical contributions appear sound, and the empirical results convincingly demonstrate the benefits of the proposed innovations. The work provides a strong foundation for further research into improving retrieval-augmented open-domain question-answering systems.
Conclusion
This paper introduces an effective approach to enhance retrieval-augmented open-domain question-answering systems. By using vectorized contexts to better capture passage semantics and incorporating passage-level feedback to fine-tune the retriever, the authors show consistent performance improvements over existing retrieval-based QA models.
The techniques proposed in this work represent an important step forward in making open-domain QA systems more accurate and robust. As large language models and knowledge retrieval capabilities continue to advance, research like this will play a crucial role in building question-answering systems that can reliably provide useful answers to a wide range of questions from diverse information sources.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Retrieval Augmented Generation for Domain-specific Question Answering
Sanat Sharma, David Seunghyun Yoon, Franck Dernoncourt, Dewang Sultania, Karishma Bagga, Mengjiao Zhang, Trung Bui, Varun Kotte
0
0
Question answering (QA) has become an important application in the advanced development of large language models. General pre-trained large language models for question-answering are not trained to properly understand the knowledge or terminology for a specific domain, such as finance, healthcare, education, and customer service for a product. To better cater to domain-specific understanding, we build an in-house question-answering system for Adobe products. We propose a novel framework to compile a large question-answer database and develop the approach for retrieval-aware finetuning of a Large Language model. We showcase that fine-tuning the retriever leads to major improvements in the final generation. Our overall approach reduces hallucinations during generation while keeping in context the latest retrieval information for contextual grounding.
4/24/2024
Towards Better Generalization in Open-Domain Question Answering by Mitigating Context Memorization
Zixuan Zhang, Revanth Gangi Reddy, Kevin Small, Tong Zhang, Heng Ji
0
0
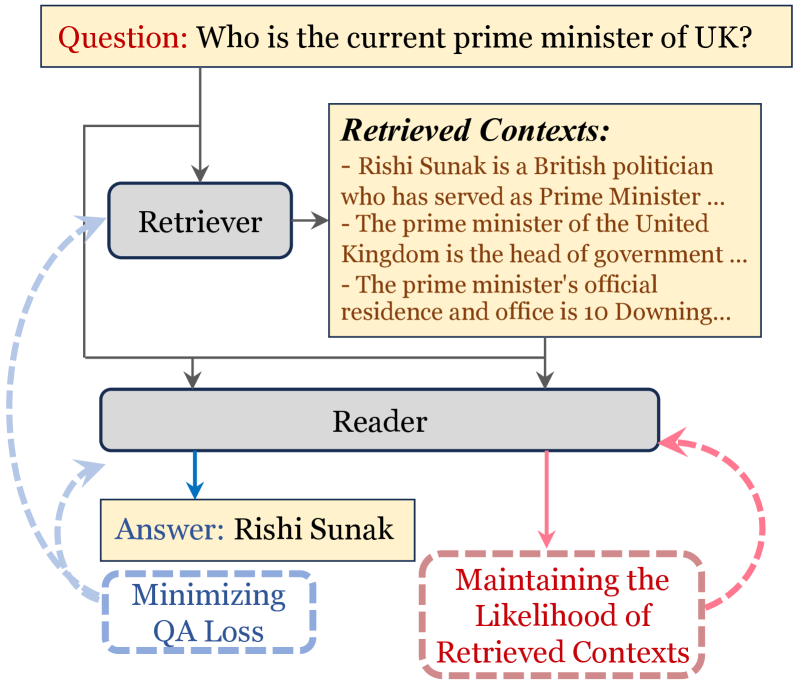
Open-domain Question Answering (OpenQA) aims at answering factual questions with an external large-scale knowledge corpus. However, real-world knowledge is not static; it updates and evolves continually. Such a dynamic characteristic of knowledge poses a vital challenge for these models, as the trained models need to constantly adapt to the latest information to make sure that the answers remain accurate. In addition, it is still unclear how well an OpenQA model can transfer to completely new knowledge domains. In this paper, we investigate the generalization performance of a retrieval-augmented QA model in two specific scenarios: 1) adapting to updated versions of the same knowledge corpus; 2) switching to completely different knowledge domains. We observe that the generalization challenges of OpenQA models stem from the reader's over-reliance on memorizing the knowledge from the external corpus, which hinders the model from generalizing to a new knowledge corpus. We introduce Corpus-Invariant Tuning (CIT), a simple but effective training strategy, to mitigate the knowledge over-memorization by controlling the likelihood of retrieved contexts during training. Extensive experimental results on multiple OpenQA benchmarks show that CIT achieves significantly better generalizability without compromising the model's performance in its original corpus and domain.
4/3/2024
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
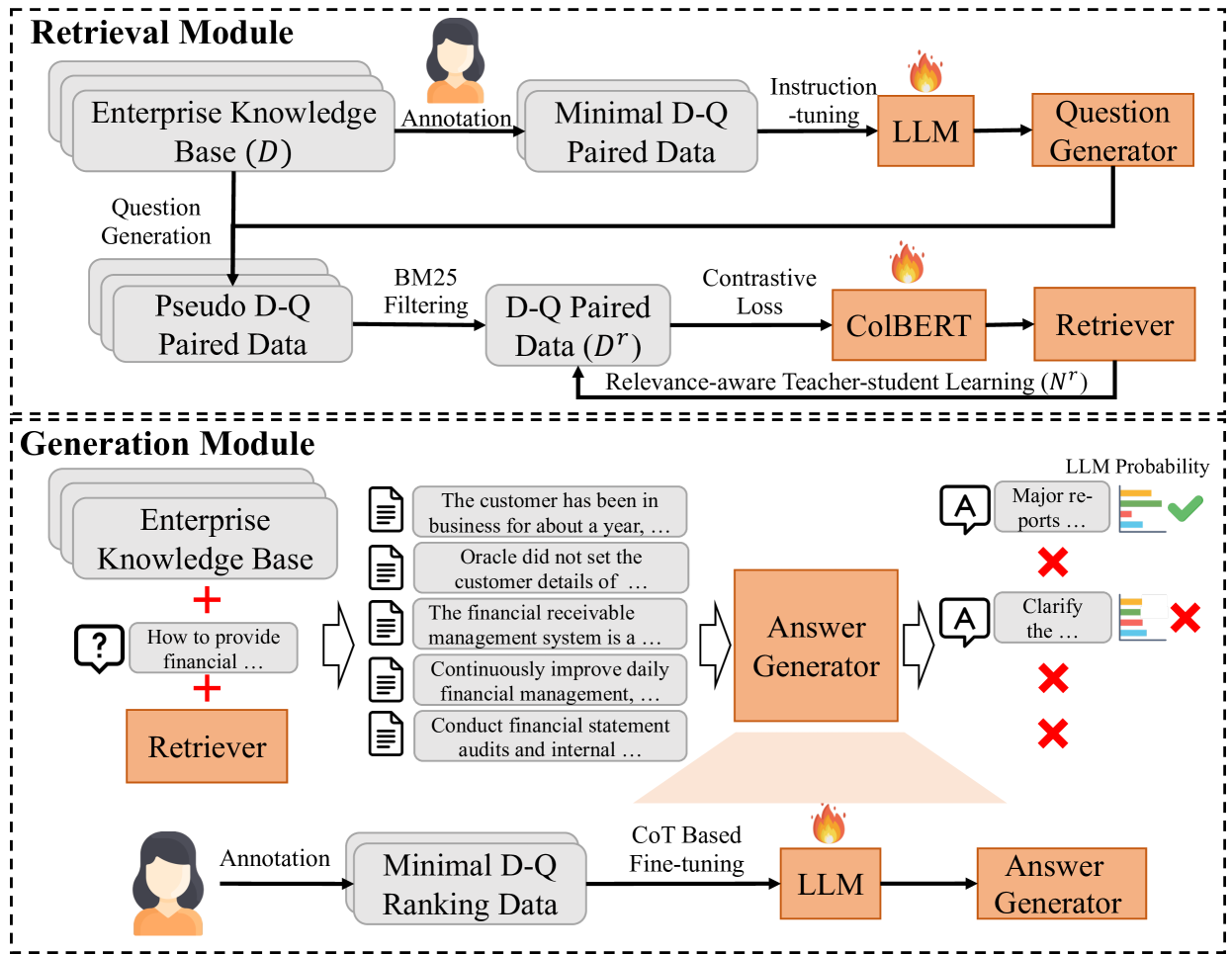
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024
LLoCO: Learning Long Contexts Offline
Sijun Tan, Xiuyu Li, Shishir Patil, Ziyang Wu, Tianjun Zhang, Kurt Keutzer, Joseph E. Gonzalez, Raluca Ada Popa
0
0
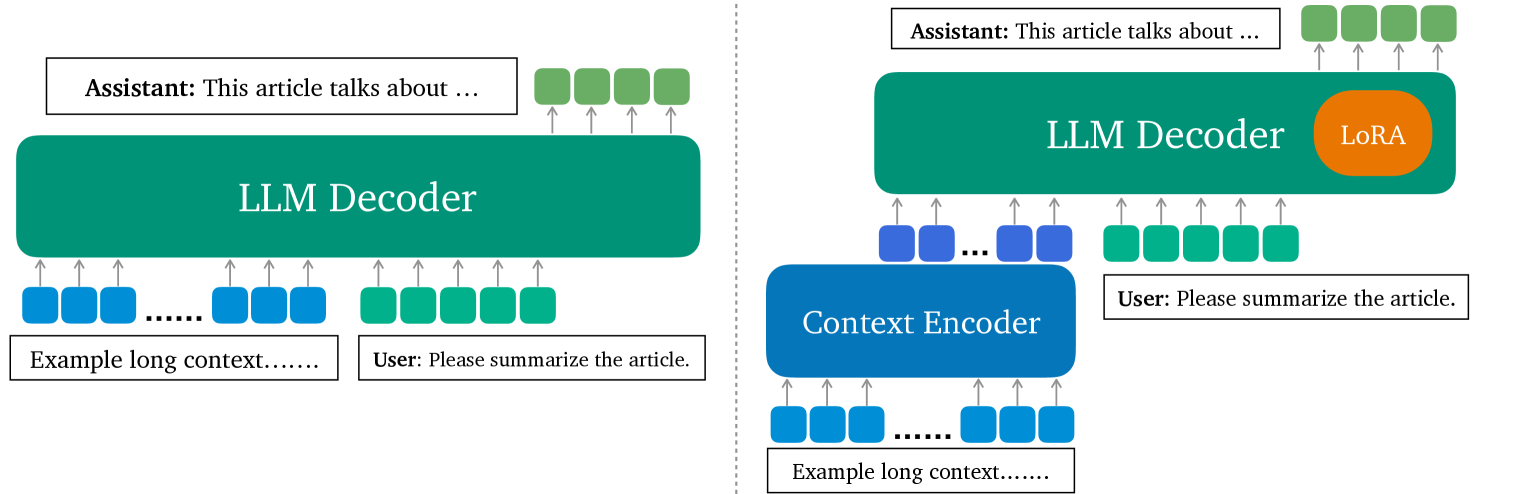
Processing long contexts remains a challenge for large language models (LLMs) due to the quadratic computational and memory overhead of the self-attention mechanism and the substantial KV cache sizes during generation. We propose a novel approach to address this problem by learning contexts offline through context compression and in-domain parameter-efficient finetuning. Our method enables an LLM to create a concise representation of the original context and efficiently retrieve relevant information to answer questions accurately. We introduce LLoCO, a technique that combines context compression, retrieval, and parameter-efficient finetuning using LoRA. Our approach extends the effective context window of a 4k token LLaMA2-7B model to handle up to 128k tokens. We evaluate our approach on several long-context question-answering datasets, demonstrating that LLoCO significantly outperforms in-context learning while using $30times$ fewer tokens during inference. LLoCO achieves up to $7.62times$ speed-up and substantially reduces the cost of long document question answering, making it a promising solution for efficient long context processing. Our code is publicly available at https://github.com/jeffreysijuntan/lloco.
4/12/2024