LLoCO: Learning Long Contexts Offline
2404.07979
0
0
Abstract
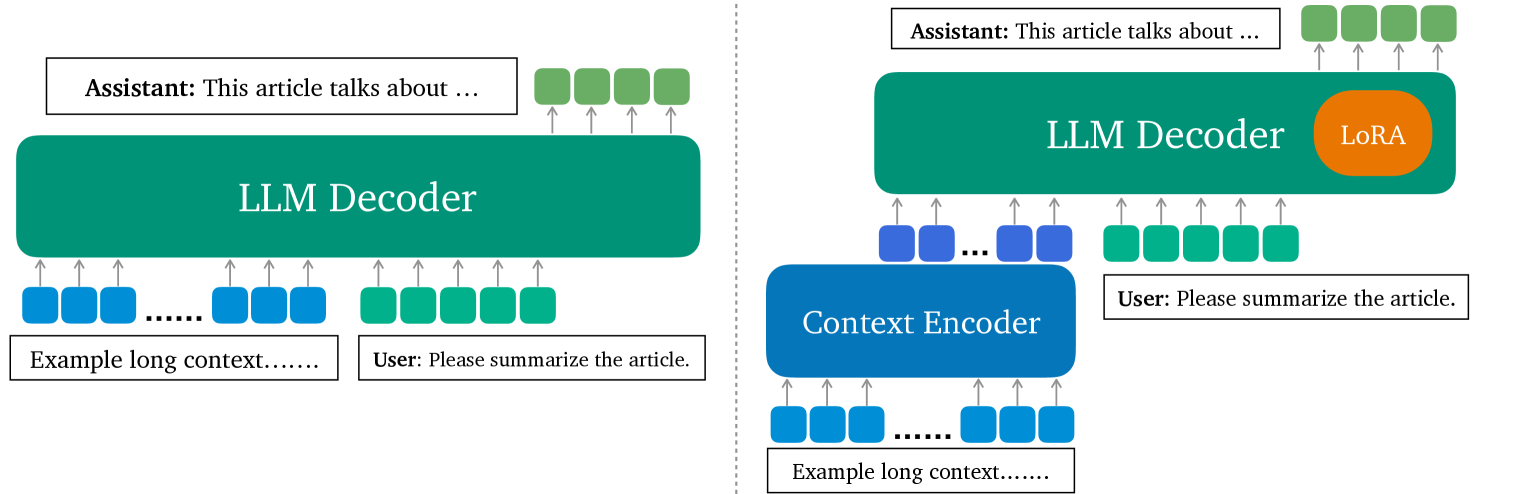
Processing long contexts remains a challenge for large language models (LLMs) due to the quadratic computational and memory overhead of the self-attention mechanism and the substantial KV cache sizes during generation. We propose a novel approach to address this problem by learning contexts offline through context compression and in-domain parameter-efficient finetuning. Our method enables an LLM to create a concise representation of the original context and efficiently retrieve relevant information to answer questions accurately. We introduce LLoCO, a technique that combines context compression, retrieval, and parameter-efficient finetuning using LoRA. Our approach extends the effective context window of a 4k token LLaMA2-7B model to handle up to 128k tokens. We evaluate our approach on several long-context question-answering datasets, demonstrating that LLoCO significantly outperforms in-context learning while using $30times$ fewer tokens during inference. LLoCO achieves up to $7.62times$ speed-up and substantially reduces the cost of long document question answering, making it a promising solution for efficient long context processing. Our code is publicly available at https://github.com/jeffreysijuntan/lloco.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces LLoCO, a novel approach for training large language models (LLMs) to better handle long-context tasks.
- LLMs often struggle with processing long, coherent text due to the limitations of their training data and architectural design.
- LLoCO aims to improve LLM performance on long-context tasks by training them offline on longer sequences, without requiring changes to the model architecture.
Plain English Explanation
LLoCO: Learning Long Contexts Offline is a technique that helps large language models (LLMs) get better at understanding and processing long pieces of text. LLMs are powerful AI models that can generate human-like text, answer questions, and perform other language-related tasks. However, they often struggle when dealing with long, coherent passages of text, because the data they were trained on typically consisted of shorter snippets.
The researchers behind LLoCO developed a way to train LLMs on longer sequences of text, without having to change the model's underlying architecture. This "offline" training approach allows the LLM to learn how to better handle and make sense of extended pieces of text, which can be useful for improving retrieval-augmented question answering, processing infinite context, and adapting LLMs for efficient context processing. By making large language models better with supervised knowledge, LLoCO aims to unlock the full potential of these powerful AI systems for tasks that require understanding long, complex text.
Technical Explanation
LLoCO: Learning Long Contexts Offline proposes a novel training approach to improve the ability of large language models (LLMs) to process long, coherent text. The authors observe that LLMs often struggle with long-context tasks due to the limitations of their training data and architectural design, which are typically optimized for shorter input sequences.
To address this, the researchers developed LLoCO, a two-stage training process that first pretrains the LLM on longer input sequences offline, before fine-tuning it on the target task. The offline pretraining stage uses a custom dataset of longer passages, allowing the model to learn how to effectively handle and understand extended pieces of text. This is followed by fine-tuning on the specific task, leveraging the improved long-context capabilities acquired during the pretraining stage.
The authors evaluate LLoCO on a range of long-context tasks, including retrieval-augmented question answering, processing infinite context, and efficient context processing. Their results demonstrate that LLoCO significantly outperforms standard fine-tuning approaches, particularly on tasks that require a deep understanding of long, coherent text. The authors also show that the performance gains from LLoCO can be further enhanced by incorporating supervised knowledge into large language models.
Critical Analysis
The LLoCO approach presents a promising solution to the long-standing challenge of enabling LLMs to effectively process long-context information. By pretraining the models on longer sequences of text, the researchers have shown that LLMs can acquire the necessary skills to handle extended passages, which is a crucial capability for many real-world applications.
However, the paper does not address the potential limitations or caveats of the LLoCO approach. For example, it is unclear how the offline pretraining stage affects the model's performance on shorter tasks, or how the approach scales to even longer contexts beyond the tested limits. Additionally, the authors do not discuss the computational and resource requirements of the two-stage training process, which could be a practical concern for some users.
Further research could explore ways to seamlessly integrate the long-context learning capabilities into the core LLM architecture, rather than relying on a separate pretraining stage. This could lead to more efficient and robust models that can handle a wide range of context lengths without sacrificing performance on shorter tasks.
Conclusion
LLoCO: Learning Long Contexts Offline presents a novel approach to improving the ability of large language models to process long, coherent text. By pretraining the models on longer sequences of text in an offline stage, the researchers have shown that LLMs can acquire the necessary skills to handle extended passages, significantly outperforming standard fine-tuning approaches on long-context tasks.
This work represents an important step forward in addressing the limitations of LLMs when it comes to understanding and reasoning about long-form text, which is crucial for many real-world applications, such as retrieval-augmented question answering, processing infinite context, and efficient context processing. By incorporating supervised knowledge into large language models, the researchers have further demonstrated the potential of LLoCO to unlock the full capabilities of these powerful AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Long-context LLMs Struggle with Long In-context Learning
Tianle Li, Ge Zhang, Quy Duc Do, Xiang Yue, Wenhu Chen
0
0
Large Language Models (LLMs) have made significant strides in handling long sequences exceeding 32K tokens. However, their performance evaluation has largely been confined to metrics like perplexity and synthetic tasks, which may not fully capture their abilities in more nuanced, real-world scenarios. This study introduces a specialized benchmark (LongICLBench) focusing on long in-context learning within the realm of extreme-label classification. We meticulously selected six datasets with a label range spanning 28 to 174 classes covering different input (few-shot demonstration) lengths from 2K to 50K tokens. Our benchmark requires LLMs to comprehend the entire input to recognize the massive label spaces to make correct predictions. We evaluate 13 long-context LLMs on our benchmarks. We find that the long-context LLMs perform relatively well on less challenging tasks with shorter demonstration lengths by effectively utilizing the long context window. However, on the most challenging task Discovery with 174 labels, all the LLMs struggle to understand the task definition, thus reaching a performance close to zero. This suggests a notable gap in current LLM capabilities for processing and understanding long, context-rich sequences. Further analysis revealed a tendency among models to favor predictions for labels presented toward the end of the sequence. Their ability to reason over multiple pieces in the long sequence is yet to be improved. Our study reveals that long context understanding and reasoning is still a challenging task for the existing LLMs. We believe LongICLBench could serve as a more realistic evaluation for the future long-context LLMs.
4/5/2024
⛏️
Extending Llama-3's Context Ten-Fold Overnight
Peitian Zhang, Ninglu Shao, Zheng Liu, Shitao Xiao, Hongjin Qian, Qiwei Ye, Zhicheng Dou
0
0
We extend the context length of Llama-3-8B-Instruct from 8K to 80K via QLoRA fine-tuning. The entire training cycle is super efficient, which takes 8 hours on one 8xA800 (80G) GPU machine. The resulted model exhibits superior performances across a broad range of evaluation tasks, such as NIHS, topic retrieval, and long-context language understanding; meanwhile, it also well preserves the original capability over short contexts. The dramatic context extension is mainly attributed to merely 3.5K synthetic training samples generated by GPT-4 , which indicates the LLMs' inherent (yet largely underestimated) potential to extend its original context length. In fact, the context length could be extended far beyond 80K with more computation resources. Therefore, the team will publicly release the entire resources (including data, model, data generation pipeline, training code) so as to facilitate the future research from the community: url{https://github.com/FlagOpen/FlagEmbedding}.
5/1/2024
Hierarchical Context Merging: Better Long Context Understanding for Pre-trained LLMs
Woomin Song, Seunghyuk Oh, Sangwoo Mo, Jaehyung Kim, Sukmin Yun, Jung-Woo Ha, Jinwoo Shin
0
0
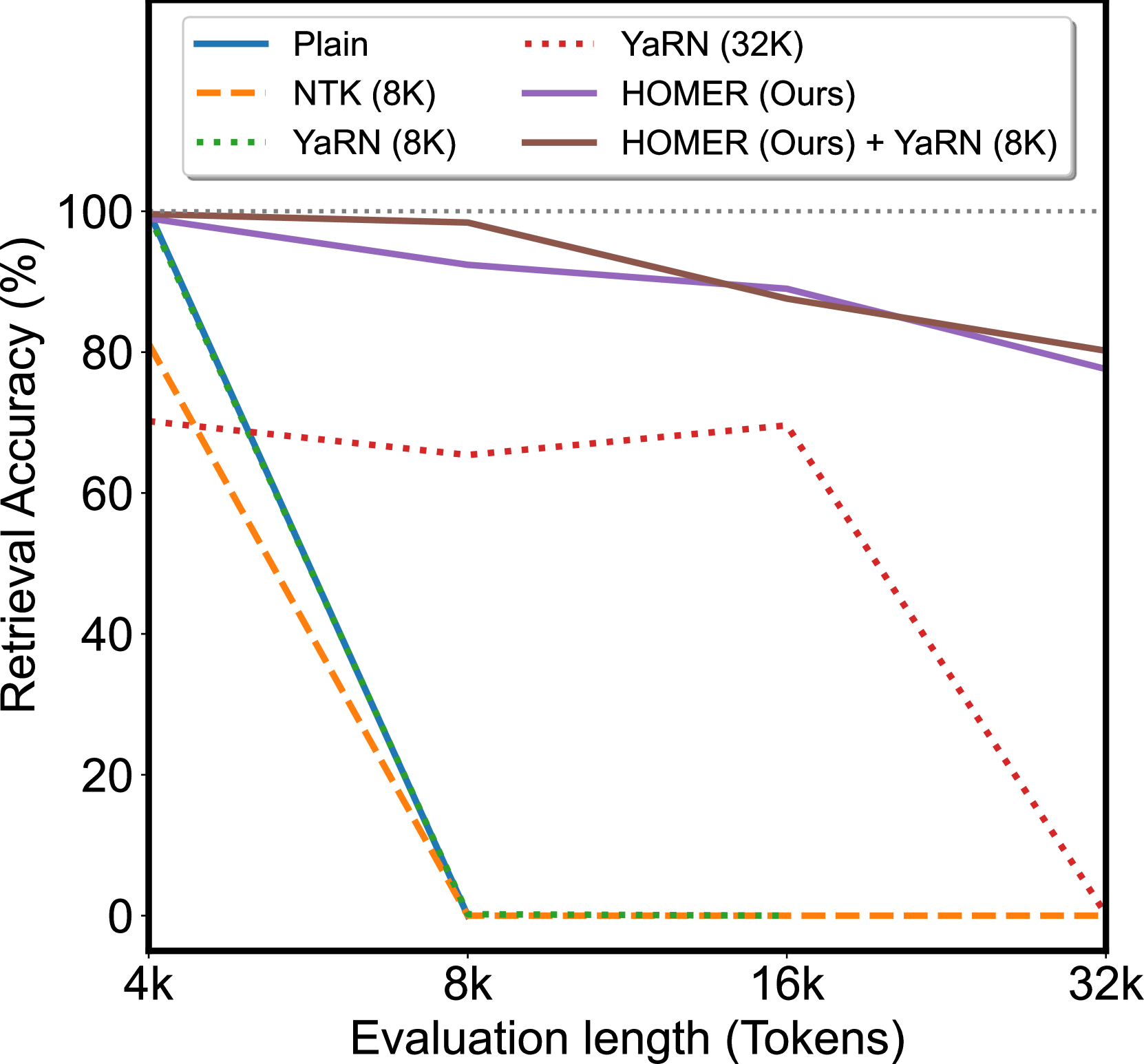
Large language models (LLMs) have shown remarkable performance in various natural language processing tasks. However, a primary constraint they face is the context limit, i.e., the maximum number of tokens they can process. Previous works have explored architectural changes and modifications in positional encoding to relax the constraint, but they often require expensive training or do not address the computational demands of self-attention. In this paper, we present Hierarchical cOntext MERging (HOMER), a new training-free scheme designed to overcome the limitations. HOMER uses a divide-and-conquer algorithm, dividing long inputs into manageable chunks. Each chunk is then processed collectively, employing a hierarchical strategy that merges adjacent chunks at progressive transformer layers. A token reduction technique precedes each merging, ensuring memory usage efficiency. We also propose an optimized computational order reducing the memory requirement to logarithmically scale with respect to input length, making it especially favorable for environments with tight memory restrictions. Our experiments demonstrate the proposed method's superior performance and memory efficiency, enabling the broader use of LLMs in contexts requiring extended context. Code is available at https://github.com/alinlab/HOMER.
4/17/2024
💬
In-context Autoencoder for Context Compression in a Large Language Model
Tao Ge, Jing Hu, Lei Wang, Xun Wang, Si-Qing Chen, Furu Wei
0
0
We propose the In-context Autoencoder (ICAE), leveraging the power of a large language model (LLM) to compress a long context into short compact memory slots that can be directly conditioned on by the LLM for various purposes. ICAE is first pretrained using both autoencoding and language modeling objectives on massive text data, enabling it to generate memory slots that accurately and comprehensively represent the original context. Then, it is fine-tuned on instruction data for producing desirable responses to various prompts. Experiments demonstrate that our lightweight ICAE, introducing about 1% additional parameters, effectively achieves $4times$ context compression based on Llama, offering advantages in both improved latency and GPU memory cost during inference, and showing an interesting insight in memorization as well as potential for scalability. These promising results imply a novel perspective on the connection between working memory in cognitive science and representation learning in LLMs, revealing ICAE's significant implications in addressing the long context problem and suggesting further research in LLM context management. Our data, code and models are available at https://github.com/getao/icae.
5/10/2024