Improving Self-supervised Pre-training using Accent-Specific Codebooks

0

Sign in to get full access
Overview
- This paper presents a new approach for improving self-supervised pre-training of speech recognition models by using accent-specific codebooks.
- The key idea is to create separate codebooks for different accents during the pre-training stage, which helps the model better capture the unique acoustic characteristics of each accent.
- This leads to improved performance on accented speech recognition tasks compared to existing self-supervised pre-training methods.
Plain English Explanation
The research paper discusses a way to make speech recognition models better at understanding different accents. Accent-specific codebooks are created during the initial training phase, which allows the model to learn the distinctive features of each accent.
This is an important problem because speech recognition systems often struggle with accented speech, which can be a barrier for many users. By incorporating accent-specific information into the pre-training process, the model becomes more adept at recognizing speech with diverse accents.
The key insight is that rather than using a single, generic codebook to represent all speech, creating separate codebooks for different accents enables the model to better capture the nuanced acoustic patterns associated with each accent. This leads to improved performance on accented speech recognition tasks compared to previous self-supervised pre-training approaches.
Technical Explanation
The paper proposes a novel self-supervised pre-training method that leverages accent-specific codebooks to improve the model's ability to handle accented speech.
The pre-training process involves two key steps:
-
Accent Identification: The first step is to identify the accent of each training utterance using a pre-trained accent classifier. This allows the model to associate each sample with its corresponding accent.
-
Accent-Specific Codebook Learning: Next, the model learns separate codebooks for each accent during the pre-training stage. This enables the capture of accent-specific acoustic representations that can be more effectively leveraged for downstream accented speech recognition tasks.
The authors evaluate their approach on several accented speech recognition benchmarks and demonstrate significant improvements over existing self-supervised pre-training methods. The accent-specific codebooks help the model better understand the unique characteristics of each accent, leading to more accurate speech recognition performance.
Critical Analysis
The paper presents a well-designed and thorough study, with a clear motivation and a novel technical approach. The use of accent-specific codebooks is a clever way to incorporate accent information into the pre-training process, which is a common challenge in speech recognition.
However, one potential limitation is the reliance on a pre-trained accent classifier to identify the accents of the training samples. If the accent classifier is not accurate, it could introduce noise into the codebook learning process. The authors do not provide a detailed analysis of the performance of the accent classifier used in their experiments.
Additionally, the paper does not explore the scalability of the approach to a large number of accents. As the number of accents increases, the complexity of the pre-training process may grow, and the authors could consider more efficient or automated methods for handling a diverse range of accents.
Overall, the paper presents an interesting and promising approach to improving self-supervised pre-training for accented speech recognition. The findings could have valuable implications for developing more inclusive and accessible speech-based technologies.
Conclusion
This research paper introduces a novel self-supervised pre-training method that leverages accent-specific codebooks to improve the performance of speech recognition models on accented speech. By creating separate codebooks for different accents during the pre-training stage, the model can better capture the unique acoustic characteristics of each accent, leading to significant improvements on accented speech recognition tasks.
The findings of this work highlight the importance of addressing accent-related challenges in speech recognition and the potential of self-supervised learning to tackle this problem. The accent-specific codebook approach represents an important step towards developing more robust and inclusive speech recognition systems that can effectively handle diverse accents and linguistic variations.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Improving Self-supervised Pre-training using Accent-Specific Codebooks
Darshan Prabhu, Abhishek Gupta, Omkar Nitsure, Preethi Jyothi, Sriram Ganapathy
Speech accents present a serious challenge to the performance of state-of-the-art end-to-end Automatic Speech Recognition (ASR) systems. Even with self-supervised learning and pre-training of ASR models, accent invariance is seldom achieved. In this work, we propose an accent-aware adaptation technique for self-supervised learning that introduces a trainable set of accent-specific codebooks to the self-supervised architecture. These learnable codebooks enable the model to capture accent specific information during pre-training, that is further refined during ASR finetuning. On the Mozilla Common Voice dataset, our proposed approach outperforms all other accent-adaptation approaches on both seen and unseen English accents, with up to 9% relative reduction in word error rate (WER).
Read more7/8/2024
0
Clustering and Mining Accented Speech for Inclusive and Fair Speech Recognition
Jaeyoung Kim, Han Lu, Soheil Khorram, Anshuman Tripathi, Qian Zhang, Hasim Sak
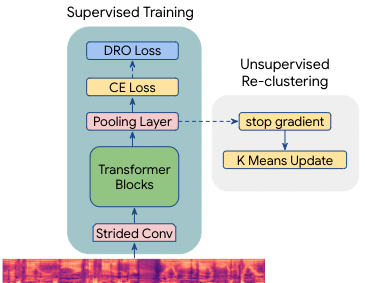
Modern automatic speech recognition (ASR) systems are typically trained on more than tens of thousands hours of speech data, which is one of the main factors for their great success. However, the distribution of such data is typically biased towards common accents or typical speech patterns. As a result, those systems often poorly perform on atypical accented speech. In this paper, we present accent clustering and mining schemes for fair speech recognition systems which can perform equally well on under-represented accented speech. For accent recognition, we applied three schemes to overcome limited size of supervised accent data: supervised or unsupervised pre-training, distributionally robust optimization (DRO) and unsupervised clustering. Three schemes can significantly improve the accent recognition model especially for unbalanced and small accented speech. Fine-tuning ASR on the mined Indian accent speech using the proposed supervised or unsupervised clustering schemes showed 10.0% and 5.3% relative improvements compared to fine-tuning on the randomly sampled speech, respectively.
Read more8/6/2024

0
Improving Accented Speech Recognition using Data Augmentation based on Unsupervised Text-to-Speech Synthesis
Cong-Thanh Do, Shuhei Imai, Rama Doddipatla, Thomas Hain
This paper investigates the use of unsupervised text-to-speech synthesis (TTS) as a data augmentation method to improve accented speech recognition. TTS systems are trained with a small amount of accented speech training data and their pseudo-labels rather than manual transcriptions, and hence unsupervised. This approach enables the use of accented speech data without manual transcriptions to perform data augmentation for accented speech recognition. Synthetic accented speech data, generated from text prompts by using the TTS systems, are then combined with available non-accented speech data to train automatic speech recognition (ASR) systems. ASR experiments are performed in a self-supervised learning framework using a Wav2vec2.0 model which was pre-trained on large amount of unsupervised accented speech data. The accented speech data for training the unsupervised TTS are read speech, selected from L2-ARCTIC and British Isles corpora, while spontaneous conversational speech from the Edinburgh international accents of English corpus are used as the evaluation data. Experimental results show that Wav2vec2.0 models which are fine-tuned to downstream ASR task with synthetic accented speech data, generated by the unsupervised TTS, yield up to 6.1% relative word error rate reductions compared to a Wav2vec2.0 baseline which is fine-tuned with the non-accented speech data from Librispeech corpus.
Read more7/8/2024
🌿
0
Accented Text-to-Speech Synthesis with a Conditional Variational Autoencoder
Jan Melechovsky, Ambuj Mehrish, Berrak Sisman, Dorien Herremans
Accent plays a significant role in speech communication, influencing one's capability to understand as well as conveying a person's identity. This paper introduces a novel and efficient framework for accented Text-to-Speech (TTS) synthesis based on a Conditional Variational Autoencoder. It has the ability to synthesize a selected speaker's voice, which is converted to any desired target accent. Our thorough experiments validate the effectiveness of the proposed framework using both objective and subjective evaluations. The results also show remarkable performance in terms of the ability to manipulate accents in the synthesized speech and provide a promising avenue for future accented TTS research.
Read more6/4/2024