Improving Sequential Query Recommendation with Immediate User Feedback

0
📶
Sign in to get full access
Overview
- Proposes an algorithm for next query recommendation in interactive data exploration settings
- Augments transformer-based causal language models with multi-armed bandit (MAB) framework to adapt to immediate user feedback
- Conducts large-scale experiments using log files from an online literature discovery service
- Demonstrates improved per-round regret compared to state-of-the-art transformer-based query recommendation models
Plain English Explanation
When people are exploring data, they often need to search for information by asking questions or queries. The current best algorithms for recommending the next query to ask are based on machine learning techniques that look at past user interactions. However, these approaches struggle to adapt quickly to the user's immediate feedback.
This paper proposes a new algorithm that combines powerful language models with a technique called multi-armed bandit (MAB). The MAB framework allows the algorithm to dynamically adjust its recommendations based on how the user responds to each suggestion in the moment.
The researchers tested this new approach using data from a popular online service that helps people discover literature. They found that their algorithm was able to outperform the existing state-of-the-art query recommendation models, providing better suggestions that were more tailored to the user's needs and interests.
Technical Explanation
The authors propose augmenting transformer-based causal language models for query recommendations with a multi-armed bandit (MAB) framework. This allows the model to adapt to immediate user feedback, in contrast to existing sequence-to-sequence approaches that rely solely on historical interaction data.
The core idea is to use the MAB framework to dynamically select the most promising query recommendation from the language model's output distribution. This is achieved by treating each potential query recommendation as an "arm" in the MAB problem, and updating their corresponding expected rewards based on user feedback.
The authors conduct a large-scale experimental evaluation using log files from a popular online literature discovery service. They demonstrate that their algorithm, which they call Exp3-SS, substantially improves the per-round regret compared to state-of-the-art transformer-based query recommendation models that do not leverage immediate user feedback.
Critical Analysis
The paper provides a novel approach to query recommendation that addresses an important limitation of existing techniques - their inability to quickly adapt to immediate user feedback. By combining powerful language models with a multi-armed bandit framework, the proposed Exp3-SS algorithm is able to provide more personalized and relevant query recommendations.
However, the paper does not discuss potential limitations or caveats of the approach. For example, it is unclear how well the algorithm would perform in domains with sparser or noisier user interaction data, or how it would scale to very large recommendation spaces. Additionally, the authors do not explore potential biases or fairness issues that could arise from the MAB framework's focus on maximizing short-term rewards.
Further research could investigate the robustness and generalizability of the Exp3-SS algorithm, as well as its implications for user privacy and algorithmic transparency. Nonetheless, this paper represents an important step forward in improving the temporal awareness of language models for sequential recommendation tasks.
Conclusion
This paper proposes a novel algorithm for next query recommendation that combines the strengths of transformer-based language models and multi-armed bandit techniques. By adapting to immediate user feedback, the Exp3-SS algorithm is able to outperform state-of-the-art approaches that rely solely on historical interaction data.
The research has important implications for interactive data exploration and query recommendation systems, potentially enabling more personalized and effective information gathering. The authors' findings also suggest promising avenues for further research on enhancing the temporal awareness and adaptability of language models in sequential recommendation tasks.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📶
0
Improving Sequential Query Recommendation with Immediate User Feedback
Shameem A Puthiya Parambath, Christos Anagnostopoulos, Roderick Murray-Smith
We propose an algorithm for next query recommendation in interactive data exploration settings, like knowledge discovery for information gathering. The state-of-the-art query recommendation algorithms are based on sequence-to-sequence learning approaches that exploit historical interaction data. Due to the supervision involved in the learning process, such approaches fail to adapt to immediate user feedback. We propose to augment the transformer-based causal language models for query recommendations to adapt to the immediate user feedback using multi-armed bandit (MAB) framework. We conduct a large-scale experimental study using log files from a popular online literature discovery service and demonstrate that our algorithm improves the per-round regret substantially, with respect to the state-of-the-art transformer-based query recommendation models, which do not make use of immediate user feedback. Our data model and source code are available at https://github.com/shampp/exp3_ss
Read more7/8/2024
0
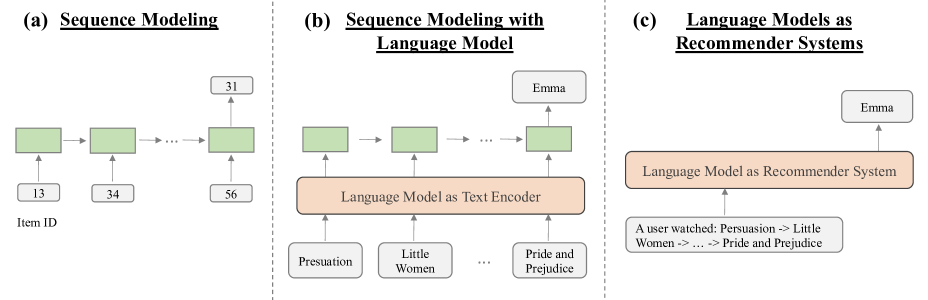
Reformulating Sequential Recommendation: Learning Dynamic User Interest with Content-enriched Language Modeling
Junzhe Jiang, Shang Qu, Mingyue Cheng, Qi Liu, Zhiding Liu, Hao Zhang, Rujiao Zhang, Kai Zhang, Rui Li, Jiatong Li, Min Gao
Recommender systems are indispensable in the realm of online applications, and sequential recommendation has enjoyed considerable prevalence due to its capacity to encapsulate the dynamic shifts in user interests. However, previous sequential modeling methods still have limitations in capturing contextual information. The primary reason is the lack of understanding of domain-specific knowledge and item-related textual content. Fortunately, the emergence of powerful language models has unlocked the potential to incorporate extensive world knowledge into recommendation algorithms, enabling them to go beyond simple item attributes and truly understand the world surrounding user preferences. To achieve this, we propose LANCER, which leverages the semantic understanding capabilities of pre-trained language models to generate personalized recommendations. Our approach bridges the gap between language models and recommender systems, resulting in more human-like recommendations. We demonstrate the effectiveness of our approach through a series of experiments conducted on multiple benchmark datasets, showing promising results and providing valuable insights into the influence of our model on sequential recommendation tasks. Furthermore, our experimental codes are publicly available at https://github.com/Gnimixy/lancer.
Read more4/16/2024
0
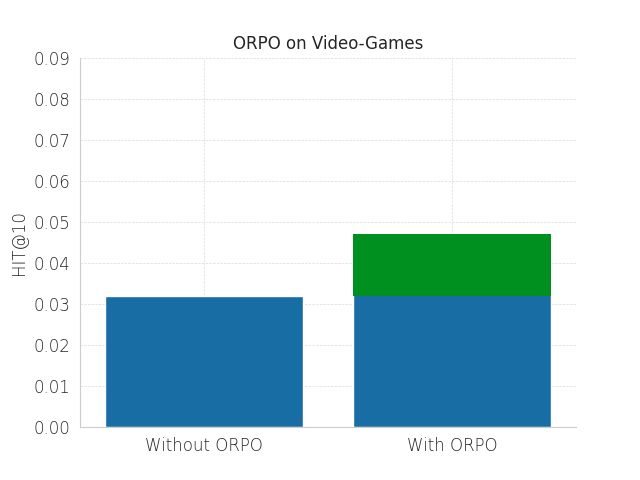
Exploring Applications of State Space Models and Advanced Training Techniques in Sequential Recommendations: A Comparative Study on Efficiency and Performance
Mark Obozov, Makar Baderko, Stepan Kulibaba, Nikolay Kutuzov, Alexander Gasnikov
Recommender systems aim to estimate the dynamically changing user preferences and sequential dependencies between historical user behaviour and metadata. Although transformer-based models have proven to be effective in sequential recommendations, their state growth is proportional to the length of the sequence that is being processed, which makes them expensive in terms of memory and inference costs. Our research focused on three promising directions in sequential recommendations: enhancing speed through the use of State Space Models (SSM), as they can achieve SOTA results in the sequential recommendations domain with lower latency, memory, and inference costs, as proposed by arXiv:2403.03900 improving the quality of recommendations with Large Language Models (LLMs) via Monolithic Preference Optimization without Reference Model (ORPO); and implementing adaptive batch- and step-size algorithms to reduce costs and accelerate training processes.
Read more8/13/2024
0
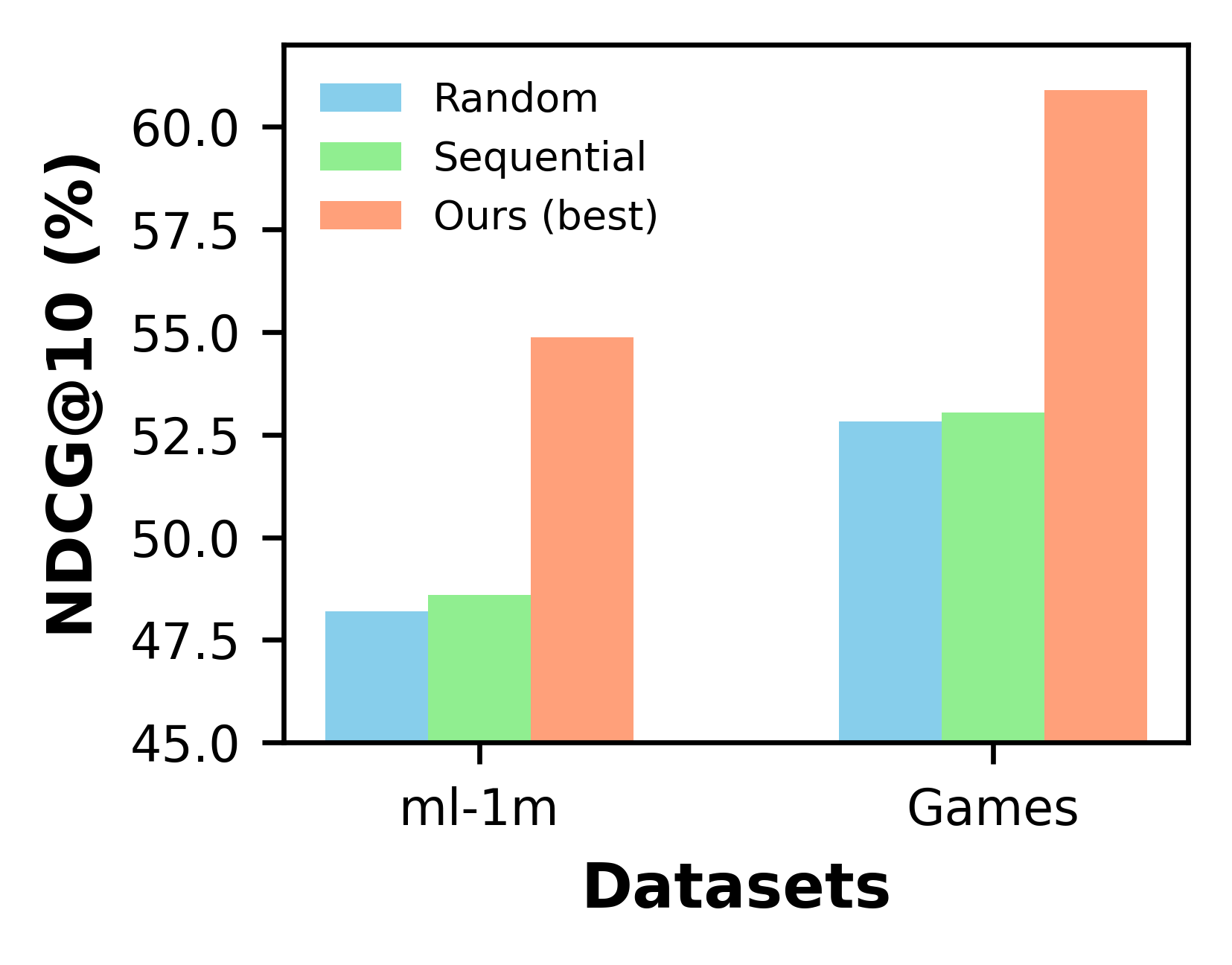
Improve Temporal Awareness of LLMs for Sequential Recommendation
Zhendong Chu, Zichao Wang, Ruiyi Zhang, Yangfeng Ji, Hongning Wang, Tong Sun
Large language models (LLMs) have demonstrated impressive zero-shot abilities in solving a wide range of general-purpose tasks. However, it is empirically found that LLMs fall short in recognizing and utilizing temporal information, rendering poor performance in tasks that require an understanding of sequential data, such as sequential recommendation. In this paper, we aim to improve temporal awareness of LLMs by designing a principled prompting framework inspired by human cognitive processes. Specifically, we propose three prompting strategies to exploit temporal information within historical interactions for LLM-based sequential recommendation. Besides, we emulate divergent thinking by aggregating LLM ranking results derived from these strategies. Evaluations on MovieLens-1M and Amazon Review datasets indicate that our proposed method significantly enhances the zero-shot capabilities of LLMs in sequential recommendation tasks.
Read more5/7/2024