Improve Temporal Awareness of LLMs for Sequential Recommendation
2405.02778
0
0
Abstract
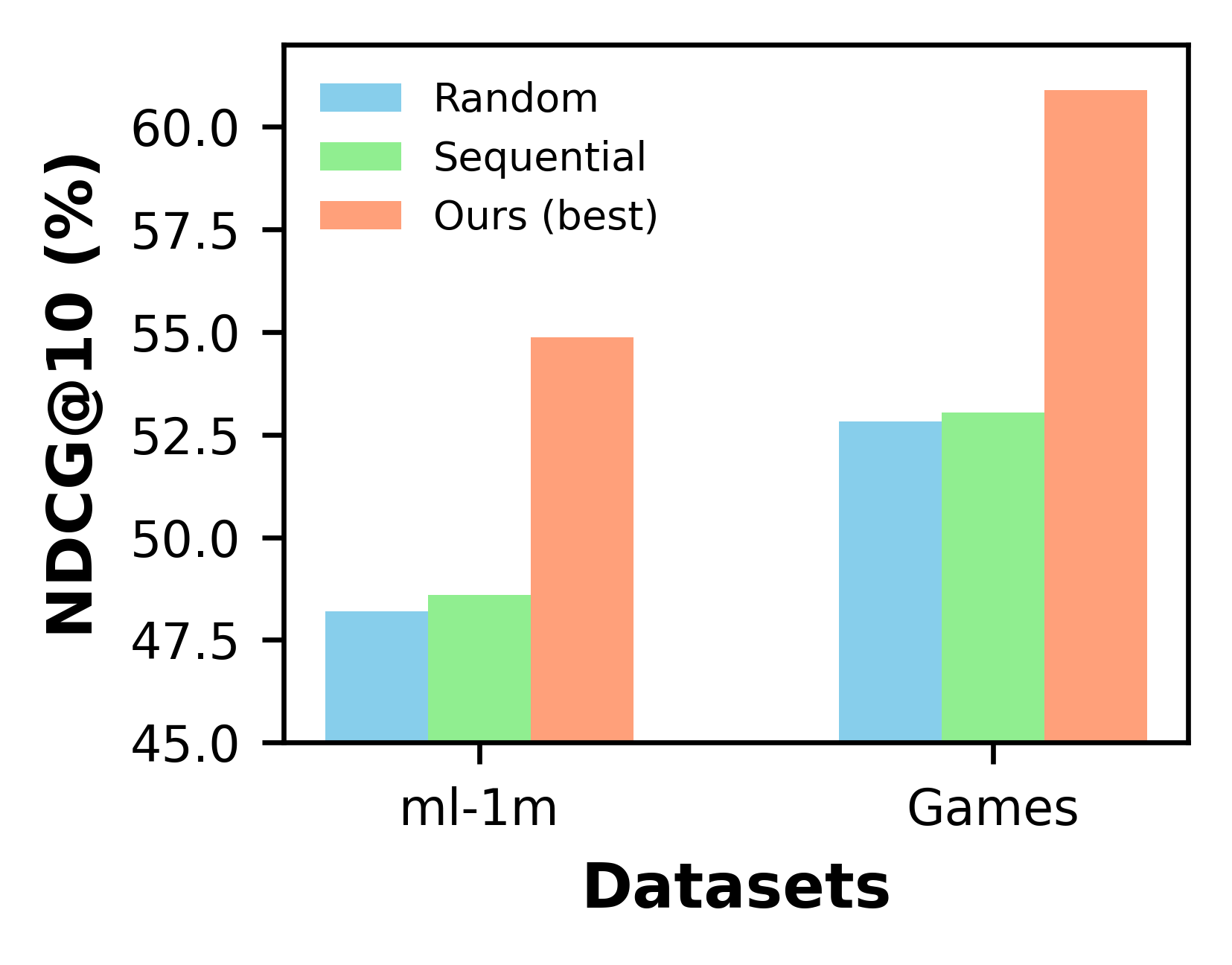
Large language models (LLMs) have demonstrated impressive zero-shot abilities in solving a wide range of general-purpose tasks. However, it is empirically found that LLMs fall short in recognizing and utilizing temporal information, rendering poor performance in tasks that require an understanding of sequential data, such as sequential recommendation. In this paper, we aim to improve temporal awareness of LLMs by designing a principled prompting framework inspired by human cognitive processes. Specifically, we propose three prompting strategies to exploit temporal information within historical interactions for LLM-based sequential recommendation. Besides, we emulate divergent thinking by aggregating LLM ranking results derived from these strategies. Evaluations on MovieLens-1M and Amazon Review datasets indicate that our proposed method significantly enhances the zero-shot capabilities of LLMs in sequential recommendation tasks.
Create account to get full access
Overview
- This paper explores how to improve the temporal awareness of large language models (LLMs) for sequential recommendation tasks.
- The authors propose a novel approach called Temporal-aware Prompt Tuning (TPT) that enhances the ability of LLMs to understand and leverage temporal information in sequential recommendation.
- The paper presents experiments on several benchmark datasets, demonstrating that TPT outperforms state-of-the-art methods for sequential recommendation.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have shown impressive performance on a variety of tasks, including personalized recommendation and conversational movie recommendations. However, these models can struggle to fully capture the temporal dynamics of user behavior when making sequential recommendations.
The authors of this paper recognized this limitation and developed a new technique called Temporal-aware Prompt Tuning (TPT) to help LLMs better understand and utilize temporal information. The key idea is to provide the LLM with additional prompts and cues that explicitly highlight the temporal aspects of the recommendation problem, such as the order and timing of user actions.
By incorporating these temporal signals, the LLM can learn to make more informed and personalized recommendations, taking into account how a user's preferences and behaviors evolve over time. The authors tested TPT on several benchmark datasets and showed that it outperforms other state-of-the-art methods for sequential recommendation tasks.
This research is important because it demonstrates how we can enhance the temporal reasoning capabilities of powerful LLMs, which could lead to significant improvements in real-world applications like personalized recommendations, conversational agents, and forecasting. By making LLMs more aware of temporal dynamics, we can unlock their potential to assess serendipity and deliver more personalized and engaging experiences for users.
Technical Explanation
The key contribution of this paper is the Temporal-aware Prompt Tuning (TPT) approach, which enhances the ability of LLMs to capture temporal information for sequential recommendation tasks.
The authors start by observing that traditional LLM-based recommendation models often struggle to fully leverage the temporal aspects of user behavior, such as the order and timing of user actions. To address this, they propose incorporating additional temporal prompts and signals into the LLM's input.
Specifically, TPT works by:
- Extracting temporal features from the user's interaction history, such as the time elapsed since the last interaction, the order of interactions, and the duration of each interaction.
- Encoding these temporal features into a set of prompts that are concatenated with the user's interaction history.
- Fine-tuning the LLM on this augmented input, allowing it to learn how to better leverage the temporal information for making personalized recommendations.
The authors evaluate TPT on several benchmark datasets for sequential recommendation, including Amazon, Foursquare, and Gowalla. They compare TPT against state-of-the-art methods such as CACL-Rec and THST, and demonstrate that TPT consistently outperforms these baselines in terms of recommendation accuracy and diversity.
The authors attribute TPT's success to its ability to effectively capture the temporal dynamics of user behavior, which allows the LLM to make more informed and personalized recommendations. This research suggests that incorporating explicit temporal awareness into LLMs can be a promising direction for enhancing their performance on sequential recommendation tasks.
Critical Analysis
The authors provide a thorough evaluation of TPT, demonstrating its effectiveness on several benchmark datasets. However, the paper also acknowledges some potential limitations and areas for further research.
One limitation is that the performance of TPT may be sensitive to the specific temporal features extracted and the way they are encoded into the prompts. The authors mention that further exploration of different temporal feature engineering techniques and prompt design strategies could lead to additional improvements.
Additionally, the paper does not extensively investigate the interpretability and explainability of TPT's recommendations. Understanding how the LLM is leveraging the temporal information to make its decisions could be valuable for improving trust and transparency in real-world applications.
Another area for future research is the potential integration of TPT with other LLM-based recommendation techniques, such as contrastive alignment or generative prompting. Combining temporal awareness with these other approaches could lead to even more powerful and versatile recommendation systems.
Overall, this paper presents a compelling and well-executed approach to enhancing the temporal reasoning capabilities of LLMs for sequential recommendation tasks. The authors have made a valuable contribution to the field, and their work suggests exciting avenues for further research and development.
Conclusion
This paper introduces Temporal-aware Prompt Tuning (TPT), a novel technique for improving the temporal awareness of large language models (LLMs) in the context of sequential recommendation. By incorporating explicit temporal signals and cues into the LLM's input, the authors demonstrate that TPT can outperform state-of-the-art methods on several benchmark datasets.
The key insight of this work is that LLMs, while powerful, can struggle to fully capture the temporal dynamics of user behavior when making personalized recommendations. By addressing this limitation, TPT opens up new possibilities for enhancing the performance and personalization capabilities of LLM-based recommender systems.
The research presented in this paper is an important step forward in the ongoing efforts to develop more temporally-aware and context-sensitive LLMs. As these models continue to advance, we can expect to see increasingly intelligent and engaging conversational agents, personalized recommendations, and forecasting capabilities that can assess serendipity and deliver more meaningful and personalized experiences for users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

SLMRec: Empowering Small Language Models for Sequential Recommendation
Wujiang Xu, Zujie Liang, Jiaojiao Han, Xuying Ning, Wenfang Lin, Linxun Chen, Feng Wei, Yongfeng Zhang
0
0
The sequential Recommendation (SR) task involves predicting the next item a user is likely to interact with, given their past interactions. The SR models examine the sequence of a user's actions to discern more complex behavioral patterns and temporal dynamics. Recent research demonstrates the great impact of LLMs on sequential recommendation systems, either viewing sequential recommendation as language modeling or serving as the backbone for user representation. Although these methods deliver outstanding performance, there is scant evidence of the necessity of a large language model and how large the language model is needed, especially in the sequential recommendation scene. Meanwhile, due to the huge size of LLMs, it is inefficient and impractical to apply a LLM-based model in real-world platforms that often need to process billions of traffic logs daily. In this paper, we explore the influence of LLMs' depth by conducting extensive experiments on large-scale industry datasets. Surprisingly, we discover that most intermediate layers of LLMs are redundant. Motivated by this insight, we empower small language models for SR, namely SLMRec, which adopt a simple yet effective knowledge distillation method. Moreover, SLMRec is orthogonal to other post-training efficiency techniques, such as quantization and pruning, so that they can be leveraged in combination. Comprehensive experimental results illustrate that the proposed SLMRec model attains the best performance using only 13% of the parameters found in LLM-based recommendation models, while simultaneously achieving up to 6.6x and 8.0x speedups in training and inference time costs, respectively.
5/29/2024
💬
LLM-Rec: Personalized Recommendation via Prompting Large Language Models
Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Qifan Wang, Si Zhang, Ren Chen, Christopher Leung, Jiajie Tang, Jiebo Luo
0
0
Text-based recommendation holds a wide range of practical applications due to its versatility, as textual descriptions can represent nearly any type of item. However, directly employing the original item descriptions may not yield optimal recommendation performance due to the lack of comprehensive information to align with user preferences. Recent advances in large language models (LLMs) have showcased their remarkable ability to harness commonsense knowledge and reasoning. In this study, we introduce a novel approach, coined LLM-Rec, which incorporates four distinct prompting strategies of text enrichment for improving personalized text-based recommendations. Our empirical experiments reveal that using LLM-augmented text significantly enhances recommendation quality. Even basic MLP (Multi-Layer Perceptron) models achieve comparable or even better results than complex content-based methods. Notably, the success of LLM-Rec lies in its prompting strategies, which effectively tap into the language model's comprehension of both general and specific item characteristics. This highlights the importance of employing diverse prompts and input augmentation techniques to boost the recommendation effectiveness of LLMs.
4/3/2024
💬
ReLLa: Retrieval-enhanced Large Language Models for Lifelong Sequential Behavior Comprehension in Recommendation
Jianghao Lin, Rong Shan, Chenxu Zhu, Kounianhua Du, Bo Chen, Shigang Quan, Ruiming Tang, Yong Yu, Weinan Zhang
0
0
With large language models (LLMs) achieving remarkable breakthroughs in natural language processing (NLP) domains, LLM-enhanced recommender systems have received much attention and have been actively explored currently. In this paper, we focus on adapting and empowering a pure large language model for zero-shot and few-shot recommendation tasks. First and foremost, we identify and formulate the lifelong sequential behavior incomprehension problem for LLMs in recommendation domains, i.e., LLMs fail to extract useful information from a textual context of long user behavior sequence, even if the length of context is far from reaching the context limitation of LLMs. To address such an issue and improve the recommendation performance of LLMs, we propose a novel framework, namely Retrieval-enhanced Large Language models (ReLLa) for recommendation tasks in both zero-shot and few-shot settings. For zero-shot recommendation, we perform semantic user behavior retrieval (SUBR) to improve the data quality of testing samples, which greatly reduces the difficulty for LLMs to extract the essential knowledge from user behavior sequences. As for few-shot recommendation, we further design retrieval-enhanced instruction tuning (ReiT) by adopting SUBR as a data augmentation technique for training samples. Specifically, we develop a mixed training dataset consisting of both the original data samples and their retrieval-enhanced counterparts. We conduct extensive experiments on three real-world public datasets to demonstrate the superiority of ReLLa compared with existing baseline models, as well as its capability for lifelong sequential behavior comprehension. To be highlighted, with only less than 10% training samples, few-shot ReLLa can outperform traditional CTR models that are trained on the entire training set (e.g., DCNv2, DIN, SIM). The code is available url{https://github.com/LaVieEnRose365/ReLLa}.
6/26/2024
⛏️
Evaluating LLMs at Evaluating Temporal Generalization
Chenghao Zhu, Nuo Chen, Yufei Gao, Benyou Wang
0
0
The rapid advancement of Large Language Models (LLMs) highlights the urgent need for evolving evaluation methodologies that keep pace with improvements in language comprehension and information processing. However, traditional benchmarks, which are often static, fail to capture the continually changing information landscape, leading to a disparity between the perceived and actual effectiveness of LLMs in ever-changing real-world scenarios. Furthermore, these benchmarks do not adequately measure the models' capabilities over a broader temporal range or their adaptability over time. We examine current LLMs in terms of temporal generalization and bias, revealing that various temporal biases emerge in both language likelihood and prognostic prediction. This serves as a caution for LLM practitioners to pay closer attention to mitigating temporal biases. Also, we propose an evaluation framework Freshbench for dynamically generating benchmarks from the most recent real-world prognostication prediction. Our code is available at https://github.com/FreedomIntelligence/FreshBench. The dataset will be released soon.
5/15/2024