Improving Text-To-Audio Models with Synthetic Captions
2406.15487
0
0
🤯
Abstract
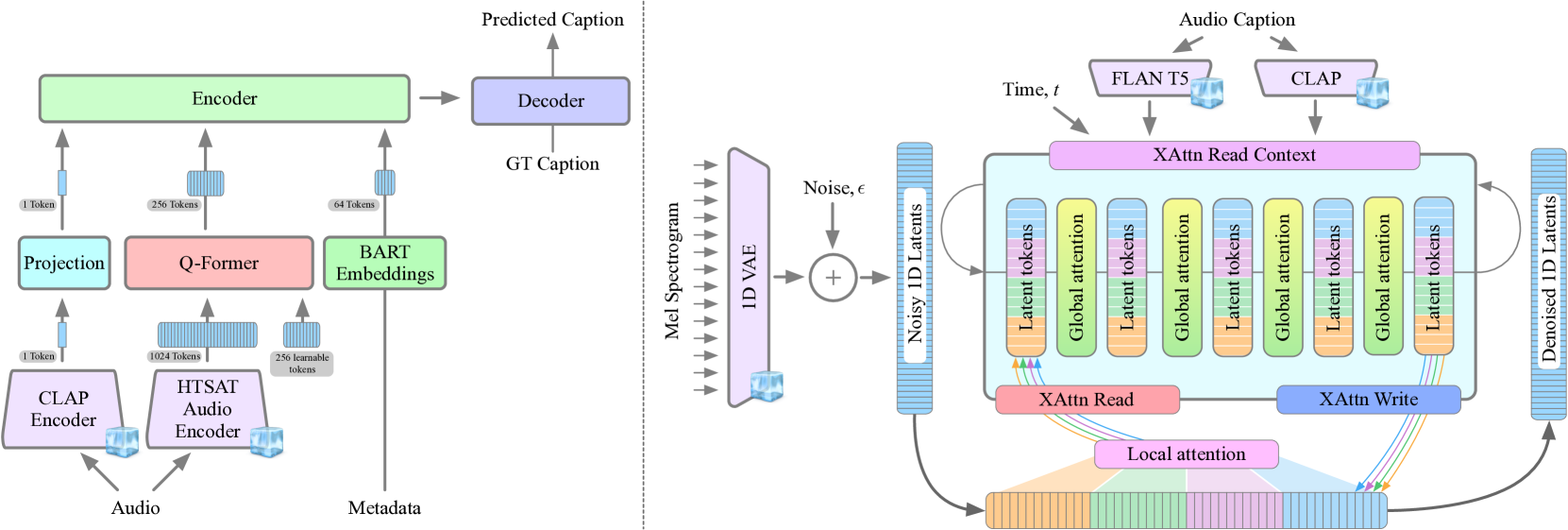
It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new textit{state-of-the-art}.
Create account to get full access
Overview
- Obtaining high-quality training data, especially captions, for text-to-audio models is a significant challenge.
- Prior methods have used text-only language models to improve captions, but these have limitations related to scale and coherence between audio and captions.
- This paper proposes an audio captioning pipeline that uses an audio language model to synthesize accurate and diverse captions for audio at scale.
- The authors leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named AF-AudioSet, and evaluate the benefit of pre-training text-to-audio models on these synthetic captions.
Plain English Explanation
Training high-quality text-to-audio models can be challenging because it's hard to get enough good-quality captions to use as training data. While previous methods have tried to improve captions by using language models trained on text-only data, these methods have limitations when it comes to generating captions that are well-connected to the audio.
In this paper, the researchers propose a new approach that uses an audio language model to generate accurate and diverse captions for audio samples at a large scale. They use this pipeline to create a new dataset called AF-AudioSet, which contains synthetic captions for the AudioSet dataset. The researchers then evaluate whether pre-training text-to-audio models on this synthetic data can improve the quality of audio generation.
Technical Explanation
The authors propose an audio captioning pipeline that leverages an audio language model to generate accurate and diverse captions for audio samples at scale. This pipeline is used to create a new dataset called AF-AudioSet, which contains synthetic captions for the AudioSet dataset.
The authors then evaluate the benefit of pre-training text-to-audio models on this synthetic data. Through systematic evaluations on AudioCaps and MusicCaps, they find that leveraging their pipeline and synthetic captions leads to significant improvements in audio generation quality, achieving a new state-of-the-art.
Critical Analysis
The paper presents a novel approach to addressing the challenge of obtaining high-quality training data for text-to-audio models. The use of an audio language model to generate synthetic captions is an interesting and promising solution. However, the authors acknowledge that their method may have limitations in terms of the coherence and realism of the generated captions compared to human-written ones.
Additionally, the paper does not provide a detailed analysis of the quality of the synthetic captions in the AF-AudioSet dataset. It would be helpful to understand how the generated captions compare to human-written ones in terms of metrics like relevance, coherence, and diversity.
Further research could also explore ways to improve the quality and realism of the synthetic captions, perhaps by incorporating additional techniques like contrastive learning or retrieval augmentation. Nonetheless, the overall approach presented in the paper represents a significant step forward in addressing the data challenge for text-to-audio models.
Conclusion
This paper introduces a novel audio captioning pipeline that leverages an audio language model to generate accurate and diverse captions for audio samples at scale. The authors use this pipeline to create a new dataset called AF-AudioSet and demonstrate that pre-training text-to-audio models on this synthetic data can lead to significant improvements in audio generation quality, achieving a new state-of-the-art. This research represents an important advancement in addressing the challenge of obtaining high-quality training data for text-to-audio models, with potential implications for a wide range of audio-related applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Taming Data and Transformers for Audio Generation
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Guha Balakrishnan, Sergey Tulyakov, Vicente Ordonez
0
0
Generating ambient sounds and effects is a challenging problem due to data scarcity and often insufficient caption quality, making it difficult to employ large-scale generative models for the task. In this work, we tackle the problem by introducing two new models. First, we propose AutoCap, a high-quality and efficient automatic audio captioning model. We show that by leveraging metadata available with the audio modality, we can substantially improve the quality of captions. AutoCap reaches CIDEr score of 83.2, marking a 3.2% improvement from the best available captioning model at four times faster inference speed. We then use AutoCap to caption clips from existing datasets, obtaining 761,000 audio clips with high-quality captions, forming the largest available audio-text dataset. Second, we propose GenAu, a scalable transformer-based audio generation architecture that we scale up to 1.25B parameters and train with our new dataset. When compared to state-of-the-art audio generators, GenAu obtains significant improvements of 15.7% in FAD score, 22.7% in IS, and 13.5% in CLAP score, indicating significantly improved quality of generated audio compared to previous works. This shows that the quality of data is often as important as its quantity. Besides, since AutoCap is fully automatic, new audio samples can be added to the training dataset, unlocking the training of even larger generative models for audio synthesis.
6/28/2024
Synthetic training set generation using text-to-audio models for environmental sound classification
Francesca Ronchini, Luca Comanducci, Fabio Antonacci
0
0
In the past few years, text-to-audio models have emerged as a significant advancement in automatic audio generation. Although they represent impressive technological progress, the effectiveness of their use in the development of audio applications remains uncertain. This paper aims to investigate these aspects, specifically focusing on the task of classification of environmental sounds. This study analyzes the performance of two different environmental classification systems when data generated from text-to-audio models is used for training. Two cases are considered: a) when the training dataset is augmented by data coming from two different text-to-audio models; and b) when the training dataset consists solely of synthetic audio generated. In both cases, the performance of the classification task is tested on real data. Results indicate that text-to-audio models are effective for dataset augmentation, whereas the performance of the models drops when relying on only generated audio.
6/11/2024
🔍
RECAP: Retrieval-Augmented Audio Captioning
Sreyan Ghosh, Sonal Kumar, Chandra Kiran Reddy Evuru, Ramani Duraiswami, Dinesh Manocha
0
0
We present RECAP (REtrieval-Augmented Audio CAPtioning), a novel and effective audio captioning system that generates captions conditioned on an input audio and other captions similar to the audio retrieved from a datastore. Additionally, our proposed method can transfer to any domain without the need for any additional fine-tuning. To generate a caption for an audio sample, we leverage an audio-text model CLAP to retrieve captions similar to it from a replaceable datastore, which are then used to construct a prompt. Next, we feed this prompt to a GPT-2 decoder and introduce cross-attention layers between the CLAP encoder and GPT-2 to condition the audio for caption generation. Experiments on two benchmark datasets, Clotho and AudioCaps, show that RECAP achieves competitive performance in in-domain settings and significant improvements in out-of-domain settings. Additionally, due to its capability to exploit a large text-captions-only datastore in a training-free fashion, RECAP shows unique capabilities of captioning novel audio events never seen during training and compositional audios with multiple events. To promote research in this space, we also release 150,000+ new weakly labeled captions for AudioSet, AudioCaps, and Clotho.
6/7/2024

Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding
Jizhong Liu, Gang Li, Junbo Zhang, Heinrich Dinkel, Yongqing Wang, Zhiyong Yan, Yujun Wang, Bin Wang
0
0
Automated audio captioning (AAC) is an audio-to-text task to describe audio contents in natural language. Recently, the advancements in large language models (LLMs), with improvements in training approaches for audio encoders, have opened up possibilities for improving AAC. Thus, we explore enhancing AAC from three aspects: 1) a pre-trained audio encoder via consistent ensemble distillation (CED) is used to improve the effectivity of acoustic tokens, with a querying transformer (Q-Former) bridging the modality gap to LLM and compress acoustic tokens; 2) we investigate the advantages of using a Llama 2 with 7B parameters as the decoder; 3) another pre-trained LLM corrects text errors caused by insufficient training data and annotation ambiguities. Both the audio encoder and text decoder are optimized by low-rank adaptation (LoRA). Experiments show that each of these enhancements is effective. Our method obtains a 33.0 SPIDEr-FL score, outperforming the winner of DCASE 2023 Task 6A.
6/26/2024