Taming Data and Transformers for Audio Generation

0
Sign in to get full access
Overview
- The paper "Taming Data and Transformers for Audio Generation" explores techniques to improve audio generation using transformers, a type of deep learning model.
- The authors focus on addressing challenges related to data and model complexity in audio generation tasks.
- They propose several strategies, including data filtering, model regularization, and novel model architectures, to enhance the performance and stability of transformer-based audio generation systems.
Plain English Explanation
Audio generation, the process of creating realistic-sounding audio from scratch, is a challenging task in artificial intelligence. Transformers, a powerful type of deep learning model, have shown promise in this area, but they can be complex and require large amounts of high-quality training data.
The researchers in this paper set out to find ways to "tame" transformers and the data they use, making audio generation more reliable and accessible. They tried several different techniques, including:
-
Data Filtering: Carefully selecting and cleaning the audio data used to train the transformers, to remove low-quality or irrelevant samples and improve the overall quality of the training data.
-
Model Regularization: Modifying the transformer models themselves to be more stable and less prone to overfitting, which can improve their ability to generalize to new, unseen audio samples.
-
Novel Model Architectures: Exploring new ways of structuring the transformer models, beyond the standard designs, to better capture the unique characteristics of audio data.
By applying these strategies, the researchers were able to develop transformer-based audio generation systems that performed better, required less training data, and were more robust to the challenges often encountered in this field. Their work helps to make high-quality audio generation more accessible and practical for a wider range of applications.
Technical Explanation
The authors of this paper tackle the challenge of improving transformer-based audio generation by addressing two key issues: data quality and model complexity.
To address data quality, they propose a data filtering approach that selectively removes low-quality or irrelevant audio samples from the training dataset. This helps to ensure that the transformers are trained on a cleaner, more coherent set of audio data, which can improve their performance and stability.
For model complexity, the authors experiment with various regularization techniques to make the transformer models more robust and less prone to overfitting. This includes techniques like weight decay, dropout, and layer normalization, which help to prevent the models from becoming too specialized to the training data and instead encourage them to learn more general, transferable representations.
Additionally, the researchers explore novel transformer architectures that are better suited to the unique characteristics of audio data, such as its temporal structure and frequency-domain properties. This includes models that incorporate specialized modules for processing audio signals, as well as hybrid architectures that combine transformers with other types of neural networks.
The authors evaluate their proposed techniques on several audio generation tasks, including speech synthesis, music generation, and general sound generation. Their results demonstrate that the combination of data filtering, model regularization, and novel architectures can significantly improve the performance and stability of transformer-based audio generation systems, compared to standard approaches.
Critical Analysis
One of the key strengths of this paper is its focus on practical challenges in audio generation, such as data quality and model complexity, which are often overlooked in more theoretical work. The authors' systematic approach to addressing these challenges is commendable and can serve as a valuable blueprint for researchers and practitioners working in this field.
However, the paper does not provide a deep analysis of the underlying reasons why certain techniques are more effective than others. For example, it would be interesting to understand the specific characteristics of audio data that make certain transformer architectures more suitable than others. Additionally, the paper could have explored the trade-offs and limitations of the proposed approaches in more depth, such as the computational cost or the impact of different hyperparameter settings.
Furthermore, while the authors demonstrate the effectiveness of their techniques on a range of audio generation tasks, it would be useful to see how these methods perform in more real-world, application-specific scenarios, such as zero-shot audio captioning or multimodal audio-visual generation. This could provide additional insights into the practical implications and limitations of the proposed approaches.
Conclusion
The "Taming Data and Transformers for Audio Generation" paper makes a significant contribution to the field of audio generation by addressing two critical challenges: data quality and model complexity. The authors' systematic approach, which combines data filtering, model regularization, and novel transformer architectures, has demonstrated promising results in improving the performance and stability of transformer-based audio generation systems.
While the paper could benefit from a more in-depth analysis of the underlying reasons for the effectiveness of the proposed techniques, it provides a solid foundation for future research and development in this area. By "taming" transformers and the data they use, the authors have taken an important step towards making high-quality audio generation more accessible and practical for a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Taming Data and Transformers for Audio Generation
Moayed Haji-Ali, Willi Menapace, Aliaksandr Siarohin, Guha Balakrishnan, Sergey Tulyakov, Vicente Ordonez
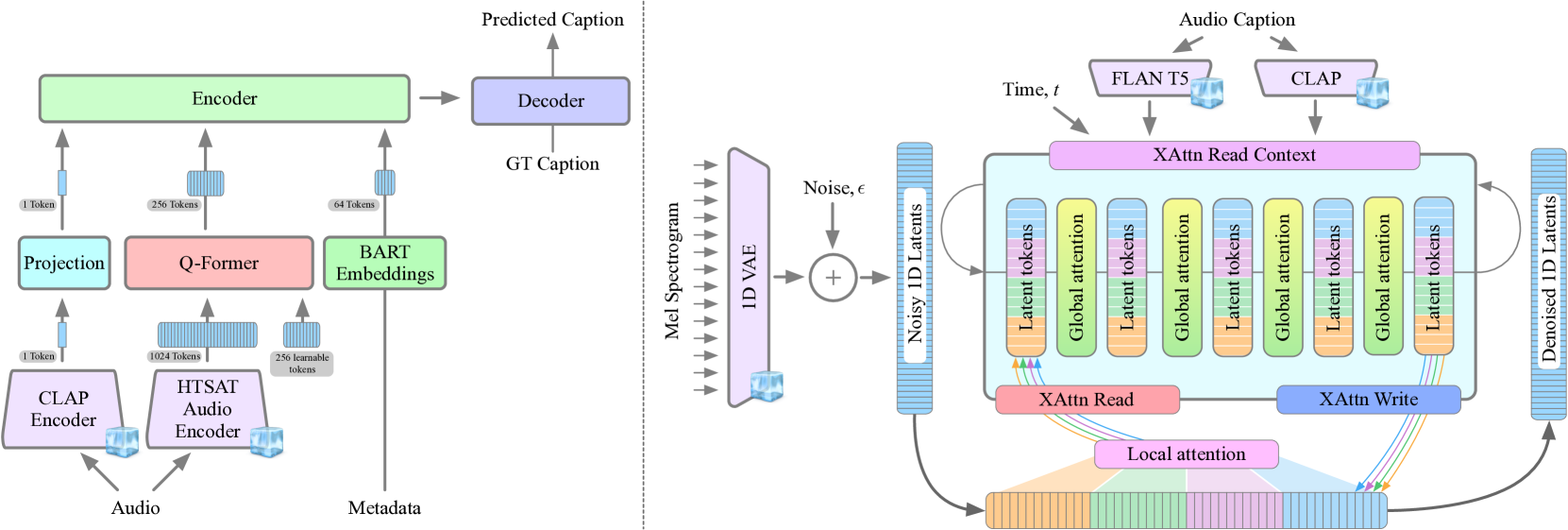
Generating ambient sounds and effects is a challenging problem due to data scarcity and often insufficient caption quality, making it difficult to employ large-scale generative models for the task. In this work, we tackle the problem by introducing two new models. First, we propose AutoCap, a high-quality and efficient automatic audio captioning model. We show that by leveraging metadata available with the audio modality, we can substantially improve the quality of captions. AutoCap reaches CIDEr score of 83.2, marking a 3.2% improvement from the best available captioning model at four times faster inference speed. We then use AutoCap to caption clips from existing datasets, obtaining 761,000 audio clips with high-quality captions, forming the largest available audio-text dataset. Second, we propose GenAu, a scalable transformer-based audio generation architecture that we scale up to 1.25B parameters and train with our new dataset. When compared to state-of-the-art audio generators, GenAu obtains significant improvements of 15.7% in FAD score, 22.7% in IS, and 13.5% in CLAP score, indicating significantly improved quality of generated audio compared to previous works. This shows that the quality of data is often as important as its quantity. Besides, since AutoCap is fully automatic, new audio samples can be added to the training dataset, unlocking the training of even larger generative models for audio synthesis.
Read more6/28/2024

0
Improving Audio Generation with Visual Enhanced Caption
Yi Yuan, Dongya Jia, Xiaobin Zhuang, Yuanzhe Chen, Zhengxi Liu, Zhuo Chen, Yuping Wang, Yuxuan Wang, Xubo Liu, Xiyuan Kang, Mark D. Plumbley, Wenwu Wang
Generative models have shown significant achievements in audio generation tasks. However, existing models struggle with complex and detailed prompts, leading to potential performance degradation. We hypothesize that this problem stems from the simplicity and scarcity of the training data. This work aims to create a large-scale audio dataset with rich captions for improving audio generation models. We first develop an automated pipeline to generate detailed captions by transforming predicted visual captions, audio captions, and tagging labels into comprehensive descriptions using a Large Language Model (LLM). The resulting dataset, Sound-VECaps, comprises 1.66M high-quality audio-caption pairs with enriched details including audio event orders, occurred places and environment information. We then demonstrate that training the text-to-audio generation models with Sound-VECaps significantly improves the performance on complex prompts. Furthermore, we conduct ablation studies of the models on several downstream audio-language tasks, showing the potential of Sound-VECaps in advancing audio-text representation learning. Our dataset and models are available online.
Read more8/16/2024
🤯
0
Improving Text-To-Audio Models with Synthetic Captions
Zhifeng Kong, Sang-gil Lee, Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Rafael Valle, Soujanya Poria, Bryan Catanzaro
It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new textit{state-of-the-art}.
Read more7/10/2024
🔍
0
RECAP: Retrieval-Augmented Audio Captioning
Sreyan Ghosh, Sonal Kumar, Chandra Kiran Reddy Evuru, Ramani Duraiswami, Dinesh Manocha
We present RECAP (REtrieval-Augmented Audio CAPtioning), a novel and effective audio captioning system that generates captions conditioned on an input audio and other captions similar to the audio retrieved from a datastore. Additionally, our proposed method can transfer to any domain without the need for any additional fine-tuning. To generate a caption for an audio sample, we leverage an audio-text model CLAP to retrieve captions similar to it from a replaceable datastore, which are then used to construct a prompt. Next, we feed this prompt to a GPT-2 decoder and introduce cross-attention layers between the CLAP encoder and GPT-2 to condition the audio for caption generation. Experiments on two benchmark datasets, Clotho and AudioCaps, show that RECAP achieves competitive performance in in-domain settings and significant improvements in out-of-domain settings. Additionally, due to its capability to exploit a large text-captions-only datastore in a training-free fashion, RECAP shows unique capabilities of captioning novel audio events never seen during training and compositional audios with multiple events. To promote research in this space, we also release 150,000+ new weakly labeled captions for AudioSet, AudioCaps, and Clotho.
Read more6/7/2024