Cacophony: An Improved Contrastive Audio-Text Model
2402.06986
0
0
📈
Abstract
Despite recent advancements in audio-text modeling, audio-text contrastive models still lag behind their image-text counterparts in scale and performance. We propose a method to improve both the scale and the training of audio-text contrastive models. Specifically, we craft a large-scale audio-text dataset containing 13,000 hours of text-labeled audio, using pretrained language models to process noisy text descriptions and automatic captioning to obtain text descriptions for unlabeled audio samples. We first train on audio-only data with a masked autoencoder (MAE) objective, which allows us to benefit from the scalability of unlabeled audio datasets. We then, initializing our audio encoder from the MAE model, train a contrastive model with an auxiliary captioning objective. Our final model, which we name Cacophony, achieves state-of-the-art performance on audio-text retrieval tasks, and exhibits competitive results on the HEAR benchmark and other downstream tasks such as zero-shot classification.
Create account to get full access
Overview
- The paper addresses the challenge of improving the scale and training of audio-text contrastive models, which currently lag behind their image-text counterparts.
- The authors propose a method that involves:
- Creating a large-scale audio-text dataset using pre-trained language models and automatic captioning.
- Pre-training an audio encoder using a masked autoencoder (MAE) objective on the unlabeled audio data.
- Fine-tuning the audio encoder with a contrastive objective and an auxiliary captioning task.
- The resulting model, called Cacophony, achieves state-of-the-art performance on audio-text retrieval tasks and shows competitive results on other benchmarks.
Plain English Explanation
The paper focuses on improving the performance of models that can connect audio and text data. These models are useful for applications like audio search, where you could search for audio clips using text queries. However, current audio-text models are not as advanced as models that connect images and text.
To address this, the researchers created a large dataset of audio clips paired with text descriptions. They used pre-trained language models to process noisy text descriptions, and automatic captioning to generate text for audio samples that didn't have labels. This gave them a very large dataset to train on.
First, they trained the audio encoder using a "masked autoencoder" approach, which allowed them to learn useful audio features from the unlabeled audio data. Then, they fine-tuned the encoder using a contrastive objective, which learns to match audio and text that go together. They also added an auxiliary captioning task, to further improve the model's ability to connect audio and text.
The final model, called Cacophony, performed very well on benchmarks that test how accurately it can retrieve relevant audio for a given text query, or vice versa. It also did well on other tasks like zero-shot classification, where the model has to classify audio samples into categories without being explicitly trained on those categories.
Technical Explanation
The key contributions of the paper are:
-
Large-scale Audio-Text Dataset: The authors create a dataset of 13,000 hours of text-labeled audio by using pre-trained language models to process noisy text descriptions and automatic captioning to obtain text for unlabeled audio samples. This allows them to leverage a much larger and more diverse dataset compared to prior work.
-
Masked Autoencoder Pre-training: The authors first train the audio encoder using a masked autoencoder (MAE) objective on the unlabeled audio data. This allows them to learn useful audio representations without relying on the limited text labels.
-
Contrastive Fine-tuning with Auxiliary Captioning: After the MAE pre-training, the authors fine-tune the audio encoder using a contrastive objective to match audio and text, along with an auxiliary captioning task. This helps the model learn to better align audio and text representations.
-
State-of-the-Art Performance: The final Cacophony model achieves the best results on audio-text retrieval benchmarks and shows competitive performance on other tasks like zero-shot classification, demonstrating the effectiveness of the proposed approach.
The authors leverage techniques from recent work on text-audio alignment, multi-scale contrastive learning, and diffusion-based text-to-audio synthesis to achieve these improvements. The audio-from-silent-video task is also related, though not directly addressed in this work.
Critical Analysis
The paper presents a compelling approach to improving audio-text contrastive models, but there are a few potential limitations and areas for further research:
-
Generalization to Diverse Audio: While the dataset is large, it's not clear how well the model would generalize to more diverse audio data, such as music or environmental sounds, beyond the primarily speech-based audio in the training set.
-
Efficiency and Scalability: The proposed approach involves several pre-training and fine-tuning steps, which could be computationally intensive. It would be valuable to explore more efficient training strategies or architectures that can scale better.
-
Interpretability and Explainability: The paper does not delve into the interpretability or explainability of the learned audio-text representations. Understanding the inner workings of the model could lead to further improvements and insights.
-
Real-world Applications: While the model shows strong performance on benchmarks, more research is needed to understand its practical implications and deployment in real-world scenarios, such as audio search or audio captioning.
Overall, the paper presents an interesting and effective approach to improving audio-text contrastive models, but there is still room for further exploration and refinement, especially in terms of generalization, efficiency, and practical applications.
Conclusion
The paper proposes a novel method to enhance the scale and performance of audio-text contrastive models, which are crucial for applications like audio search and audio-text alignment. By creating a large-scale audio-text dataset, leveraging masked autoencoder pre-training, and fine-tuning with a contrastive objective and auxiliary captioning task, the authors were able to develop a state-of-the-art model called Cacophony.
The results demonstrate significant improvements in audio-text retrieval tasks and competitive performance on other benchmarks, highlighting the potential of this approach to advance the field of audio-text representation learning. While there are still some limitations to address, this work represents an important step forward in bridging the gap between audio and text modalities and paves the way for more powerful and versatile multimodal models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤯
Improving Text-To-Audio Models with Synthetic Captions
Zhifeng Kong, Sang-gil Lee, Deepanway Ghosal, Navonil Majumder, Ambuj Mehrish, Rafael Valle, Soujanya Poria, Bryan Catanzaro
0
0
It is an open challenge to obtain high quality training data, especially captions, for text-to-audio models. Although prior methods have leveraged textit{text-only language models} to augment and improve captions, such methods have limitations related to scale and coherence between audio and captions. In this work, we propose an audio captioning pipeline that uses an textit{audio language model} to synthesize accurate and diverse captions for audio at scale. We leverage this pipeline to produce a dataset of synthetic captions for AudioSet, named texttt{AF-AudioSet}, and then evaluate the benefit of pre-training text-to-audio models on these synthetic captions. Through systematic evaluations on AudioCaps and MusicCaps, we find leveraging our pipeline and synthetic captions leads to significant improvements on audio generation quality, achieving a new textit{state-of-the-art}.
6/26/2024

Enhancing Automated Audio Captioning via Large Language Models with Optimized Audio Encoding
Jizhong Liu, Gang Li, Junbo Zhang, Heinrich Dinkel, Yongqing Wang, Zhiyong Yan, Yujun Wang, Bin Wang
0
0
Automated audio captioning (AAC) is an audio-to-text task to describe audio contents in natural language. Recently, the advancements in large language models (LLMs), with improvements in training approaches for audio encoders, have opened up possibilities for improving AAC. Thus, we explore enhancing AAC from three aspects: 1) a pre-trained audio encoder via consistent ensemble distillation (CED) is used to improve the effectivity of acoustic tokens, with a querying transformer (Q-Former) bridging the modality gap to LLM and compress acoustic tokens; 2) we investigate the advantages of using a Llama 2 with 7B parameters as the decoder; 3) another pre-trained LLM corrects text errors caused by insufficient training data and annotation ambiguities. Both the audio encoder and text decoder are optimized by low-rank adaptation (LoRA). Experiments show that each of these enhancements is effective. Our method obtains a 33.0 SPIDEr-FL score, outperforming the winner of DCASE 2023 Task 6A.
6/26/2024
Zero-Shot Audio Captioning Using Soft and Hard Prompts
Yiming Zhang, Xuenan Xu, Ruoyi Du, Haohe Liu, Yuan Dong, Zheng-Hua Tan, Wenwu Wang, Zhanyu Ma
0
0
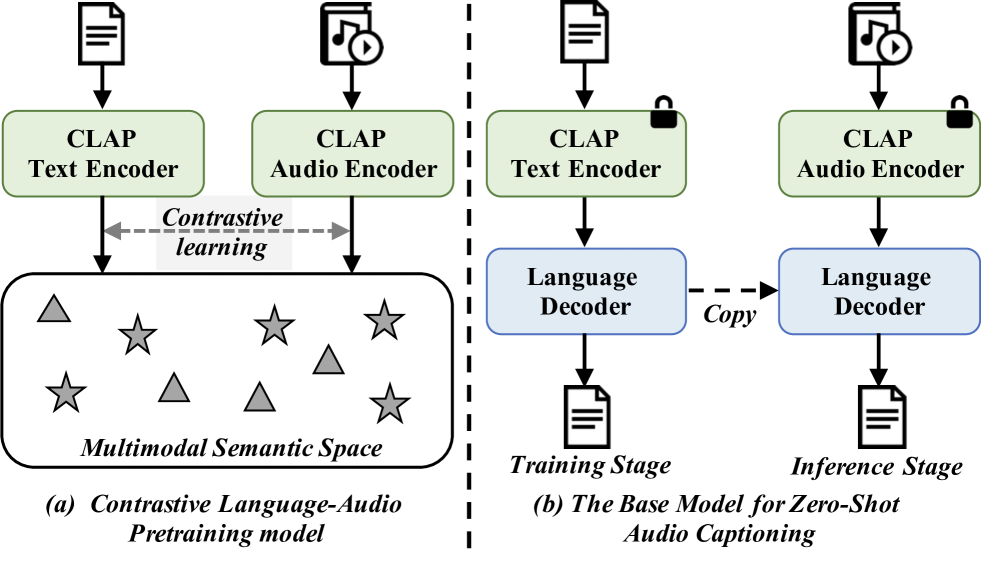
In traditional audio captioning methods, a model is usually trained in a fully supervised manner using a human-annotated dataset containing audio-text pairs and then evaluated on the test sets from the same dataset. Such methods have two limitations. First, these methods are often data-hungry and require time-consuming and expensive human annotations to obtain audio-text pairs. Second, these models often suffer from performance degradation in cross-domain scenarios, i.e., when the input audio comes from a different domain than the training set, which, however, has received little attention. We propose an effective audio captioning method based on the contrastive language-audio pre-training (CLAP) model to address these issues. Our proposed method requires only textual data for training, enabling the model to generate text from the textual feature in the cross-modal semantic space.In the inference stage, the model generates the descriptive text for the given audio from the audio feature by leveraging the audio-text alignment from CLAP.We devise two strategies to mitigate the discrepancy between text and audio embeddings: a mixed-augmentation-based soft prompt and a retrieval-based acoustic-aware hard prompt. These approaches are designed to enhance the generalization performance of our proposed model, facilitating the model to generate captions more robustly and accurately. Extensive experiments on AudioCaps and Clotho benchmarks show the effectiveness of our proposed method, which outperforms other zero-shot audio captioning approaches for in-domain scenarios and outperforms the compared methods for cross-domain scenarios, underscoring the generalization ability of our method.
6/11/2024
Contrastive Learning from Synthetic Audio Doppelgangers
Manuel Cherep, Nikhil Singh
0
0
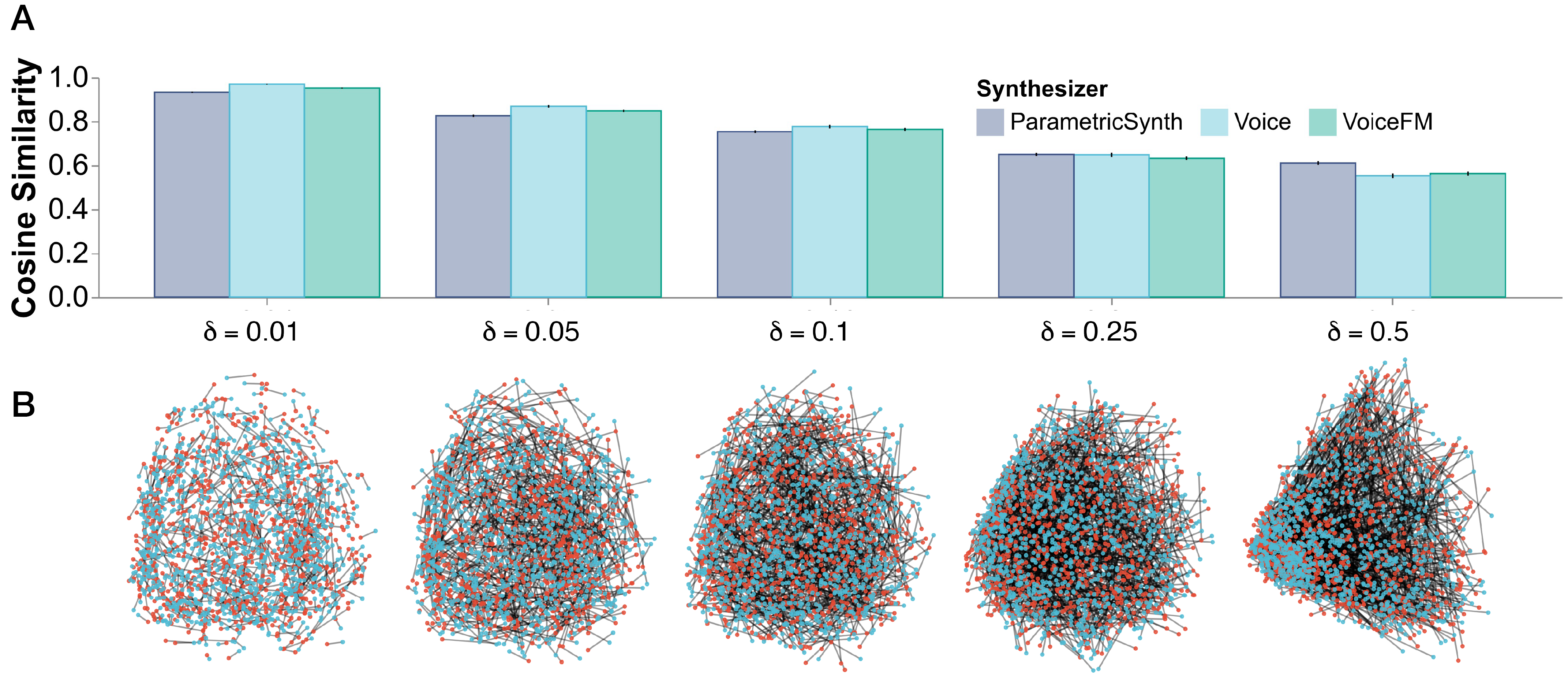
Learning robust audio representations currently demands extensive datasets of real-world sound recordings. By applying artificial transformations to these recordings, models can learn to recognize similarities despite subtle variations through techniques like contrastive learning. However, these transformations are only approximations of the true diversity found in real-world sounds, which are generated by complex interactions of physical processes, from vocal cord vibrations to the resonance of musical instruments. We propose a solution to both the data scale and transformation limitations, leveraging synthetic audio. By randomly perturbing the parameters of a sound synthesizer, we generate audio doppelgangers-synthetic positive pairs with causally manipulated variations in timbre, pitch, and temporal envelopes. These variations, difficult to achieve through transformations of existing audio, provide a rich source of contrastive information. Despite the shift to randomly generated synthetic data, our method produces strong representations, competitive with real data on standard audio classification benchmarks. Notably, our approach is lightweight, requires no data storage, and has only a single hyperparameter, which we extensively analyze. We offer this method as a complement to existing strategies for contrastive learning in audio, using synthesized sounds to reduce the data burden on practitioners.
6/11/2024