Improving Transformers using Faithful Positional Encoding
2405.09061
0
0
Abstract
We propose a new positional encoding method for a neural network architecture called the Transformer. Unlike the standard sinusoidal positional encoding, our approach is based on solid mathematical grounds and has a guarantee of not losing information about the positional order of the input sequence. We show that the new encoding approach systematically improves the prediction performance in the time-series classification task.
Create account to get full access
Overview
- This paper proposes a new approach to positional encoding in Transformer models, which aims to improve their performance on various tasks.
- The authors introduce a "Faithful Positional Encoding" (FPE) method that better captures the relative position of tokens in a sequence.
- The proposed FPE is shown to outperform standard Transformer positional encodings on several benchmark datasets and tasks.
Plain English Explanation
The Transformer is a popular neural network architecture that has revolutionized many natural language processing and other sequence-to-sequence tasks. A key component of the Transformer is its positional encoding, which tells the model the position of each token in the input sequence. However, the standard positional encoding methods used in Transformers have some limitations.
The authors of this paper introduce a new way of encoding position information, called "Faithful Positional Encoding" (FPE). FPE aims to better capture the relative positions of tokens in the sequence, which can be important for tasks like language modeling, machine translation, and time series forecasting.
The key idea behind FPE is to use a Fourier-based encoding that represents the position of each token as a combination of sine and cosine waves. This allows the model to learn more complex patterns in the relative positions of tokens, rather than just treating them as independent positions.
The researchers show that Transformers using FPE outperform those with standard positional encodings on a variety of benchmark tasks. This suggests that FPE is a promising approach for improving the performance of Transformer-based models, especially in applications where the relative positions of tokens are crucial.
Technical Explanation
The paper introduces a new positional encoding method called "Faithful Positional Encoding" (FPE) that aims to better capture the relative positions of tokens in a sequence. The standard positional encoding used in Transformers, which assigns a unique vector representation to each token position, has limitations in fully representing the relative positions of tokens.
The FPE method uses a Fourier-based encoding, where the position of each token is represented as a combination of sine and cosine waves with different frequencies. This allows the model to learn more complex patterns in the relative positions of tokens, rather than just treating them as independent positions.
Formally, the FPE encoding for a token at position i in a sequence of length n is defined as:
FPE(i, n) = [sin(2πj*i/n) for j in range(d/2)] + [cos(2πj*i/n) for j in range(d/2)]
where d is the dimension of the positional encoding.
The authors show that Transformers using FPE outperform those with standard positional encodings on a variety of benchmark tasks, including language modeling, machine translation, and time series forecasting. This suggests that the FPE method is a promising approach for improving the performance of Transformer-based models, especially in applications where the relative positions of tokens are crucial.
Critical Analysis
The paper presents a solid technical contribution by introducing a new positional encoding method that can improve the performance of Transformer models. The FPE approach is well-motivated and the experimental results demonstrate its effectiveness across multiple tasks and datasets.
One potential limitation of the FPE method is that it may be more computationally expensive than standard positional encodings, as it requires more complex trigonometric calculations. The authors do not provide a detailed analysis of the computational complexity or training time of FPE compared to other methods.
Additionally, the paper does not delve into the interpretability or explainability of the FPE representations. It would be interesting to understand how the Fourier-based encoding captures the relative position information and how this differs from the intuitions behind other positional encoding schemes, such as learned positional embeddings or linear relative positional encodings.
Overall, the paper makes a valuable contribution to the Transformer literature by introducing a novel positional encoding method that can improve model performance. Further research could explore the computational and interpretability aspects of FPE, as well as its applicability to a broader range of sequence-to-sequence tasks and architectures.
Conclusion
This paper proposes a new "Faithful Positional Encoding" (FPE) method for Transformers that can better capture the relative positions of tokens in a sequence. By representing position using a Fourier-based encoding, FPE allows Transformer models to learn more complex patterns in the relative positions of tokens, leading to improved performance on a variety of benchmark tasks.
The results suggest that FPE is a promising approach for enhancing the capabilities of Transformer-based models, particularly in applications where the relative positions of tokens are crucial, such as language modeling, machine translation, and time series forecasting. Further research could explore the computational and interpretability aspects of FPE, as well as its broader applicability to other sequence-to-sequence tasks and architectures.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

GridPE: Unifying Positional Encoding in Transformers with a Grid Cell-Inspired Framework
Boyang Li, Yulin Wu, Nuoxian Huang
0
0
Understanding spatial location and relationships is a fundamental capability for modern artificial intelligence systems. Insights from human spatial cognition provide valuable guidance in this domain. Recent neuroscientific discoveries have highlighted the role of grid cells as a fundamental neural component for spatial representation, including distance computation, path integration, and scale discernment. In this paper, we introduce a novel positional encoding scheme inspired by Fourier analysis and the latest findings in computational neuroscience regarding grid cells. Assuming that grid cells encode spatial position through a summation of Fourier basis functions, we demonstrate the translational invariance of the grid representation during inner product calculations. Additionally, we derive an optimal grid scale ratio for multi-dimensional Euclidean spaces based on principles of biological efficiency. Utilizing these computational principles, we have developed a **Grid**-cell inspired **Positional Encoding** technique, termed **GridPE**, for encoding locations within high-dimensional spaces. We integrated GridPE into the Pyramid Vision Transformer architecture. Our theoretical analysis shows that GridPE provides a unifying framework for positional encoding in arbitrary high-dimensional spaces. Experimental results demonstrate that GridPE significantly enhances the performance of transformers, underscoring the importance of incorporating neuroscientific insights into the design of artificial intelligence systems.
6/12/2024
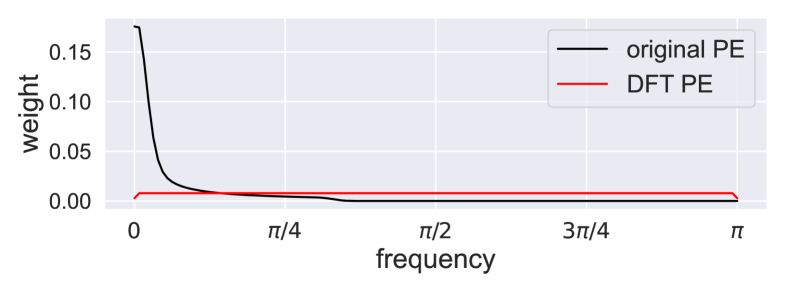
Intriguing Properties of Positional Encoding in Time Series Forecasting
Jianqi Zhang, Jingyao Wang, Wenwen Qiang, Fanjiang Xu, Changwen Zheng, Fuchun Sun, Hui Xiong
0
0
Transformer-based methods have made significant progress in time series forecasting (TSF). They primarily handle two types of tokens, i.e., temporal tokens that contain all variables of the same timestamp, and variable tokens that contain all input time points for a specific variable. Transformer-based methods rely on positional encoding (PE) to mark tokens' positions, facilitating the model to perceive the correlation between tokens. However, in TSF, research on PE remains insufficient. To address this gap, we conduct experiments and uncover intriguing properties of existing PEs in TSF: (i) The positional information injected by PEs diminishes as the network depth increases; (ii) Enhancing positional information in deep networks is advantageous for improving the model's performance; (iii) PE based on the similarity between tokens can improve the model's performance. Motivated by these findings, we introduce two new PEs: Temporal Position Encoding (T-PE) for temporal tokens and Variable Positional Encoding (V-PE) for variable tokens. Both T-PE and V-PE incorporate geometric PE based on tokens' positions and semantic PE based on the similarity between tokens but using different calculations. To leverage both the PEs, we design a Transformer-based dual-branch framework named T2B-PE. It first calculates temporal tokens' correlation and variable tokens' correlation respectively and then fuses the dual-branch features through the gated unit. Extensive experiments demonstrate the superior robustness and effectiveness of T2B-PE. The code is available at: href{https://github.com/jlu-phyComputer/T2B-PE}{https://github.com/jlu-phyComputer/T2B-PE}.
4/17/2024
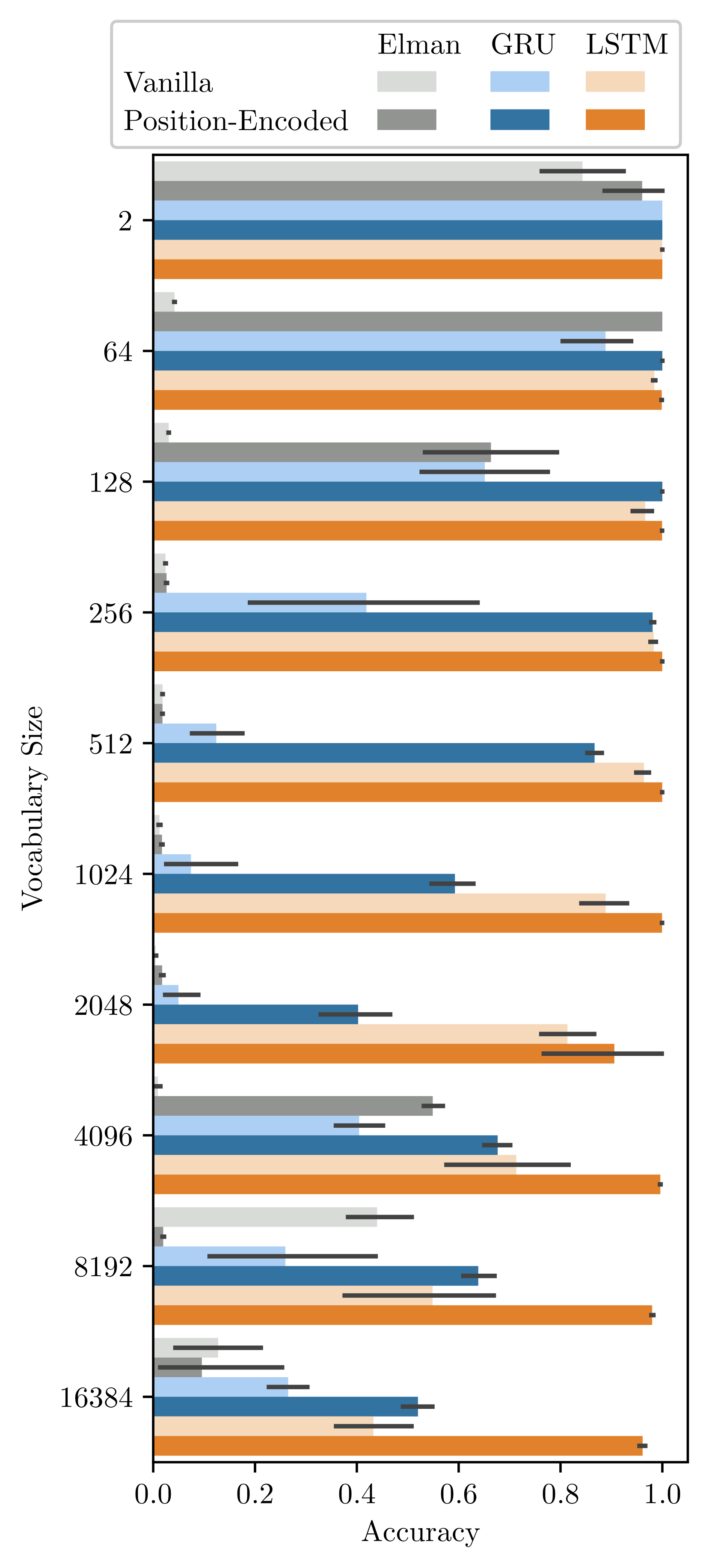
Positional Encoding Helps Recurrent Neural Networks Handle a Large Vocabulary
Takashi Morita
0
0
This study reports an unintuitive finding that positional encoding enhances learning of recurrent neural networks (RNNs). Positional encoding is a high-dimensional representation of time indices on input data. Most famously, positional encoding complements the capabilities of Transformer neural networks, which lack an inherent mechanism for representing the data order. By contrast, RNNs can encode the temporal information of data points on their own, rendering their use of positional encoding seemingly redundant/unnecessary. Nonetheless, investigations through synthetic benchmarks reveal an advantage of coupling positional encoding and RNNs, especially for handling a large vocabulary that yields low-frequency tokens. Further scrutinization unveils that these low-frequency tokens destabilizes the gradients of vanilla RNNs, and the positional encoding resolves this instability. These results shed a new light on the utility of positional encoding beyond its canonical role as a timekeeper for Transformers.
6/19/2024

What Improves the Generalization of Graph Transformers? A Theoretical Dive into the Self-attention and Positional Encoding
Hongkang Li, Meng Wang, Tengfei Ma, Sijia Liu, Zaixi Zhang, Pin-Yu Chen
0
0
Graph Transformers, which incorporate self-attention and positional encoding, have recently emerged as a powerful architecture for various graph learning tasks. Despite their impressive performance, the complex non-convex interactions across layers and the recursive graph structure have made it challenging to establish a theoretical foundation for learning and generalization. This study introduces the first theoretical investigation of a shallow Graph Transformer for semi-supervised node classification, comprising a self-attention layer with relative positional encoding and a two-layer perceptron. Focusing on a graph data model with discriminative nodes that determine node labels and non-discriminative nodes that are class-irrelevant, we characterize the sample complexity required to achieve a desirable generalization error by training with stochastic gradient descent (SGD). This paper provides the quantitative characterization of the sample complexity and number of iterations for convergence dependent on the fraction of discriminative nodes, the dominant patterns, and the initial model errors. Furthermore, we demonstrate that self-attention and positional encoding enhance generalization by making the attention map sparse and promoting the core neighborhood during training, which explains the superior feature representation of Graph Transformers. Our theoretical results are supported by empirical experiments on synthetic and real-world benchmarks.
6/5/2024