Positional Encoding Helps Recurrent Neural Networks Handle a Large Vocabulary
2402.00236
0
0
Abstract
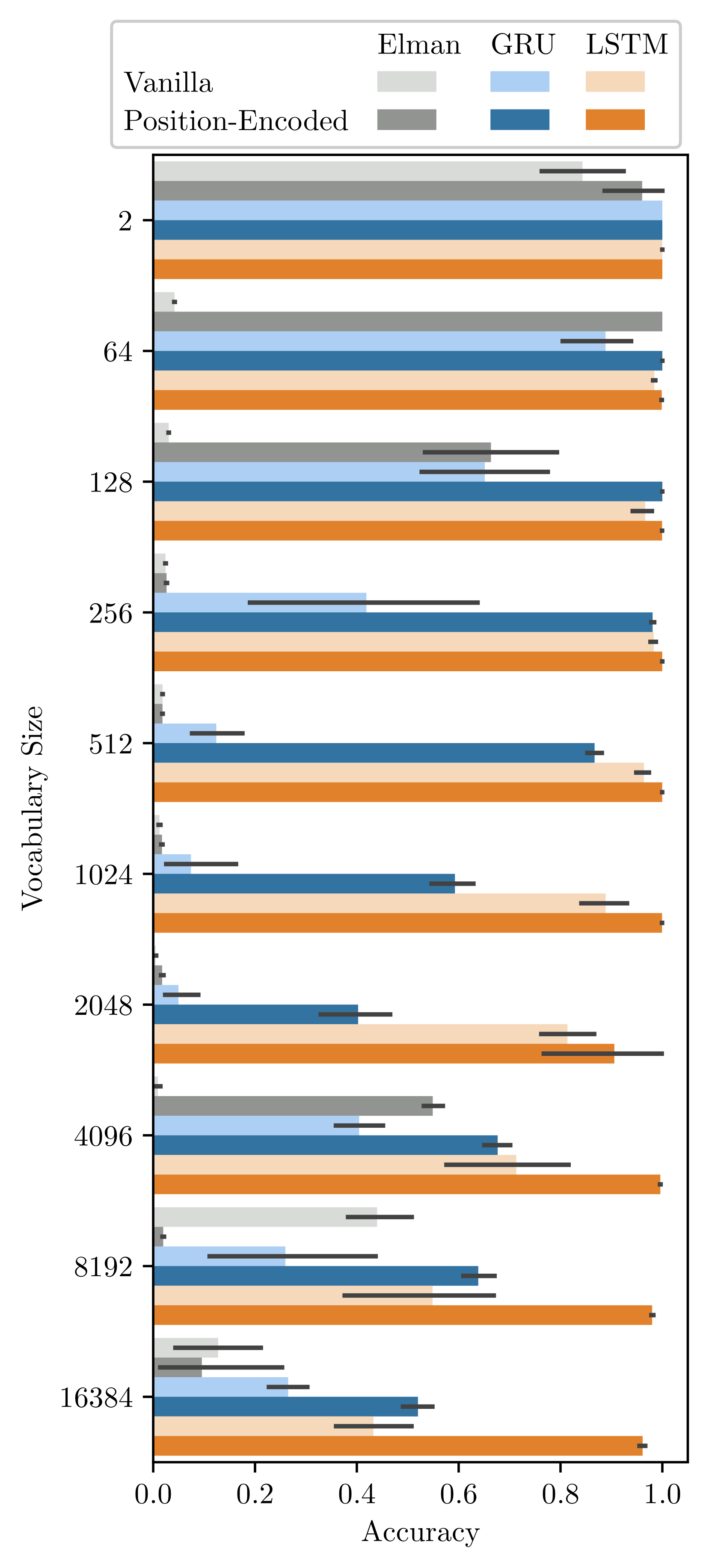
This study reports an unintuitive finding that positional encoding enhances learning of recurrent neural networks (RNNs). Positional encoding is a high-dimensional representation of time indices on input data. Most famously, positional encoding complements the capabilities of Transformer neural networks, which lack an inherent mechanism for representing the data order. By contrast, RNNs can encode the temporal information of data points on their own, rendering their use of positional encoding seemingly redundant/unnecessary. Nonetheless, investigations through synthetic benchmarks reveal an advantage of coupling positional encoding and RNNs, especially for handling a large vocabulary that yields low-frequency tokens. Further scrutinization unveils that these low-frequency tokens destabilizes the gradients of vanilla RNNs, and the positional encoding resolves this instability. These results shed a new light on the utility of positional encoding beyond its canonical role as a timekeeper for Transformers.
Create account to get full access
Overview
- The research paper explores how positional encoding can help recurrent neural networks (RNNs) handle a large vocabulary.
- Positional encoding is a technique used to incorporate information about the position of tokens in a sequence, which can be important for tasks like language modeling.
- The paper investigates the impact of positional encoding on RNNs, particularly their ability to handle a large vocabulary.
Plain English Explanation
Recurrent neural networks (RNNs) are a type of machine learning model that are particularly well-suited for processing sequential data, such as text or speech. One challenge that RNNs face is handling a large vocabulary, which can lead to inefficient training and poor performance.
The researchers of this paper explored a technique called positional encoding to help RNNs better handle a large vocabulary. Positional encoding is a way of incorporating information about the position of each token (e.g., word) in a sequence. This can be important for tasks like language modeling, where the meaning of a word can depend on its context within the sentence.
The researchers compared RNNs with and without positional encoding on various language modeling tasks with large vocabularies. Their results showed that incorporating positional encoding significantly improved the performance of RNNs, allowing them to better handle the large vocabulary and achieve higher accuracy on the tasks.
This research suggests that positional encoding can be a valuable tool for improving the performance of RNNs, particularly in applications where handling a large vocabulary is a key challenge. By incorporating information about the position of tokens, RNNs can better understand the context and meaning of the input, leading to more accurate and efficient language modeling.
Technical Explanation
The researchers investigated the impact of positional encoding on the performance of recurrent neural networks (RNNs) in handling a large vocabulary. Positional encoding is a technique used to incorporate information about the position of tokens in a sequence, which can be important for tasks like language modeling.
The researchers compared the performance of RNNs with and without positional encoding on various language modeling tasks with large vocabularies. They used a standard LSTM (long short-term memory) architecture as the baseline RNN model and experimented with different positional encoding methods, including sine/cosine functions and learned positional embeddings.
The results showed that incorporating positional encoding significantly improved the performance of RNNs on the language modeling tasks. The RNNs with positional encoding were able to better handle the large vocabulary, leading to higher accuracy and more efficient training compared to the baseline RNN models.
The researchers also explored the intriguing properties of positional encoding and how it can help RNNs capture contextual information. They found that positional encoding can help RNNs better understand the relationships between tokens in a sequence, which is particularly important for tasks with large vocabularies.
Overall, this research suggests that positional encoding is an important consideration when designing RNN-based models for language modeling and other tasks with large vocabularies. By incorporating information about the position of tokens, RNNs can better capture the context and meaning of the input, leading to improved performance and efficiency.
Critical Analysis
The research presented in this paper provides valuable insights into the role of positional encoding in improving the performance of recurrent neural networks (RNNs) on language modeling tasks with large vocabularies. The authors' experiments and analysis demonstrate the significant benefits of incorporating positional information into RNN models, which can help them better capture the context and relationships between tokens.
However, the paper also raises some potential limitations and areas for further research. For example, the researchers only explored a limited set of positional encoding methods, and it would be interesting to see how other techniques, such as learned positional embeddings, might perform in comparison.
Additionally, the paper does not delve into the underlying mechanisms by which positional encoding improves RNN performance. A deeper understanding of the specific ways in which positional information is leveraged by RNNs could lead to further refinements and optimizations of the approach.
It would also be valuable to investigate the performance of positional encoding in RNNs on a broader range of language tasks, beyond just language modeling. Exploring its effectiveness in areas like machine translation, dialogue systems, or text summarization could provide a more comprehensive picture of its potential benefits and limitations.
Overall, this research represents an important contribution to the field of natural language processing and the development of more effective RNN-based models. By highlighting the importance of positional encoding, the paper encourages further exploration and innovation in this area, which could lead to significant advancements in our ability to handle large vocabularies and complex language tasks.
Conclusion
The research paper presented a compelling case for the use of positional encoding in improving the performance of recurrent neural networks (RNNs) on language modeling tasks with large vocabularies. The results showed that incorporating positional information into RNN models can significantly enhance their ability to handle a large vocabulary, leading to higher accuracy and more efficient training.
This research suggests that positional encoding is an important consideration in the design of RNN-based models, particularly for applications where handling a large vocabulary is a key challenge. By better capturing the context and relationships between tokens, RNNs with positional encoding can better understand the meaning and structure of language, unlocking new possibilities for advancing natural language processing and generation tasks.
As the field of machine learning continues to evolve, the insights and techniques presented in this paper may pave the way for more robust and versatile RNN architectures that can tackle increasingly complex language-related problems. Continued research and exploration in this area could yield further breakthroughs, ultimately enhancing our ability to build intelligent systems that can communicate and interact with humans in more natural and meaningful ways.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Positional encoding is not the same as context: A study on positional encoding for Sequential recommendation
Alejo Lopez-Avila, Jinhua Du, Abbas Shimary, Ze Li
0
0
The expansion of streaming media and e-commerce has led to a boom in recommendation systems, including Sequential recommendation systems, which consider the user's previous interactions with items. In recent years, research has focused on architectural improvements such as transformer blocks and feature extraction that can augment model information. Among these features are context and attributes. Of particular importance is the temporal footprint, which is often considered part of the context and seen in previous publications as interchangeable with positional information. Other publications use positional encodings with little attention to them. In this paper, we analyse positional encodings, showing that they provide relative information between items that are not inferable from the temporal footprint. Furthermore, we evaluate different encodings and how they affect metrics and stability using Amazon datasets. We added some new encodings to help with these problems along the way. We found that we can reach new state-of-the-art results by finding the correct positional encoding, but more importantly, certain encodings stabilise the training.
5/20/2024
Improving Transformers using Faithful Positional Encoding
Tsuyoshi Id'e, Jokin Labaien, Pin-Yu Chen
0
0
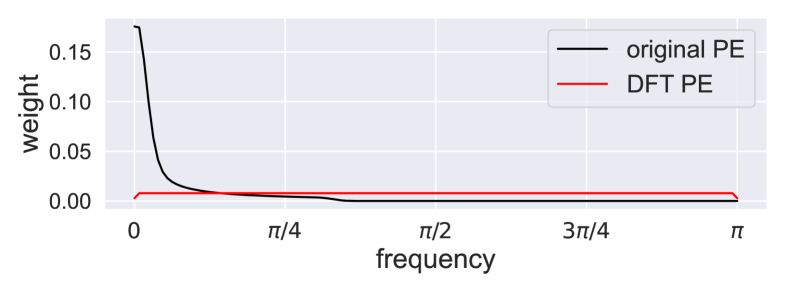
We propose a new positional encoding method for a neural network architecture called the Transformer. Unlike the standard sinusoidal positional encoding, our approach is based on solid mathematical grounds and has a guarantee of not losing information about the positional order of the input sequence. We show that the new encoding approach systematically improves the prediction performance in the time-series classification task.
5/17/2024
Intriguing Properties of Positional Encoding in Time Series Forecasting
Jianqi Zhang, Jingyao Wang, Wenwen Qiang, Fanjiang Xu, Changwen Zheng, Fuchun Sun, Hui Xiong
0
0
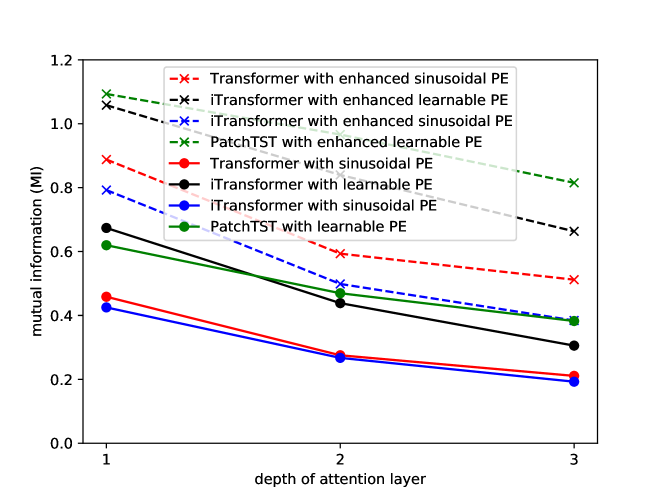
Transformer-based methods have made significant progress in time series forecasting (TSF). They primarily handle two types of tokens, i.e., temporal tokens that contain all variables of the same timestamp, and variable tokens that contain all input time points for a specific variable. Transformer-based methods rely on positional encoding (PE) to mark tokens' positions, facilitating the model to perceive the correlation between tokens. However, in TSF, research on PE remains insufficient. To address this gap, we conduct experiments and uncover intriguing properties of existing PEs in TSF: (i) The positional information injected by PEs diminishes as the network depth increases; (ii) Enhancing positional information in deep networks is advantageous for improving the model's performance; (iii) PE based on the similarity between tokens can improve the model's performance. Motivated by these findings, we introduce two new PEs: Temporal Position Encoding (T-PE) for temporal tokens and Variable Positional Encoding (V-PE) for variable tokens. Both T-PE and V-PE incorporate geometric PE based on tokens' positions and semantic PE based on the similarity between tokens but using different calculations. To leverage both the PEs, we design a Transformer-based dual-branch framework named T2B-PE. It first calculates temporal tokens' correlation and variable tokens' correlation respectively and then fuses the dual-branch features through the gated unit. Extensive experiments demonstrate the superior robustness and effectiveness of T2B-PE. The code is available at: href{https://github.com/jlu-phyComputer/T2B-PE}{https://github.com/jlu-phyComputer/T2B-PE}.
4/17/2024
Contextual Position Encoding: Learning to Count What's Important
Olga Golovneva, Tianlu Wang, Jason Weston, Sainbayar Sukhbaatar
0
0
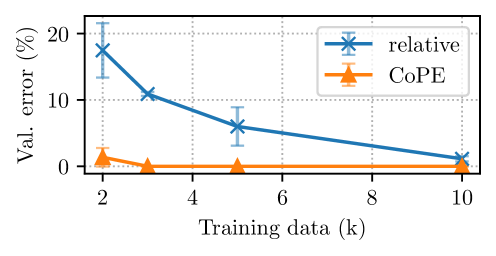
The attention mechanism is a critical component of Large Language Models (LLMs) that allows tokens in a sequence to interact with each other, but is order-invariant. Incorporating position encoding (PE) makes it possible to address by position, such as attending to the i-th token. However, current PE methods use token counts to derive position, and thus cannot generalize to higher levels of abstraction, such as attending to the i-th sentence. In this paper, we propose a new position encoding method, Contextual Position Encoding (CoPE), that allows positions to be conditioned on context by incrementing position only on certain tokens determined by the model. This allows more general position addressing such as attending to the $i$-th particular word, noun, or sentence. We show that CoPE can solve the selective copy, counting and Flip-Flop tasks where popular position embeddings fail, and improves perplexity on language modeling and coding tasks.
5/31/2024