VLLMs Provide Better Context for Emotion Understanding Through Common Sense Reasoning
2404.07078
0
0

Abstract
Recognising emotions in context involves identifying the apparent emotions of an individual, taking into account contextual cues from the surrounding scene. Previous approaches to this task have involved the design of explicit scene-encoding architectures or the incorporation of external scene-related information, such as captions. However, these methods often utilise limited contextual information or rely on intricate training pipelines. In this work, we leverage the groundbreaking capabilities of Vision-and-Large-Language Models (VLLMs) to enhance in-context emotion classification without introducing complexity to the training process in a two-stage approach. In the first stage, we propose prompting VLLMs to generate descriptions in natural language of the subject's apparent emotion relative to the visual context. In the second stage, the descriptions are used as contextual information and, along with the image input, are used to train a transformer-based architecture that fuses text and visual features before the final classification task. Our experimental results show that the text and image features have complementary information, and our fused architecture significantly outperforms the individual modalities without any complex training methods. We evaluate our approach on three different datasets, namely, EMOTIC, CAER-S, and BoLD, and achieve state-of-the-art or comparable accuracy across all datasets and metrics compared to much more complex approaches. The code will be made publicly available on github: https://github.com/NickyFot/EmoCommonSense.git
Create account to get full access
Introduction
This research paper examines how Vision-Language Large Models (VLLMs) can provide better context for understanding human emotions through common sense reasoning. The paper argues that VLLMs, which are trained on a vast amount of multimodal data, can capture the rich contextual information needed to recognize emotions in complex real-world scenarios.
Overview
- VLLMs can leverage common sense reasoning to better understand the emotional context of images and text.
- The paper presents a new benchmark dataset and model for contextual emotion recognition.
- Experiments show that VLLMs outperform text-only models on this task, demonstrating the value of multimodal understanding.
- The findings have implications for building more empathetic and socially aware AI systems.
Plain English Explanation
The key idea is that AI models that can process both images and text (known as VLLMs) are better equipped to understand human emotions than models that only look at text. This is because emotions often depend on the broader context, which includes visual information like facial expressions, body language, and the surrounding environment.
VLLMs are trained on massive amounts of image and text data, allowing them to develop a deep understanding of how the world works and how people typically feel in different situations. This "common sense" knowledge helps the models infer the emotional state of a person or scene, even if the textual information alone is ambiguous or incomplete.
For example, if a person is described as "upset" in a piece of text, a VLLM can look at the accompanying image and notice that the person has a frowning face and tense body language. By combining this visual information with the textual cue, the model can more accurately recognize that the person is indeed feeling distressed or angry, rather than just sad.
The paper introduces a new benchmark dataset and model to test this idea. The results show that VLLMs significantly outperform text-only models on the task of recognizing emotions in context. This suggests that developing AI systems with multimodal understanding, rather than just language understanding, could lead to more empathetic and socially aware technologies in the future.
Technical Explanation
The paper introduces a new benchmark dataset called "Contextual Emotion Recognition" (CER) that consists of image-text pairs annotated with emotional labels. This dataset is designed to evaluate a model's ability to understand emotions in realistic, contextual scenarios, going beyond simple text-based emotion recognition.
The authors then propose a VLLM-based architecture for the CER task. The model takes an image and accompanying text as input and outputs a probability distribution over emotional categories (e.g., happy, sad, angry). The key innovation is the use of a VLLM backbone, such as CLIP or ALBEF, which allows the model to leverage rich multimodal representations and common sense reasoning.
Experiments on the CER dataset show that the VLLM-based model significantly outperforms text-only baselines, demonstrating the value of multimodal understanding for emotion recognition. The authors also conduct ablation studies to analyze the contribution of different components, such as the vision and language encoders, to the overall performance.
Critical Analysis
The paper makes a compelling case for the benefits of VLLMs in emotion recognition tasks, but there are a few potential limitations and areas for further research:
-
The CER dataset, while a valuable contribution, may not capture the full complexity of real-world emotional contexts. More diverse and challenging datasets may be needed to further stress-test the capabilities of VLLM-based models.
-
The paper does not explore the interpretability of the VLLM-based model's emotion recognition process. It would be interesting to understand how the model is leveraging visual and textual cues to arrive at its predictions, which could lead to more transparent and explainable AI systems.
-
The evaluation focuses on emotion recognition accuracy, but there may be other important metrics to consider, such as the model's ability to handle out-of-distribution samples or generate relevant and engaging image captions.
Overall, this research represents an important step forward in leveraging the power of VLLMs for more contextual and empathetic artificial intelligence. However, as with any emerging technology, there is still room for further exploration and refinement.
Conclusion
This paper demonstrates that Vision-Language Large Models (VLLMs) can provide superior context for understanding human emotions through common sense reasoning. By jointly processing visual and textual information, VLLMs are able to recognize emotions in complex, real-world scenarios more accurately than text-only models.
The proposed VLLM-based architecture and the new Contextual Emotion Recognition (CER) benchmark dataset represent valuable contributions to the field of emotional intelligence in AI. These findings have implications for building more socially aware and empathetic artificial systems that can better understand and respond to human emotions.
As the capabilities of VLLMs continue to evolve, further research in this direction could lead to significant advancements in areas like human-AI interaction, mental health support, and personalized digital assistants. Overall, this work highlights the potential of multimodal reasoning for developing AI that is more attuned to the nuanced nature of human experience.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
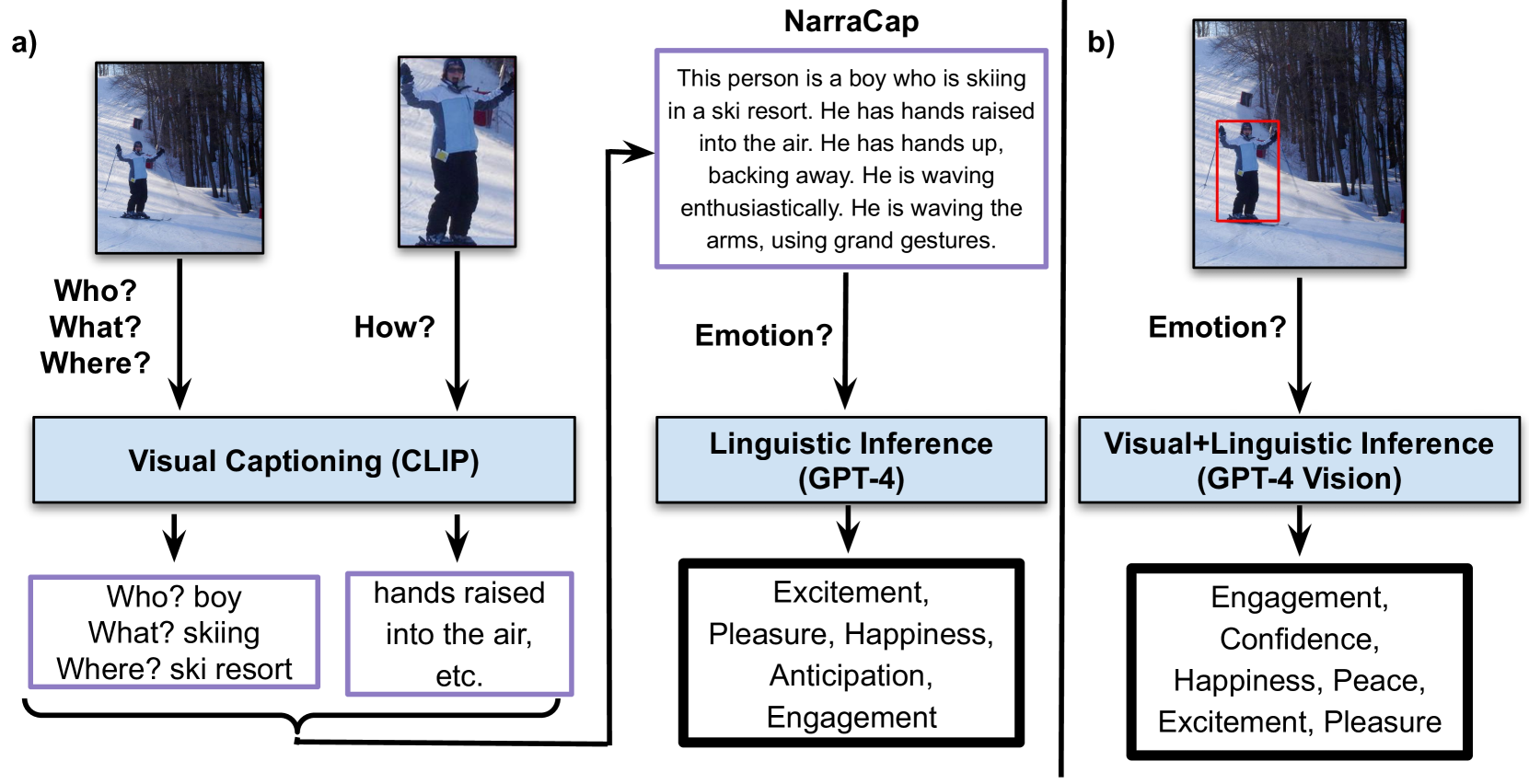
Contextual Emotion Recognition using Large Vision Language Models
Yasaman Etesam, Ozge Nilay Yalc{c}{i}n, Chuxuan Zhang, Angelica Lim
0
0
How does the person in the bounding box feel? Achieving human-level recognition of the apparent emotion of a person in real world situations remains an unsolved task in computer vision. Facial expressions are not enough: body pose, contextual knowledge, and commonsense reasoning all contribute to how humans perform this emotional theory of mind task. In this paper, we examine two major approaches enabled by recent large vision language models: 1) image captioning followed by a language-only LLM, and 2) vision language models, under zero-shot and fine-tuned setups. We evaluate the methods on the Emotions in Context (EMOTIC) dataset and demonstrate that a vision language model, fine-tuned even on a small dataset, can significantly outperform traditional baselines. The results of this work aim to help robots and agents perform emotionally sensitive decision-making and interaction in the future.
5/16/2024
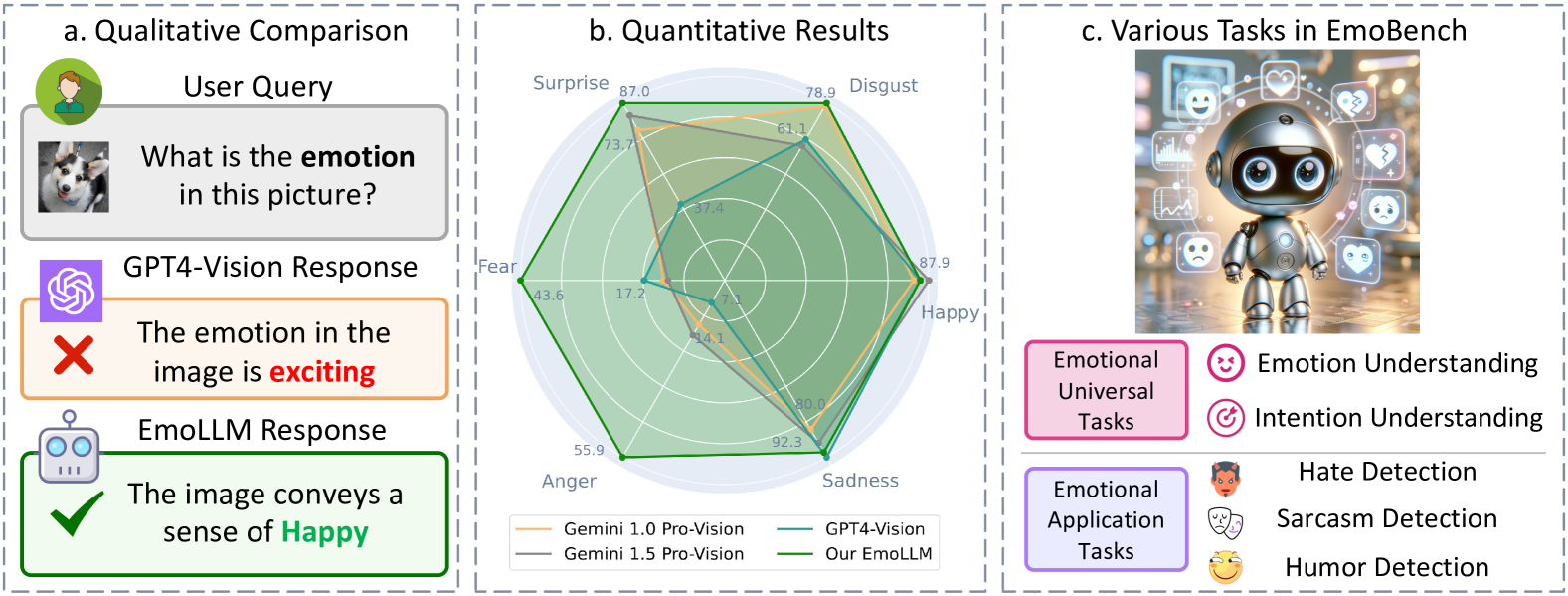
EmoLLM: Multimodal Emotional Understanding Meets Large Language Models
Qu Yang, Mang Ye, Bo Du
0
0
Multi-modal large language models (MLLMs) have achieved remarkable performance on objective multimodal perception tasks, but their ability to interpret subjective, emotionally nuanced multimodal content remains largely unexplored. Thus, it impedes their ability to effectively understand and react to the intricate emotions expressed by humans through multimodal media. To bridge this gap, we introduce EmoBench, the first comprehensive benchmark designed specifically to evaluate the emotional capabilities of MLLMs across five popular emotional tasks, using a diverse dataset of 287k images and videos paired with corresponding textual instructions. Meanwhile, we propose EmoLLM, a novel model for multimodal emotional understanding, incorporating with two core techniques. 1) Multi-perspective Visual Projection, it captures diverse emotional cues from visual data from multiple perspectives. 2) EmoPrompt, it guides MLLMs to reason about emotions in the correct direction. Experimental results demonstrate that EmoLLM significantly elevates multimodal emotional understanding performance, with an average improvement of 12.1% across multiple foundation models on EmoBench. Our work contributes to the advancement of MLLMs by facilitating a deeper and more nuanced comprehension of intricate human emotions, paving the way for the development of artificial emotional intelligence capabilities with wide-ranging applications in areas such as human-computer interaction, mental health support, and empathetic AI systems. Code, data, and model will be released.
6/26/2024
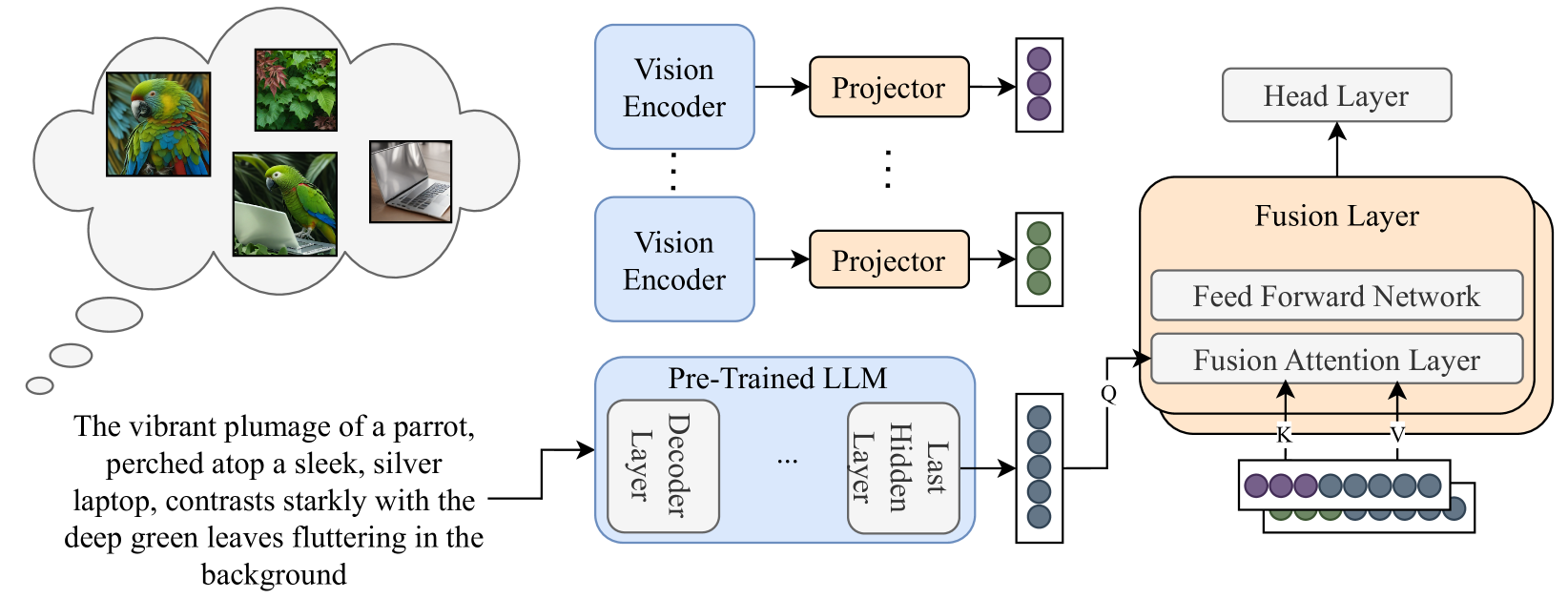
Improving Visual Commonsense in Language Models via Multiple Image Generation
Guy Yariv, Idan Schwartz, Yossi Adi, Sagie Benaim
0
0
Commonsense reasoning is fundamentally based on multimodal knowledge. However, existing large language models (LLMs) are primarily trained using textual data only, limiting their ability to incorporate essential visual information. In contrast, Visual Language Models, which excel at visually-oriented tasks, often fail at non-visual tasks such as basic commonsense reasoning. This divergence highlights a critical challenge - the integration of robust visual understanding with foundational text-based language reasoning. To this end, we introduce a method aimed at enhancing LLMs' visual commonsense. Specifically, our method generates multiple images based on the input text prompt and integrates these into the model's decision-making process by mixing their prediction probabilities. To facilitate multimodal grounded language modeling, we employ a late-fusion layer that combines the projected visual features with the output of a pre-trained LLM conditioned on text only. This late-fusion layer enables predictions based on comprehensive image-text knowledge as well as text only when this is required. We evaluate our approach using several visual commonsense reasoning tasks together with traditional NLP tasks, including common sense reasoning and reading comprehension. Our experimental results demonstrate significant superiority over existing baselines. When applied to recent state-of-the-art LLMs (e.g., Llama3), we observe improvements not only in visual common sense but also in traditional NLP benchmarks. Code and models are available under https://github.com/guyyariv/vLMIG.
6/21/2024
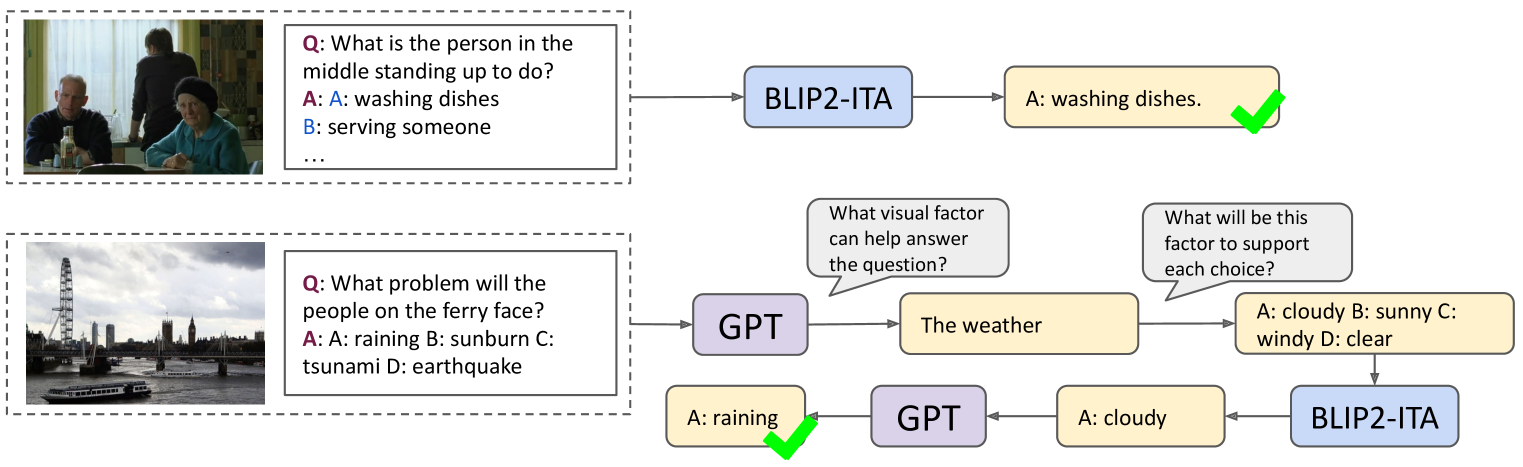
ViCor: Bridging Visual Understanding and Commonsense Reasoning with Large Language Models
Kaiwen Zhou, Kwonjoon Lee, Teruhisa Misu, Xin Eric Wang
0
0
In our work, we explore the synergistic capabilities of pre-trained vision-and-language models (VLMs) and large language models (LLMs) on visual commonsense reasoning (VCR) problems. We find that VLMs and LLMs-based decision pipelines are good at different kinds of VCR problems. Pre-trained VLMs exhibit strong performance for problems involving understanding the literal visual content, which we noted as visual commonsense understanding (VCU). For problems where the goal is to infer conclusions beyond image content, which we noted as visual commonsense inference (VCI), VLMs face difficulties, while LLMs, given sufficient visual evidence, can use commonsense to infer the answer well. We empirically validate this by letting LLMs classify VCR problems into these two categories and show the significant difference between VLM and LLM with image caption decision pipelines on two subproblems. Moreover, we identify a challenge with VLMs' passive perception, which may miss crucial context information, leading to incorrect reasoning by LLMs. Based on these, we suggest a collaborative approach, named ViCor, where pre-trained LLMs serve as problem classifiers to analyze the problem category, then either use VLMs to answer the question directly or actively instruct VLMs to concentrate on and gather relevant visual elements to support potential commonsense inferences. We evaluate our framework on two VCR benchmark datasets and outperform all other methods that do not require in-domain fine-tuning.
5/20/2024