Improving Word Translation via Two-Stage Contrastive Learning

0
🏅
Sign in to get full access
Overview
- This paper proposes a two-stage contrastive learning framework for the task of bilingual lexicon induction (BLI), which aims to bridge the lexical gap between different languages.
- In the first stage (C1), the researchers refine standard cross-lingual linear maps between static word embeddings using a contrastive learning objective, and integrate this into a self-learning procedure for even more refined cross-lingual maps.
- In the second stage (C2), they conduct BLI-oriented contrastive fine-tuning of the multilingual BERT (mBERT) model, unlocking its word translation capability. They also show that the static word embeddings induced from the 'C2-tuned' mBERT complement the static word embeddings from Stage C1.
- Comprehensive experiments on standard BLI datasets for diverse languages and different experimental setups demonstrate substantial gains achieved by their framework.
Plain English Explanation
The paper focuses on the challenge of word translation or bilingual lexicon induction (BLI), which is the task of bridging the gap between the vocabularies of different languages. To address this, the researchers propose a two-stage approach.
In the first stage, they take standard methods for aligning word embeddings (representations of words) across languages and refine them using a contrastive learning objective. This helps the word embeddings better capture the relationships between words in different languages. They also integrate this contrastive learning approach into a self-learning procedure, which further improves the cross-lingual alignment of the word embeddings.
In the second stage, the researchers fine-tune the multilingual BERT (mBERT) language model using a contrastive learning objective tailored to the BLI task. This 'BLI-oriented' fine-tuning unlocks mBERT's ability to translate words between languages. They also show that the static word embeddings obtained from this fine-tuned mBERT model can be used alongside the word embeddings from the first stage to achieve even better performance on the BLI task.
Through extensive experiments on standard BLI datasets covering a diverse set of languages, the researchers demonstrate that their two-stage framework leads to substantial improvements over previous state-of-the-art methods.
Technical Explanation
The key elements of the paper are as follows:
-
Stage C1: Contrastive Refinement of Cross-Lingual Word Embeddings
- The researchers start with standard cross-lingual linear maps between static word embeddings.
- They propose a contrastive learning objective to refine these cross-lingual maps, encouraging aligned word pairs to be closer in the embedding space while pushing unaligned pairs apart.
- They also integrate this contrastive learning approach into a self-learning procedure for even more refined cross-lingual maps.
-
Stage C2: BLI-Oriented Contrastive Fine-Tuning of mBERT
- In this stage, the researchers conduct contrastive fine-tuning of the multilingual BERT (mBERT) model, specifically tailored to the BLI task.
- This BLI-oriented fine-tuning unlocks mBERT's word translation capability, allowing it to effectively bridge the lexical gap between languages.
- They also show that the static word embeddings induced from the 'C2-tuned' mBERT model complement the static word embeddings from Stage C1, leading to further improvements in BLI performance.
-
Comprehensive Experiments and Results
- The researchers evaluate their two-stage framework on standard BLI datasets covering a diverse set of language pairs.
- They compare their approach to a range of state-of-the-art BLI methods and report substantial gains for 112 out of 112 BLI setups, spanning 28 language pairs.
- The method from Stage C1 alone already outperforms all previous state-of-the-art BLI methods, and the full two-stage framework achieves even stronger improvements.
Critical Analysis
The paper presents a robust and effective framework for the BLI task, with several noteworthy aspects:
- The two-stage approach leverages both refined static word embeddings and fine-tuned contextual representations (mBERT), leading to complementary benefits.
- The contrastive learning objectives used in both stages are well-motivated and shown to be effective for improving cross-lingual alignment.
- The extensive experiments cover a diverse range of languages and experimental setups, demonstrating the broad applicability and strong performance of the proposed approach.
However, the paper does not address certain limitations or potential concerns:
- The fine-tuning of mBERT may require significant computational resources and a large amount of training data, which could limit the practical applicability of the approach, especially for low-resource languages.
- The paper does not provide a detailed analysis of the learned cross-lingual representations or the types of word pairs that are most effectively aligned by the framework.
- The long-term stability and generalization of the learned cross-lingual mappings are not thoroughly investigated, which could be important for real-world deployment.
Overall, the proposed two-stage contrastive learning framework represents a significant advancement in the field of bilingual lexicon induction, with the potential to enable more effective cross-lingual alignment and understanding. Further research to address the identified limitations and explore the broader implications of this work would be valuable.
Conclusion
This paper introduces a novel two-stage contrastive learning framework for the task of bilingual lexicon induction (BLI), which aims to bridge the lexical gap between different languages. The key innovations are the refinement of cross-lingual word embeddings using a contrastive learning objective (Stage C1) and the BLI-oriented fine-tuning of the multilingual BERT (mBERT) model (Stage C2).
The proposed approach demonstrates substantial improvements over previous state-of-the-art BLI methods, as validated through comprehensive experiments on diverse language pairs. This work represents a significant advancement in the field of cross-lingual alignment and understanding, with potential applications in machine translation, multilingual information retrieval, and other cross-lingual tasks. Further research to address the identified limitations and explore the broader implications of this work would be valuable contributions to the ongoing efforts in this important area of natural language processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
Improving Word Translation via Two-Stage Contrastive Learning
Yaoyiran Li, Fangyu Liu, Nigel Collier, Anna Korhonen, Ivan Vuli'c
Word translation or bilingual lexicon induction (BLI) is a key cross-lingual task, aiming to bridge the lexical gap between different languages. In this work, we propose a robust and effective two-stage contrastive learning framework for the BLI task. At Stage C1, we propose to refine standard cross-lingual linear maps between static word embeddings (WEs) via a contrastive learning objective; we also show how to integrate it into the self-learning procedure for even more refined cross-lingual maps. In Stage C2, we conduct BLI-oriented contrastive fine-tuning of mBERT, unlocking its word translation capability. We also show that static WEs induced from the `C2-tuned' mBERT complement static WEs from Stage C1. Comprehensive experiments on standard BLI datasets for diverse languages and different experimental setups demonstrate substantial gains achieved by our framework. While the BLI method from Stage C1 already yields substantial gains over all state-of-the-art BLI methods in our comparison, even stronger improvements are met with the full two-stage framework: e.g., we report gains for 112/112 BLI setups, spanning 28 language pairs.
Read more7/2/2024

0
How Lexical is Bilingual Lexicon Induction?
Harsh Kohli, Helian Feng, Nicholas Dronen, Calvin McCarter, Sina Moeini, Ali Kebarighotbi
In contemporary machine learning approaches to bilingual lexicon induction (BLI), a model learns a mapping between the embedding spaces of a language pair. Recently, retrieve-and-rank approach to BLI has achieved state of the art results on the task. However, the problem remains challenging in low-resource settings, due to the paucity of data. The task is complicated by factors such as lexical variation across languages. We argue that the incorporation of additional lexical information into the recent retrieve-and-rank approach should improve lexicon induction. We demonstrate the efficacy of our proposed approach on XLING, improving over the previous state of the art by an average of 2% across all language pairs.
Read more4/8/2024
0
Improving Multi-lingual Alignment Through Soft Contrastive Learning
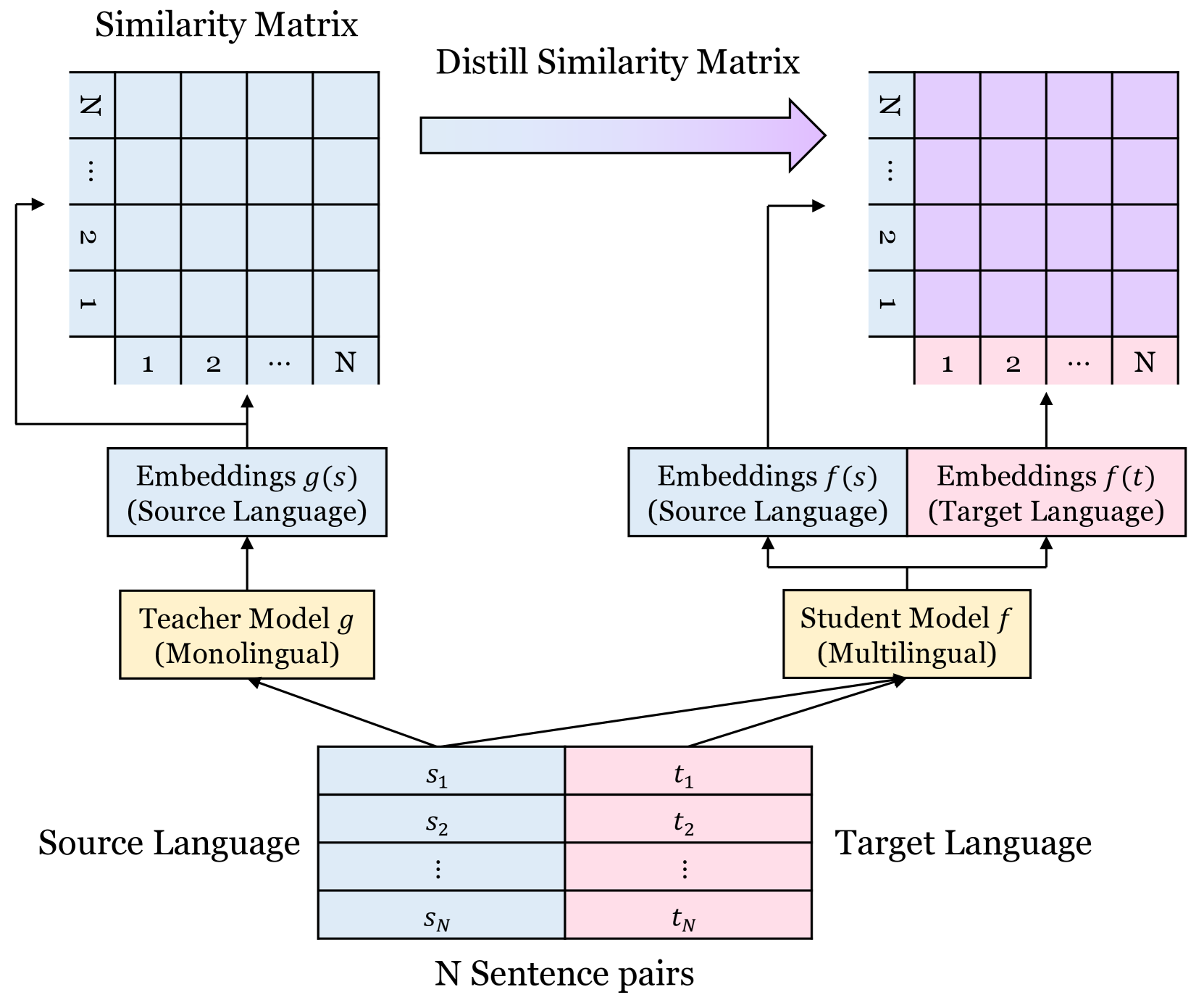
Minsu Park, Seyeon Choi, Chanyeol Choi, Jun-Seong Kim, Jy-yong Sohn
Making decent multi-lingual sentence representations is critical to achieve high performances in cross-lingual downstream tasks. In this work, we propose a novel method to align multi-lingual embeddings based on the similarity of sentences measured by a pre-trained mono-lingual embedding model. Given translation sentence pairs, we train a multi-lingual model in a way that the similarity between cross-lingual embeddings follows the similarity of sentences measured at the mono-lingual teacher model. Our method can be considered as contrastive learning with soft labels defined as the similarity between sentences. Our experimental results on five languages show that our contrastive loss with soft labels far outperforms conventional contrastive loss with hard labels in various benchmarks for bitext mining tasks and STS tasks. In addition, our method outperforms existing multi-lingual embeddings including LaBSE, for Tatoeba dataset. The code is available at https://github.com/YAI12xLinq-B/IMASCL
Read more5/29/2024
🤷
0
Self-Augmented In-Context Learning for Unsupervised Word Translation
Yaoyiran Li, Anna Korhonen, Ivan Vuli'c
Recent work has shown that, while large language models (LLMs) demonstrate strong word translation or bilingual lexicon induction (BLI) capabilities in few-shot setups, they still cannot match the performance of 'traditional' mapping-based approaches in the unsupervised scenario where no seed translation pairs are available, especially for lower-resource languages. To address this challenge with LLMs, we propose self-augmented in-context learning (SAIL) for unsupervised BLI: starting from a zero-shot prompt, SAIL iteratively induces a set of high-confidence word translation pairs for in-context learning (ICL) from an LLM, which it then reapplies to the same LLM in the ICL fashion. Our method shows substantial gains over zero-shot prompting of LLMs on two established BLI benchmarks spanning a wide range of language pairs, also outperforming mapping-based baselines across the board. In addition to achieving state-of-the-art unsupervised BLI performance, we also conduct comprehensive analyses on SAIL and discuss its limitations.
Read more6/6/2024